Audio-to-Image Bird Species Retrieval without Audio-Image Pairs via Text Distillation
作者: Ilyass Moummad, Marius Miron, Lukas Rauch, David Robinson, Alexis Joly, Olivier Pietquin, Emmanuel Chemla, Matthieu Geist
分类: cs.SD, cs.IR, cs.LG
发布日期: 2026-04-07
💡 一句话要点
提出基于文本蒸馏的音频到图像鸟类检索方法,无需配对数据。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 音频到图像检索 文本蒸馏 跨模态学习 生物声学 鸟类识别
📋 核心要点
- 生物声学物种识别中,音频到图像检索提供了一种可解释的替代方案,但缺乏配对数据是挑战。
- 利用预训练的图像-文本模型和音频-文本模型,通过文本蒸馏实现音频和图像的对齐。
- 在SSW60基准测试中,该方法在音频到图像检索任务上超过了现有基线,无需配对数据。
📝 摘要(中文)
本文提出了一种简单且数据高效的方法,用于在没有音频-图像监督的情况下实现音频到图像的检索。该方法使用文本作为语义媒介:通过对比学习目标,将预训练图像-文本模型(BioCLIP-2)的文本嵌入空间(编码了丰富的视觉和分类结构)蒸馏到预训练音频-文本模型(BioLingual)中,具体通过微调其音频编码器实现。这种蒸馏将视觉语义传递到音频表示中,从而在音频和图像嵌入之间产生内在的对齐,而无需在训练期间使用图像。在多个生物声学基准测试中评估了该模型。蒸馏后的音频编码器保留了音频的判别能力,同时显著提高了焦点录音和声景数据集上的音频-文本对齐效果。最重要的是,在SSW60基准测试中,该方法实现了强大的音频到图像检索性能,超过了基于零样本模型组合或文本嵌入之间学习映射的基线,尽管没有在配对的音频-图像数据上进行训练。这些结果表明,通过文本的间接语义传递足以诱导有意义的音频-图像对齐,为数据稀缺的生物声学环境中基于视觉的物种识别提供了一种实用的解决方案。
🔬 方法详解
问题定义:论文旨在解决生物声学领域中,音频到图像检索任务缺乏配对音频-图像数据的问题。现有方法或者依赖大量的配对数据进行训练,或者采用零样本方法,但效果往往不佳。因此,如何在数据稀缺的情况下,实现有效的音频到图像检索是一个关键挑战。
核心思路:论文的核心思路是利用文本作为语义桥梁,通过知识蒸馏的方式,将预训练的图像-文本模型中的视觉语义知识迁移到音频-文本模型中。这样,即使没有直接的音频-图像配对数据,也能在音频和图像之间建立有效的关联。
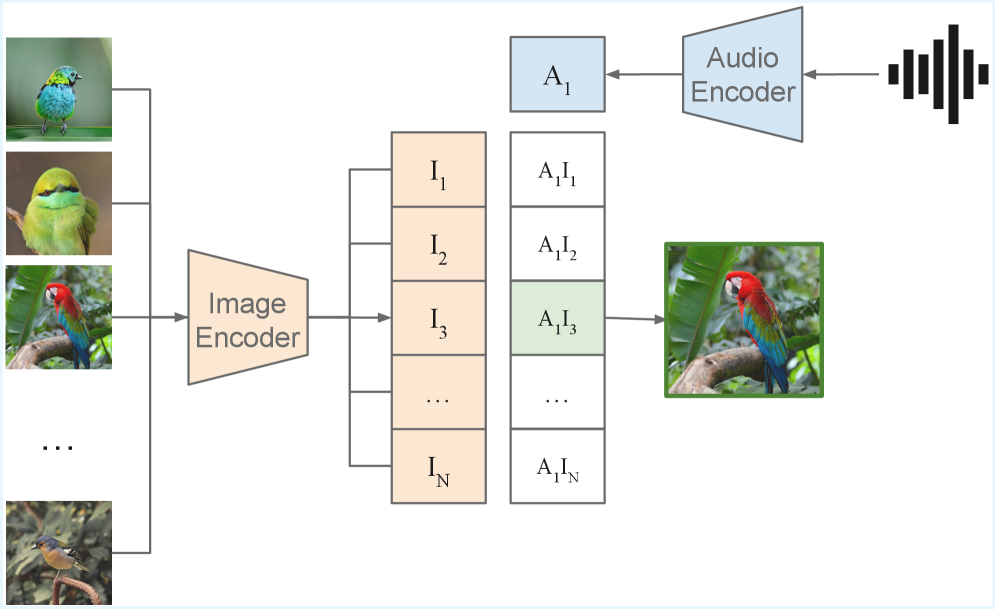
技术框架:整体框架包含以下几个主要步骤:1) 使用预训练的图像-文本模型(BioCLIP-2)和音频-文本模型(BioLingual);2) 固定BioCLIP-2的参数,将其文本嵌入空间作为目标;3) 通过对比学习的方式,微调BioLingual的音频编码器,使其音频嵌入与BioCLIP-2的文本嵌入对齐。
关键创新:最重要的创新点在于利用文本作为语义媒介,实现了音频和图像之间的间接对齐。这种方法避免了对大量配对数据的依赖,使得在数据稀缺的生物声学领域也能实现有效的音频到图像检索。与现有方法相比,该方法不需要任何音频-图像配对数据,而是通过文本蒸馏的方式,将视觉语义知识迁移到音频表示中。
关键设计:论文使用对比学习损失函数来微调BioLingual的音频编码器。具体来说,对于每个音频样本,模型的目标是将其音频嵌入与对应的文本嵌入拉近,同时推远与其他文本嵌入。损失函数的具体形式未知,但可以推测是基于InfoNCE或其他类似的对比学习损失函数。此外,论文还使用了预训练的BioCLIP-2和BioLingual模型,这些模型本身已经包含了丰富的视觉和文本语义知识。
🖼️ 关键图片

📊 实验亮点
该方法在SSW60基准测试中取得了显著的成果,在音频到图像检索任务上超过了基于零样本模型组合或文本嵌入之间学习映射的基线方法,并且无需使用任何配对的音频-图像数据进行训练。这表明通过文本蒸馏可以有效地将视觉语义知识迁移到音频表示中,从而实现有效的跨模态检索。
🎯 应用场景
该研究成果可应用于生物多样性监测、鸟类保护、生态声学等领域。通过声音识别鸟类物种,并检索相关图像,可以帮助研究人员更好地了解鸟类的分布、行为和生态环境。此外,该方法还可以扩展到其他生物声学领域,例如海洋生物监测等。
📄 摘要(原文)
Audio-to-image retrieval offers an interpretable alternative to audio-only classification for bioacoustic species recognition, but learning aligned audio-image representations is challenging due to the scarcity of paired audio-image data. We propose a simple and data-efficient approach that enables audio-to-image retrieval without any audio-image supervision. Our proposed method uses text as a semantic intermediary: we distill the text embedding space of a pretrained image-text model (BioCLIP-2), which encodes rich visual and taxonomic structure, into a pretrained audio-text model (BioLingual) by fine-tuning its audio encoder with a contrastive objective. This distillation transfers visually grounded semantics into the audio representation, inducing emergent alignment between audio and image embeddings without using images during training. We evaluate the resulting model on multiple bioacoustic benchmarks. The distilled audio encoder preserves audio discriminative power while substantially improving audio-text alignment on focal recordings and soundscape datasets. Most importantly, on the SSW60 benchmark, the proposed approach achieves strong audio-to-image retrieval performance exceeding baselines based on zero-shot model combinations or learned mappings between text embeddings, despite not training on paired audio-image data. These results demonstrate that indirect semantic transfer through text is sufficient to induce meaningful audio-image alignment, providing a practical solution for visually grounded species recognition in data-scarce bioacoustic settings.