Adaptive Negative Reinforcement for LLM Reasoning:Dynamically Balancing Correction and Diversity in RLVR
作者: Yash Ingle, Jaival Chauhan, Ankit Yadav, Sudhakar Mishra
分类: cs.LG, cs.AI
发布日期: 2026-05-08
💡 一句话要点
提出自适应负强化学习(A-NSR)框架,通过动态惩罚策略提升LLM推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 强化学习 推理能力 负样本强化 可验证奖励 模型训练优化
📋 核心要点
- 现有NSR方法在训练过程中使用固定惩罚策略,且无法区分不同错误类型的重要性,导致模型训练效率受限。
- 提出A-NSR框架,通过时间调度函数动态调整纠错强度,并结合置信度加权机制,实现对错误样本的差异化惩罚。
- 在MATH等复杂推理数据集上的实验表明,该方法有效提升了模型推理性能,并增强了对过拟合的防御能力。
📝 摘要(中文)
带有可验证奖励的强化学习(RLVR)已成为提升大语言模型(LLM)推理能力的关键方法。近期研究表明,负样本强化(NSR)通过惩罚错误步骤而非仅奖励正确步骤,在Pass@k指标上可媲美甚至超越PPO和GRPO等复杂框架。然而,现有NSR技术通常采用固定的惩罚机制,且对所有错误响应一视同仁。为此,本文提出了自适应负样本强化(A-NSR)框架。该框架引入了时间依赖的调度函数,在训练初期侧重纠错以稳定模型,后期则转向更精细的更新。此外,引入了置信度加权负强化(CW-NSR),根据模型序列似然度动态分配惩罚权重,对高置信度的错误施加重罚,对探索性错误则减轻惩罚。实验在MATH、AIME 2025及AMC23数据集上验证了该方法在Qwen2.5-Math-1.5B架构上的有效性。
🔬 方法详解
问题定义:现有负样本强化(NSR)方法在训练过程中缺乏动态性,统一的惩罚权重无法区分“模型确定性错误”与“探索性错误”,导致模型在训练后期难以平衡纠错与多样性,限制了推理能力的进一步提升。
核心思路:论文的核心在于引入“自适应”机制,将静态惩罚转化为动态过程。通过时间调度函数控制训练节奏,并利用模型自身的置信度(序列似然)作为权重因子,实现对错误样本的精细化管理,从而优化模型对推理路径的概率分布。
技术框架:该方法在RLVR框架基础上扩展,包含两个核心模块:一是时间依赖调度器,用于在训练不同阶段动态调整惩罚强度;二是置信度加权模块,根据模型输出的归一化序列似然度计算惩罚权重,将惩罚力度与模型对错误路径的自信程度挂钩。
关键创新:最重要的创新在于将“惩罚”这一动作从全局统一转变为局部自适应。通过CW-NSR机制,模型能够识别并严惩那些“自以为是”的错误,同时保留对不确定性探索的容忍度,从而在纠错与探索之间取得最优平衡。
关键设计:关键技术细节包括基于时间步的惩罚衰减函数,以及基于模型归一化序列似然的权重计算公式。这些机制共同作用于token级别的概率更新,通过 prior-guided 概率重分配,在提升推理准确率的同时,有效抑制了模型在复杂推理任务中的过拟合现象。
🖼️ 关键图片
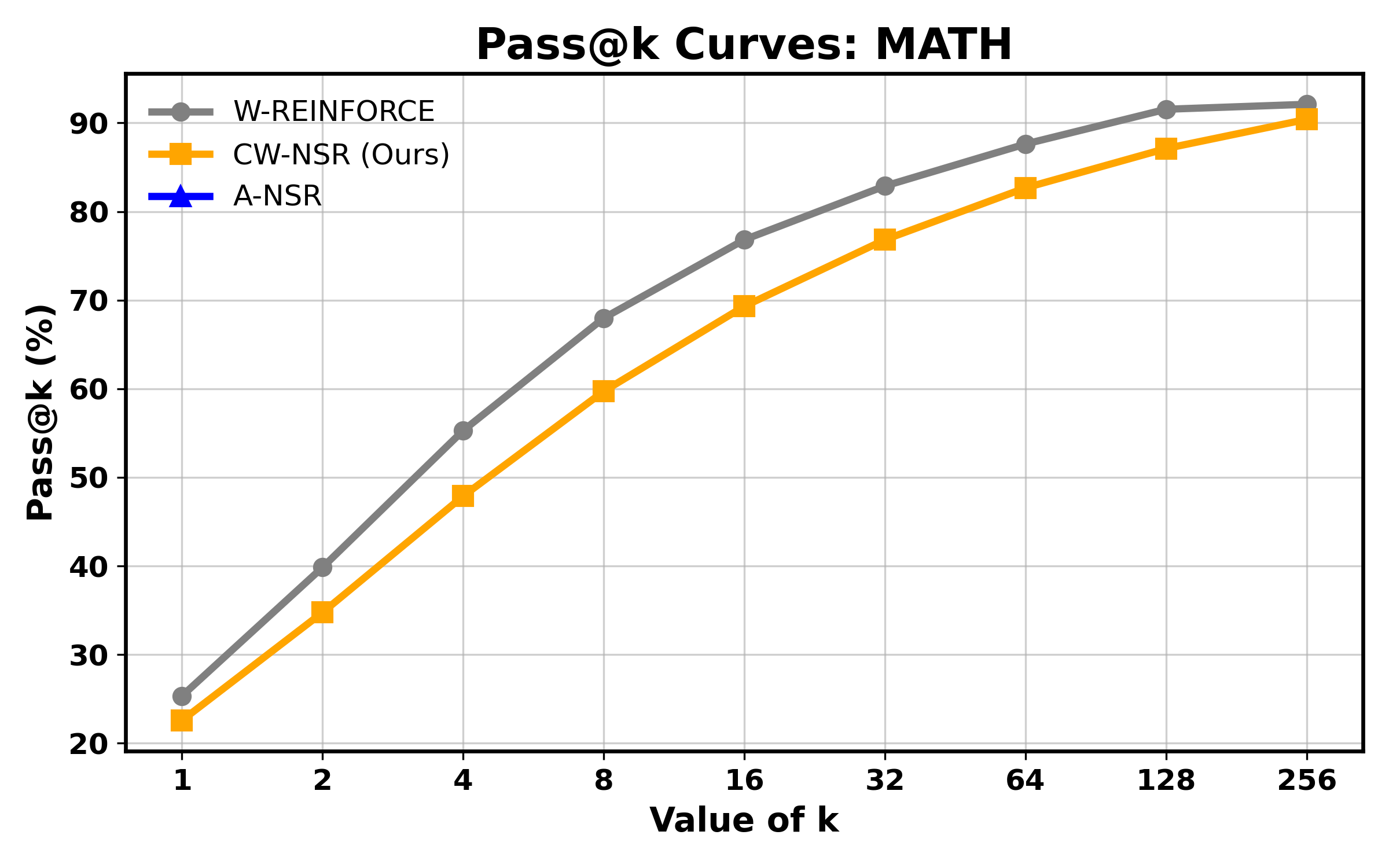


📊 实验亮点
实验在Qwen2.5-Math-1.5B架构上进行,涵盖MATH、AIME 2025及AMC23等高难度推理基准。结果显示,A-NSR与CW-NSR机制显著优于传统的固定惩罚NSR方法,在保持计算效率的同时,通过差异化惩罚策略有效提升了Pass@k指标,并展现出更强的泛化能力与抗过拟合特性。
🎯 应用场景
该研究主要应用于大语言模型的推理能力增强,特别是在数学、逻辑推理及代码生成等需要严谨步骤验证的领域。其动态惩罚机制可广泛集成于各类RLVR训练流程中,为构建更高效、鲁棒的推理模型提供技术支撑,具有极高的学术研究价值与工业落地潜力。
📄 摘要(原文)
Reinforcement learning with verifiable rewards (RLVR) has become a highly effective method for improving the reasoning abilities of Large Language Models (LLMs). Recent research shows that Negative Sample Reinforcement (NSR) -- which focuses on penalizing incorrect steps rather than simply rewarding correct ones -- can match or even exceed the performance of more complex frameworks like PPO and GRPO across the entire Pass@k spectrum. However, current NSR techniques usually apply a fixed penalty throughout the training process and treat every incorrect response with the same weight. To address these limitations, we propose two extensions to the NSR framework: Adaptive Negative Sample Reinforcement. Rather than using a fixed update rule, A-NSR uses time-dependent scheduling functions. In the initial training phases, the system focuses heavily on correcting errors to stabilize the model. As training continues, it shifts toward more subtle and controlled updates. We also introduce Confidence-Weighted Negative Reinforcement, which operates on the principle that different mistakes carry different levels of importance. CW-NSR assigns specific penalty weights based on the model's normalized sequence likelihood. If the model is highly confident in a wrong path, it receives a larger penalty and for uncertain errors -- where the model is effectively exploring -- are penalized less strictly. Our formal analysis shows how these mechanisms govern token-level updates, allowing the model to leverage prior-guided probability redistribution while providing a natural defense against overfitting. We evaluated these methods on difficult reasoning datasets, including MATH, AIME 2025, and AMC23, using the Qwen2.5-Math-1.5B architecture.