From Bits to Chips: An LLM-based Hardware-Aware Quantization Agent for Streamlined Deployment of LLMs
作者: Kaiyuan Deng, Hangyu Zheng, Minghai Qing, Kunxiong Zhu, Gen Li, Yang Xiao, Lan Emily Zhang, Linke Guo, Bo Hui, Yanzhi Wang, Geng Yuan, Gagan Agrawal, Wei Niu, Xiaolong Ma
分类: cs.LG
发布日期: 2026-04-07
💡 一句话要点
提出基于LLM的硬件感知量化Agent(HAQA),简化LLM部署流程。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 模型量化 硬件感知 自动化部署 LLM Agent
📋 核心要点
- 大型语言模型部署面临硬件资源约束,量化技术虽能缓解瓶颈,但调优和部署的复杂性阻碍了广泛应用。
- HAQA利用LLM自动化量化和部署流程,实现高效超参数调优和硬件配置,提升部署质量和易用性。
- 实验表明,HAQA在Llama模型上实现了高达2.3倍的推理加速,并提高了吞吐量和准确性,同时具备跨平台自适应性。
📝 摘要(中文)
本文提出了一种名为硬件感知量化Agent(HAQA)的自动化框架,该框架利用大型语言模型(LLM)来简化整个量化和部署流程。HAQA通过实现高效的超参数调优和硬件配置,在提高部署质量的同时,降低了用户的使用门槛。实验结果表明,与未优化的Llama模型相比,HAQA在推理速度上提高了2.3倍,并提升了吞吐量和准确性。此外,HAQA旨在实现跨不同硬件平台的自适应量化策略,即使在出现违反直觉的最佳设置时,也能自动找到最佳设置,从而减少大量的人工工作,并展示出卓越的适应性。代码即将开源。
🔬 方法详解
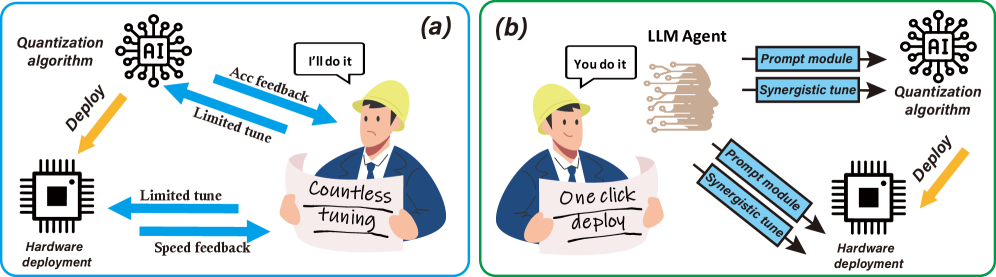
问题定义:现有的大型语言模型(LLM)部署面临着硬件资源限制的挑战,尤其是在资源受限的设备上。模型量化是一种有效的技术,可以减少内存占用和计算需求,但量化模型的调优和部署过程复杂,需要专业的知识和大量的实验,这使得非专业用户难以应用。因此,如何简化LLM的量化和部署流程,使其更易于使用,同时保证模型的性能,是一个亟待解决的问题。
核心思路:本文的核心思路是利用大型语言模型(LLM)的强大能力,构建一个自动化框架,即硬件感知量化Agent(HAQA)。HAQA通过LLM来自动搜索和优化量化策略和硬件配置,从而在满足硬件约束的同时,最大化模型的性能。这种方法的核心在于将量化和部署过程转化为一个LLM可以理解和解决的问题,从而减少了人工干预和专业知识的需求。
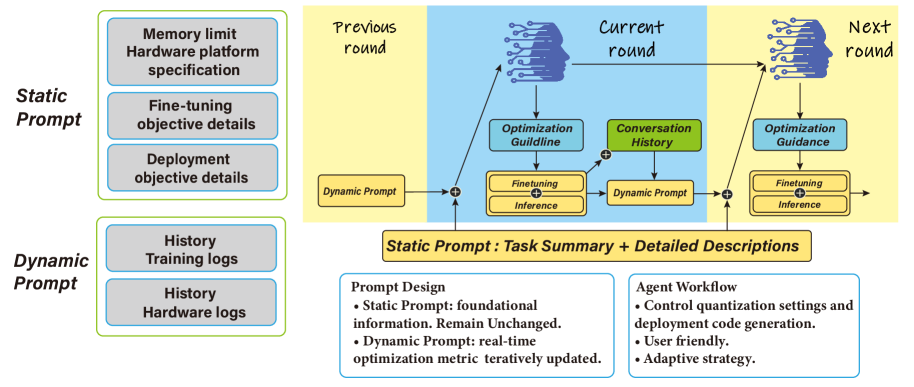
技术框架:HAQA的整体框架包含以下几个主要模块:1) LLM Agent:作为核心控制器,负责接收用户输入(如模型类型、硬件平台等),并生成量化策略和硬件配置方案。2) Quantization Engine:根据LLM Agent生成的策略,对模型进行量化。3) Performance Evaluator:评估量化后模型在目标硬件上的性能(如推理速度、准确率等)。4) Feedback Loop:将Performance Evaluator的评估结果反馈给LLM Agent,LLM Agent根据反馈结果调整量化策略和硬件配置,进行迭代优化。整个流程通过循环迭代,最终找到最优的量化方案。
关键创新:HAQA的关键创新在于利用LLM来自动化量化和部署流程。与传统的量化方法相比,HAQA无需人工进行大量的实验和调优,而是通过LLM的推理能力,自动搜索和优化量化策略。此外,HAQA还具备硬件感知能力,可以根据不同的硬件平台,自适应地调整量化策略,从而实现最佳的性能。这种基于LLM的自动化方法,大大降低了量化和部署的难度,使得更多的用户可以轻松地部署LLM。
关键设计:HAQA的关键设计包括:1) LLM Agent的设计:如何设计LLM Agent的prompt,使其能够有效地生成量化策略和硬件配置方案。2) Performance Evaluator的设计:如何快速准确地评估量化后模型的性能。3) Feedback Loop的设计:如何将Performance Evaluator的评估结果有效地反馈给LLM Agent,使其能够进行迭代优化。此外,HAQA还采用了多种量化技术,如PTQ(Post-Training Quantization)和QAT(Quantization-Aware Training),以进一步提高量化模型的性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,HAQA在Llama模型上实现了高达2.3倍的推理加速,同时提高了吞吐量和准确性。与未优化的模型相比,HAQA能够显著提升模型的性能。此外,HAQA还展示了其在不同硬件平台上的自适应能力,能够自动找到最优的量化策略,即使这些策略看起来违反直觉。这些结果表明,HAQA是一种高效、易用、且具有广泛适用性的LLM部署工具。
🎯 应用场景
HAQA的应用场景广泛,包括但不限于:在边缘设备(如手机、嵌入式系统)上部署大型语言模型,以实现本地化的智能服务;在云计算平台上部署大型语言模型,以提供更高效、更经济的推理服务;在科研领域,HAQA可以作为一种自动化工具,帮助研究人员快速探索不同的量化策略,加速LLM的优化和部署。HAQA的出现,有望推动LLM在更广泛的领域得到应用。
📄 摘要(原文)
Deploying models, especially large language models (LLMs), is becoming increasingly attractive to a broader user base, including those without specialized expertise. However, due to the resource constraints of certain hardware, maintaining high accuracy with larger model while meeting the hardware requirements remains a significant challenge. Model quantization technique helps mitigate memory and compute bottlenecks, yet the added complexities of tuning and deploying quantized models further exacerbates these challenges, making the process unfriendly to most of the users. We introduce the Hardware-Aware Quantization Agent (HAQA), an automated framework that leverages LLMs to streamline the entire quantization and deployment process by enabling efficient hyperparameter tuning and hardware configuration, thereby simultaneously improving deployment quality and ease of use for a broad range of users. Our results demonstrate up to a 2.3x speedup in inference, along with increased throughput and improved accuracy compared to unoptimized models on Llama. Additionally, HAQA is designed to implement adaptive quantization strategies across diverse hardware platforms, as it automatically finds optimal settings even when they appear counterintuitive, thereby reducing extensive manual effort and demonstrating superior adaptability. Code will be released.