Statistical Embeddings for Similarity, Retrieval, and Interpretable Alignment of Numeric Tabular Datasets
作者: M. Ross Kunz, John Merickel, Keith Wilson
分类: cs.LG, stat.AP, stat.ML
发布日期: 2026-05-28
💡 一句话要点
提出一种基于统计嵌入的表格数据相似性、检索和可解释对齐方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表格数据 相似性度量 数据检索 可解释性 典型相关分析 差分隐私 统计嵌入
📋 核心要点
- 现有方法在处理异构数值表格数据时,要么依赖共享变量定义进行预测建模,要么缺乏可解释的跨数据集对齐机制。
- 该方法通过结构化探索性数据分析描述符表征数据集,并利用预训练句子转换器嵌入到共享向量空间,实现跨数据集相似性量化。
- 实验结果表明,该方法在数据集检索任务中表现出色,P@1得分为0.9,且在差分隐私设置下仍保持稳健。
📝 摘要(中文)
数值表格数据集是科学实践中的主要数据格式,但大型语言模型缺乏以有意义的方式跨异构特征空间表示数值数据集的固有机制。现有方法要么针对单个数据集的预测建模,这需要一组共享的变量定义,要么缺乏可解释的跨数据集对齐机制。本文提出了一种方法,通过结构化的探索性数据分析描述符来表征数值表格数据集,使用预训练的句子转换器将这些描述符嵌入到共享向量空间中,并通过典型相关分析(CCA)量化跨数据集相似性。此外,应用惩罚形式的CCA来恢复数据集之间稀疏的、可解释的变量级对应关系,识别驱动跨数据集对齐的统计描述符或变量级量,而无需共享变量名或特征约定。可以选择在嵌入之前将差分隐私应用于描述符集,从而支持在敏感数据环境中部署,而无需在比较时访问原始观测值。该方法在涵盖通用基准、材料信息学和核级石墨表征的15个数据集上进行了评估。结果表明,P@1得分为0.9,已知的最近邻检索和聚类结构在嵌入消融和差分隐私预算中保持稳健。所提出的框架为将异构数值数据集成到检索增强生成管道中提供了一种原则性途径,同时保留了统计上下文,可直接应用于未知数据集的数据驱动算法选择和模拟模型初始化。
🔬 方法详解
问题定义:现有方法难以有效处理异构数值表格数据集,尤其是在缺乏共享变量定义的情况下,无法实现跨数据集的相似性比较和可解释的对齐。这限制了数据驱动的算法选择和模型初始化等应用。
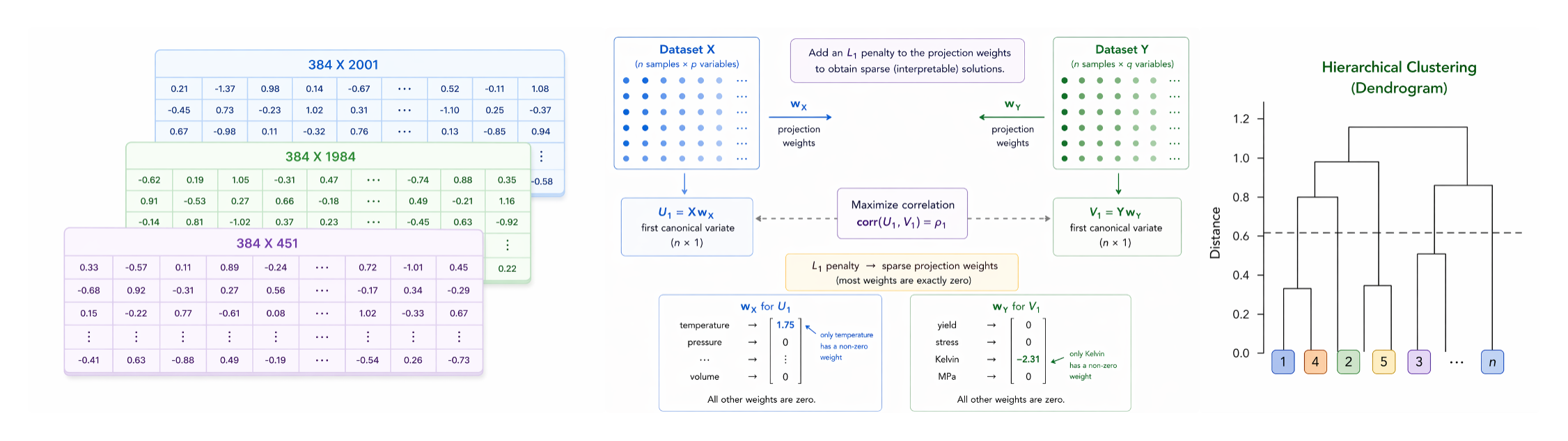
核心思路:核心思路是将数值表格数据集转化为一组统计描述符,然后将这些描述符嵌入到一个共享的向量空间中。通过在这个共享空间中进行相似性比较,可以克服异构特征空间带来的挑战,并实现跨数据集的对齐。
技术框架:该方法包含以下几个主要阶段:1) 数据集描述:使用结构化的探索性数据分析方法提取数据集的统计描述符。2) 嵌入:利用预训练的句子转换器将这些描述符嵌入到共享向量空间中。3) 相似性量化:使用典型相关分析(CCA)计算跨数据集的相似性。4) 可解释对齐:应用惩罚形式的CCA来识别驱动跨数据集对齐的关键变量。5) 差分隐私(可选):在嵌入之前应用差分隐私保护数据集的敏感信息。
关键创新:该方法最重要的创新点在于它提供了一种无需共享变量名或特征约定即可实现跨异构数值表格数据集的可解释对齐的框架。通过将数据集转化为统计描述符并嵌入到共享向量空间中,该方法能够有效地比较和对齐具有不同特征空间的数据集。
关键设计:关键设计包括:1) 统计描述符的选择,需要能够全面表征数据集的统计特征。2) 预训练句子转换器的选择,需要能够有效地将统计描述符嵌入到共享向量空间中。3) CCA的惩罚项设计,用于实现稀疏且可解释的变量级对应关系。4) 差分隐私预算的选择,需要在隐私保护和模型性能之间进行权衡。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在15个数据集上取得了显著的成果,P@1得分为0.9,表明该方法能够准确地检索到已知最近邻。此外,即使在应用差分隐私的情况下,该方法的性能仍然保持稳健,表明其在保护数据隐私的同时,仍然能够有效地进行数据集相似性比较和对齐。
🎯 应用场景
该研究成果可应用于多个领域,包括数据驱动的算法选择、模拟模型初始化、材料信息学和生物信息学等。例如,可以根据未知数据集的统计特征,自动选择最合适的算法或初始化模拟模型,从而提高效率和准确性。此外,该方法在处理敏感数据时,可以通过差分隐私保护用户隐私。
📄 摘要(原文)
Numeric tabular datasets are the dominant data format in scientific practice, yet large language models lack native mechanisms for representing numeric datasets in a meaningful way across heterogeneous feature spaces. Existing approaches either target predictive modeling over individual datasets, which requires a shared set of variable definitions, or lack mechanisms for interpretable cross-dataset alignment. The proposed methodology characterizes numeric tabular datasets through structured exploratory data analysis descriptors, embeds those descriptors into a shared vector space using a pretrained sentence transformer, and quantifies cross-dataset similarity via Canonical Correlation Analysis (CCA). Furthermore, a penalized formulation of CCA is applied to recover sparse, interpretable variable-level correspondences between datasets, identifying which statistical descriptors or variable-level quantities drive cross-dataset alignment without requiring shared variable names or feature conventions. Differential privacy is optionally applied to the descriptor set prior to embedding, supporting deployment in sensitive data contexts without requiring access to raw observations at time of comparison. The methodology is evaluated across 15 datasets spanning general-purpose benchmarks, materials informatics, and nuclear-grade graphite characterization. Results demonstrate a total P@1 score of 0.9, with known nearest-neighbor retrieval and cluster structure remaining robust across embedding ablations and differential privacy budgets. The proposed framework provides a principled pathway for integrating heterogeneous numeric data into retrieval-augmented generation pipelines while preserving statistical context, with direct applications to data-driven algorithm selection and simulation model initialization for unknown datasets.