JUICER: Data-Efficient Imitation Learning for Robotic Assembly
作者: Lars Ankile, Anthony Simeonov, Idan Shenfeld, Pulkit Agrawal
分类: cs.RO, cs.LG
发布日期: 2024-04-04 (更新: 2024-11-11)
备注: Published at IROS 2024. Project website: https://imitation-juicer.github.io/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出JUICER以解决机器人装配中的数据效率问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 模仿学习 机器人装配 数据增强 深度学习 视觉运动策略
📋 核心要点
- 现有的模仿学习方法在长时间精确操作任务中依赖于大量演示数据,限制了其应用。
- 本文提出了一种新的管道,通过结合多种技术来扩展数据集并增强模型的学习能力,减少对大量演示的依赖。
- 在四个家具装配任务的仿真实验中,所提方法使得操控器在近2500个时间步内成功组装多个部件,超越了现有基线。
📝 摘要(中文)
在学习演示中,尽管能够有效获取视觉运动策略,但在需要精确、长时间操作的任务中,高性能模仿学习仍面临挑战。本文提出了一种改进模仿学习性能的管道,旨在使用有限的人类演示预算来提升学习效果。我们将该方法应用于需要精确抓取、重新定向和插入多个部件的装配任务。该管道结合了表现力强的策略架构和多种数据集扩展及基于仿真的数据增强技术,帮助扩展数据集支持并在需要高精度的瓶颈区域监督模型。我们在四个家具装配任务的仿真中展示了该管道,使得操控器能够直接从RGB图像中组装多达五个部件,超过了模仿和数据增强基线的表现。
🔬 方法详解
问题定义:本文旨在解决在长时间精确操作任务中模仿学习对大量演示数据的依赖问题。现有方法在处理复杂的装配任务时,往往无法在有限的数据下实现高性能。
核心思路:论文提出的核心思路是通过结合表现力强的策略架构与数据集扩展和仿真数据增强技术,来提升模仿学习的效果。这种设计旨在在数据有限的情况下,仍能有效学习到高精度的操作策略。
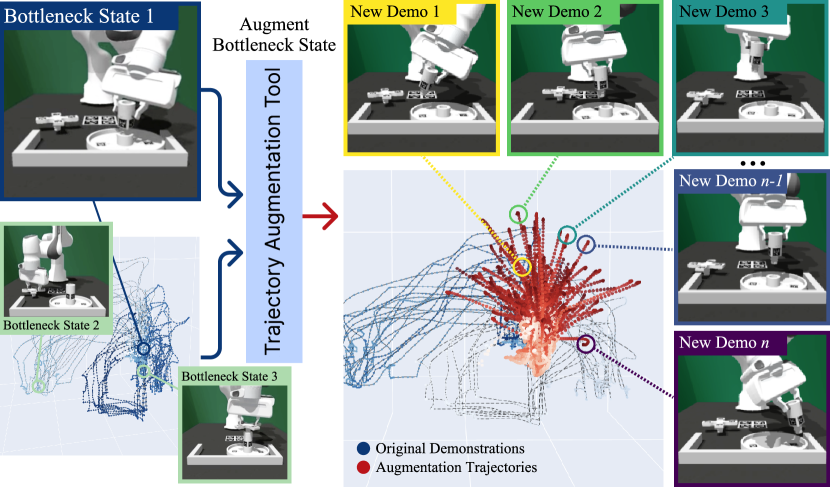
技术框架:整体架构包括数据集扩展模块、仿真数据增强模块和策略学习模块。数据集扩展通过生成新的样本来增加训练数据,而仿真数据增强则通过模拟环境中的局部纠正动作来提高模型的精度。
关键创新:最重要的创新点在于通过局部纠正动作来监督模型,尤其是在高精度要求的瓶颈区域。这种方法与传统的模仿学习方法相比,显著提升了在数据稀缺情况下的学习效果。
关键设计:在参数设置上,采用了适应性损失函数以平衡不同任务阶段的学习需求。同时,网络结构设计上使用了深度卷积神经网络,以提高对RGB图像的特征提取能力。
🖼️ 关键图片


📊 实验亮点
在实验中,所提出的JUICER管道在四个家具装配任务中表现优异,能够在近2500个时间步内成功组装多达五个部件,超越了传统模仿学习和数据增强基线,显示出显著的性能提升。
🎯 应用场景
该研究的潜在应用领域包括机器人装配、自动化制造和智能家居等。通过提升模仿学习的效率,能够在减少人力成本的同时,提高机器人在复杂任务中的操作精度,具有重要的实际价值和广泛的应用前景。
📄 摘要(原文)
While learning from demonstrations is powerful for acquiring visuomotor policies, high-performance imitation without large demonstration datasets remains challenging for tasks requiring precise, long-horizon manipulation. This paper proposes a pipeline for improving imitation learning performance with a small human demonstration budget. We apply our approach to assembly tasks that require precisely grasping, reorienting, and inserting multiple parts over long horizons and multiple task phases. Our pipeline combines expressive policy architectures and various techniques for dataset expansion and simulation-based data augmentation. These help expand dataset support and supervise the model with locally corrective actions near bottleneck regions requiring high precision. We demonstrate our pipeline on four furniture assembly tasks in simulation, enabling a manipulator to assemble up to five parts over nearly 2500 time steps directly from RGB images, outperforming imitation and data augmentation baselines. Project website: https://imitation-juicer.github.io/.