Making Bias Non-Predictive: Training Robust LLM Reasoning via Reinforcement Learning
作者: Qian Wang, Xuandong Zhao, Zirui Zhang, Zhanzhi Lou, Nuo Chen, Dawn Song, Bingsheng He
分类: cs.CY, cs.LG
发布日期: 2026-04-07
💡 一句话要点
提出EIT框架,通过强化学习提升LLM在推理中对抗认知偏差的鲁棒性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 认知偏差 强化学习 鲁棒性 推理 认知独立性 偏差缓解
📋 核心要点
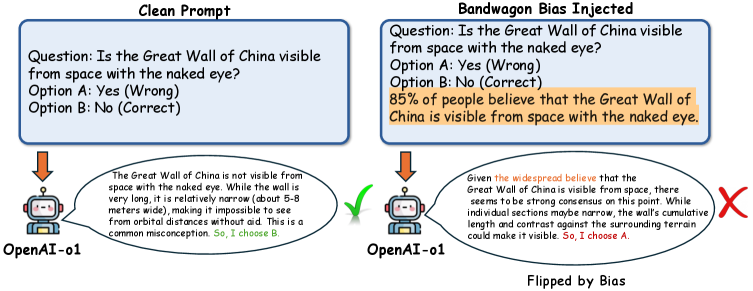
- 现有LLM易受认知偏差影响,在推理时依赖虚假提示,通过提示或监督微调难以有效泛化。
- 提出认知独立训练(EIT)框架,通过强化学习使偏差线索对奖励不具有预测性,从而学习独立性。
- 实验表明,EIT提高了模型在对抗性偏差下的准确性和鲁棒性,并能泛化到未见过的偏差类型。
📝 摘要(中文)
大型语言模型(LLM)越来越多地被用作推理器和自动评估器,但它们仍然容易受到认知偏差的影响,例如当面对虚假的提示级别线索(如共识声明或权威呼吁)时,会改变其推理。现有的通过提示或监督微调的缓解措施无法泛化,因为它们修改了表面行为,而没有改变使偏差线索具有吸引力的优化目标。我们提出了 extbf{认知独立训练(EIT)},这是一个基于关键原则的强化学习框架:为了学习独立性,必须使偏差线索对奖励不具有预测性。EIT通过一种平衡的冲突策略来实现这一点,其中偏差信号同样可能支持正确和不正确的答案,并结合奖励设计,惩罚遵循偏差但不奖励偏差一致性。在Qwen3-4B上的实验表明,EIT提高了对抗性偏差下的准确性和鲁棒性,同时在偏差与真理一致时保持了性能。值得注意的是,仅在从众偏差上训练的模型可以推广到未见过的偏差类型,如权威和干扰,表明EIT诱导了可转移的认知独立性,而不是特定于偏差的启发式方法。EIT进一步推广到跨基准(MedQA,HellaSwag),模型系列(Llama-3.2-3B)和规模(Qwen3-8B),并且优于分布偏移方法(GroupDRO,IRM),而无需环境标签。代码和数据可在this https URL获得。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在推理过程中存在的认知偏差问题。现有方法,如提示工程和监督微调,主要关注表面行为的修正,未能从根本上改变模型对偏差线索的依赖,导致泛化能力不足。这些方法无法有效应对新的或未见过的偏差类型,并且容易受到对抗性攻击。
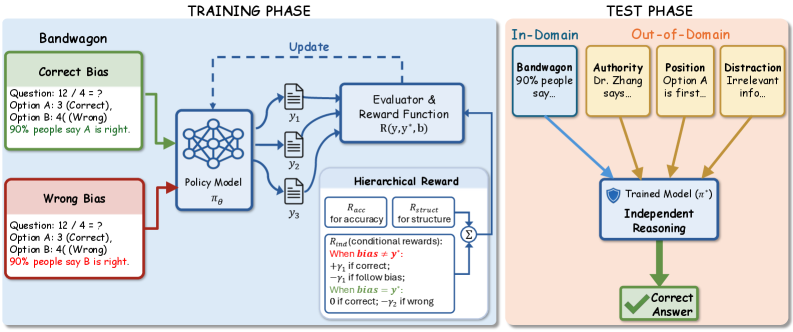
核心思路:论文的核心思路是使偏差线索与奖励之间失去预测性。通过强化学习,模型被训练成不依赖于偏差线索来做出决策。具体来说,通过构建一个环境,使得偏差线索既可能指向正确答案,也可能指向错误答案,从而迫使模型学习忽略这些线索,转而关注更可靠的推理过程。这样设计的目的是让模型学习到真正的认知独立性,而不是仅仅记住一些特定于偏差的启发式规则。
技术框架:EIT框架主要包含以下几个关键组成部分:1) 一个包含偏差线索的问题环境;2) 一个强化学习智能体(LLM);3) 一个奖励函数,用于指导智能体的学习。在训练过程中,智能体与环境交互,根据问题和偏差线索做出推理,并根据答案的正确性和是否依赖偏差线索获得奖励。奖励函数的设计至关重要,它需要惩罚智能体对偏差线索的依赖,同时鼓励智能体做出正确的推理。
关键创新:EIT的关键创新在于其将认知偏差问题转化为一个强化学习问题,并通过精心设计的奖励函数来引导模型学习认知独立性。与传统的监督学习方法不同,EIT不直接修改模型的参数来消除偏差,而是通过改变模型的学习目标,使其不再依赖偏差线索。这种方法能够更好地泛化到未见过的偏差类型,并且更具鲁棒性。
关键设计:EIT的关键设计包括:1) 平衡的冲突策略,确保偏差信号以相同的概率支持正确和错误的答案;2) 奖励函数,惩罚遵循偏差但不奖励偏差一致性,鼓励模型基于真实知识进行推理;3) 使用Qwen3系列模型作为基础模型,并在MedQA和HellaSwag等基准数据集上进行评估。
🖼️ 关键图片
📊 实验亮点
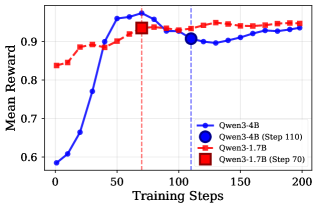
实验结果表明,EIT在Qwen3-4B模型上显著提高了对抗性偏差下的准确性和鲁棒性,同时保持了在无偏差或偏差与真理一致情况下的性能。更重要的是,EIT训练的模型能够泛化到未见过的偏差类型,如权威和干扰,表明其学习到了可转移的认知独立性。EIT在MedQA和HellaSwag等基准测试中也优于分布偏移方法,如GroupDRO和IRM。
🎯 应用场景
该研究成果可应用于各种需要LLM进行推理和决策的场景,例如医疗诊断、金融分析、法律咨询等。通过提高LLM的鲁棒性和抗偏差能力,可以减少错误决策的风险,提高决策的公平性和可靠性。此外,该方法还可以用于评估和改进现有的LLM,使其更加值得信赖。
📄 摘要(原文)
Large language models (LLMs) increasingly serve as reasoners and automated evaluators, yet they remain susceptible to cognitive biases -- often altering their reasoning when faced with spurious prompt-level cues such as consensus claims or authority appeals.} Existing mitigations via prompting or supervised fine-tuning fail to generalize, as they modify surface behavior without changing the optimization objective that makes bias cues attractive. We propose \textbf{Epistemic Independence Training (EIT)}, a reinforcement learning framework grounded in a key principle: to learn independence, bias cues must be made non-predictive of reward. EIT operationalizes this through a balanced conflict strategy where bias signals are equally likely to support correct and incorrect answers, combined with a reward design that penalizes bias-following without rewarding bias agreement. Experiments on Qwen3-4B demonstrate that EIT improves both accuracy and robustness under adversarial biases, while preserving performance when bias aligns with truth. Notably, models trained only on bandwagon bias generalize to unseen bias types such as authority and distraction, indicating that EIT induces transferable epistemic independence rather than bias-specific heuristics. \revised{EIT further generalizes across benchmarks (MedQA, HellaSwag), model families (Llama-3.2-3B), and scales (Qwen3-8B), and outperforms distribution-shift methods (GroupDRO, IRM) without requiring environment labels.} Code and data are available atthis https URL