InfoTok: Information-Theoretic Regularization for Capacity-Constrained Shared Visual Tokenization in Unified MLLMs
作者: Lv Tang, Tianyi Zheng, Bo Li, Xingyu Li
分类: cs.LG, cs.AI, cs.CV
发布日期: 2026-04-07
💡 一句话要点
InfoTok:面向统一多模态大语言模型,提出信息论正则化的容量约束共享视觉Token化方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉Token化 信息瓶颈 互信息 信息论正则化
📋 核心要点
- 现有统一MLLM的共享视觉Token器设计缺乏明确的信息保留标准,难以兼顾语义抽象和视觉细节。
- InfoTok通过信息瓶颈原理,显式控制图像到Token再到输出的信息流,在压缩和任务相关性间取得平衡。
- 实验表明,InfoTok在不引入额外训练数据的情况下,持续提升了图像理解和生成性能。
📝 摘要(中文)
统一多模态大语言模型(MLLM)旨在将图像理解和图像生成统一在单个框架内,其中共享视觉Token器作为唯一的接口,将高维图像映射到有限的Token预算中,以供下游多模态推理和合成。然而,现有的共享Token设计在很大程度上是架构驱动的,缺乏明确的标准来确定应该保留哪些信息,以同时支持语义抽象和视觉细节。本文采用容量约束的视角,将共享Token器视为一个计算受限的学习器,其有限的表示预算应优先考虑可重用的结构,而不是难以利用的高熵变化和冗余。受此观点的启发,我们提出了 extbf{ extit{InfoTok}},一种基于信息瓶颈(IB)原理的信息正则化Token化机制。InfoTok通过施加互信息(MI)约束来显式控制从图像到共享Token再到多模态输出的信息流,从而在压缩和任务相关性之间强制执行有原则的权衡,同时鼓励跨模态一致性。由于MI对于高维视觉表示是难以处理的,我们使用实用的、可微的依赖估计器来实例化InfoTok,包括变分IB公式和基于Hilbert Schmidt独立性准则(HSIC)的替代方案。集成到三个具有代表性的统一MLLM中,无需引入任何额外的训练数据,InfoTok始终提高图像理解和生成性能。这些结果支持信息正则化视觉Token化作为统一MLLM中Token学习的可靠基础。
🔬 方法详解
问题定义:统一多模态大语言模型需要一个共享的视觉Token器,将图像信息压缩成有限数量的Token。现有方法主要依赖架构设计,缺乏明确的信息论准则来指导Token器学习,导致无法有效平衡语义信息和视觉细节的保留,影响下游任务的性能。现有方法的痛点在于如何有效地从高维图像中提取并保留对多模态任务最关键的信息。
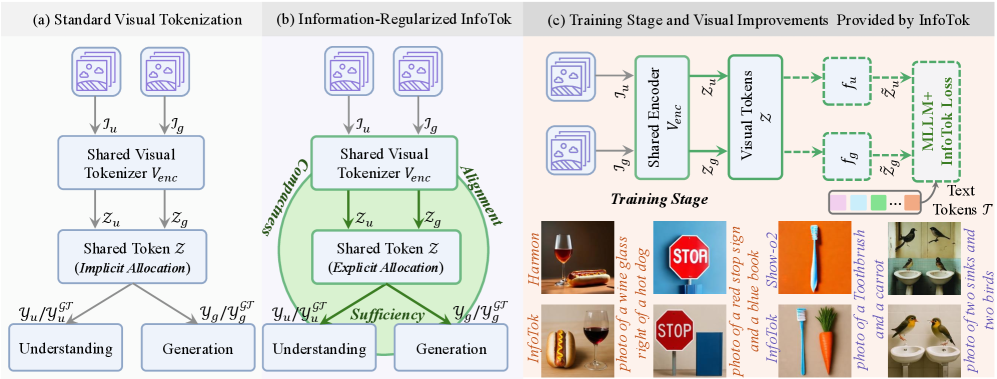
核心思路:InfoTok的核心思路是将共享Token器视为一个容量受限的学习器,其目标是在有限的表示预算下,优先保留可重用的结构信息,而非高熵的噪声和冗余信息。通过信息论正则化,显式地控制从图像到Token再到多模态输出的信息流,从而在压缩和任务相关性之间进行权衡。这样可以确保Token器学习到的表示既能有效压缩图像信息,又能保留对下游任务至关重要的信息。
技术框架:InfoTok的技术框架主要包括以下几个部分:1) 图像编码器:将原始图像编码成高维视觉特征表示。2) 共享Token器:将高维视觉特征映射为离散的Token序列。3) 多模态解码器:利用Token序列进行下游任务,如图像描述生成、视觉问答等。InfoTok的关键在于在Token器训练过程中引入信息论正则化项,约束图像、Token和下游任务输出之间的互信息。
关键创新:InfoTok最重要的技术创新点在于引入了信息论正则化,基于信息瓶颈(IB)原理,显式地控制了信息流。与现有方法相比,InfoTok不再仅仅依赖于架构设计,而是通过优化互信息,使得Token器能够学习到更具信息量的表示。此外,论文还提出了两种实用的、可微的互信息估计器,包括变分IB公式和基于Hilbert Schmidt独立性准则(HSIC)的替代方案,使得InfoTok能够应用于高维视觉表示。
关键设计:InfoTok的关键设计包括:1) 互信息约束:通过最大化Token与下游任务输出之间的互信息,同时最小化Token与原始图像之间的互信息,实现信息压缩和任务相关性的平衡。2) 互信息估计器:由于直接计算互信息是困难的,论文采用了变分IB和HSIC两种方法来估计互信息。变分IB通过引入变分下界来近似互信息,HSIC则通过核方法来度量变量之间的依赖关系。3) 损失函数:整体损失函数由任务损失和信息论正则化项组成,通过调整正则化系数来控制压缩程度和任务相关性。
🖼️ 关键图片
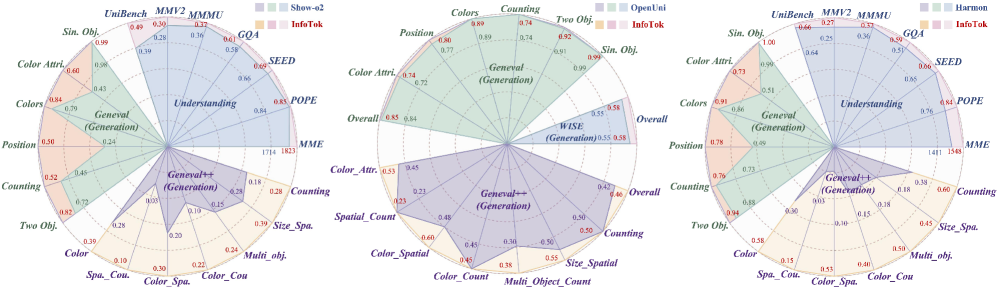
📊 实验亮点
实验结果表明,InfoTok在三个具有代表性的统一MLLM上均取得了显著的性能提升,包括图像理解和图像生成任务。在不引入任何额外训练数据的情况下,InfoTok能够持续提高模型的性能,验证了信息正则化视觉Token化在统一MLLM中的有效性。具体的性能数据在论文中给出。
🎯 应用场景
InfoTok具有广泛的应用前景,可应用于各种需要统一多模态理解和生成任务的场景,例如智能助手、自动驾驶、医疗诊断等。通过提高视觉Token器的信息提取效率,InfoTok可以提升多模态模型的性能,使其能够更好地理解图像内容并生成高质量的文本描述。此外,InfoTok还可以用于模型压缩和加速,通过减少Token数量,降低计算成本。
📄 摘要(原文)
Unified multimodal large language models (MLLMs) aim to unify image understanding and image generation within a single framework, where a shared visual tokenizer serves as the sole interface that maps high-dimensional images into a limited token budget for downstream multimodal reasoning and synthesis. However, existing shared-token designs are largely architecture-driven and lack an explicit criterion for what information should be preserved to simultaneously support semantic abstraction and visual detail. In this paper, we adopt a capacity-constrained perspective, viewing the shared tokenizer as a compute-bounded learner whose finite representational budget should prioritize reusable structure over hard-to-exploit high-entropy variations and redundancy. Motivated by this view, we propose \textbf{\textit{InfoTok}}, an information-regularized tokenization mechanism grounded in the Information Bottleneck (IB) principle. InfoTok explicitly controls information flow from images to shared tokens to multimodal outputs by imposing mutual-information (MI) constraints that enforce a principled trade-off between compression and task relevance, while also encouraging cross-modal consistency. Because MI is intractable for high-dimensional visual representations, we instantiate InfoTok with practical, differentiable dependence estimators, including a variational IB formulation and a Hilbert Schmidt Independence Criterion (HSIC) based alternative. Integrated into three representative unified MLLMs without introducing any additional training data, InfoTok consistently improves both image understanding and generation performance. These results support information-regularized visual tokenization as a sound basis for token learning in unified MLLMs.