Bridging the Semantic Gap for Categorical Data Clustering via Large Language Models
作者: Zihua Yang, Xin Liao, Yiqun Zhang, Yiu-ming Cheung
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-04-07
💡 一句话要点
提出ARISE,利用大语言模型弥合分类数据聚类中的语义鸿沟
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 分类数据聚类 大语言模型 语义嵌入 注意力机制 外部知识 表示学习
📋 核心要点
- 分类数据聚类面临语义鸿沟问题,现有方法依赖数据集内部共现模式,在样本有限时表现不佳。
- ARISE利用大语言模型(LLM)的外部知识,构建语义感知的表示,弥补分类数据聚类的语义信息缺失。
- 实验结果表明,ARISE在多个基准数据集上显著优于现有方法,性能提升高达19-27%。
📝 摘要(中文)
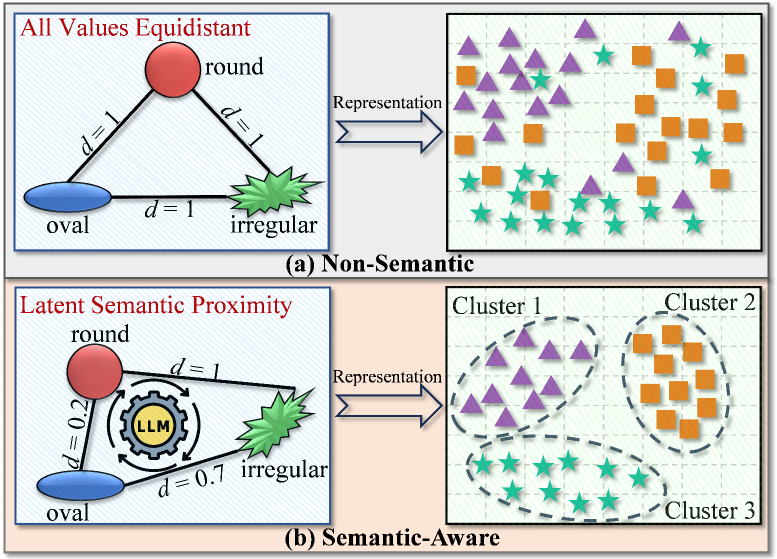
分类数据在医疗、市场营销和生物信息学等领域普遍存在,聚类是发现模式的基本工具。分类数据聚类的核心挑战在于衡量属性值之间的相似性,这些属性值缺乏固有的顺序或距离。如果没有适当的相似性度量,这些值通常被视为等距的,从而产生语义鸿沟,掩盖潜在的结构并降低聚类质量。虽然现有的方法从数据集内的共现模式推断值关系,但当样本有限时,这种推断变得不可靠,导致数据的语义上下文未被充分探索。为了弥合这一差距,我们提出了ARISE(Attention-weighted Representation with Integrated Semantic Embeddings),它利用来自大型语言模型(LLM)的外部语义知识来构建语义感知的表示,从而补充分类数据的度量空间,以实现准确的聚类。也就是说,采用LLM来描述属性值以增强表示,并将LLM增强的嵌入与原始数据相结合,以探索语义上突出的聚类。在八个基准数据集上的实验表明,相对于七个代表性方法,ARISE 取得了持续的改进,增益为 19-27%。
🔬 方法详解
问题定义:分类数据聚类中,由于属性值缺乏内在顺序和距离概念,导致难以准确衡量属性值之间的相似性。现有方法主要依赖数据集内部的共现模式来推断值关系,但当数据量较少时,这种推断的可靠性会显著降低,无法有效利用数据中蕴含的语义信息。
核心思路:ARISE的核心思路是利用外部知识,特别是大型语言模型(LLM)中蕴含的丰富语义信息,来增强分类数据的表示。通过将LLM对属性值的语义描述融入到聚类过程中,可以更准确地捕捉属性值之间的关系,从而提高聚类效果。
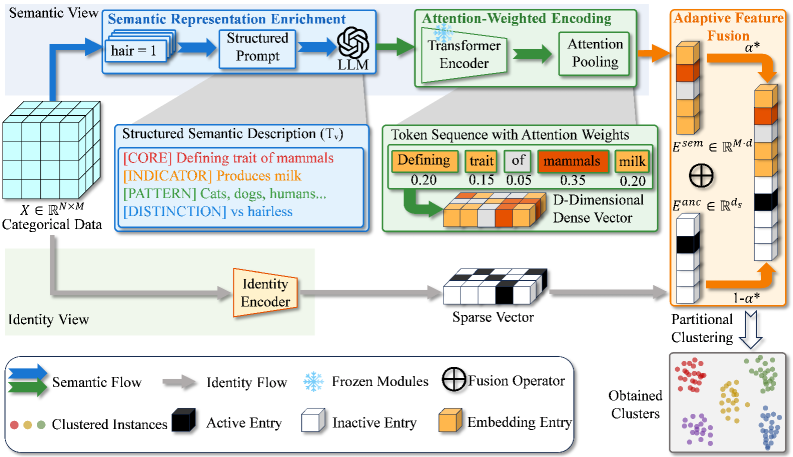
技术框架:ARISE主要包含以下几个阶段:1) LLM嵌入生成:使用LLM对每个属性值进行描述,生成相应的语义嵌入。2) 注意力权重计算:计算每个属性值在聚类中的重要性,并赋予相应的注意力权重。3) 语义增强表示构建:将LLM生成的语义嵌入与原始数据相结合,构建语义增强的表示。4) 聚类:使用聚类算法(如k-means)对语义增强的表示进行聚类。
关键创新:ARISE的关键创新在于引入了外部语义知识,利用LLM来弥合分类数据聚类中的语义鸿沟。与现有方法相比,ARISE不再局限于数据集内部的信息,而是能够利用更广泛的语义信息来指导聚类过程。
关键设计:在LLM嵌入生成阶段,可以选择不同的LLM模型和prompt策略,以获得更准确的语义描述。注意力权重的计算可以采用不同的方法,例如基于信息增益或方差。在语义增强表示构建阶段,需要仔细设计融合策略,以平衡原始数据和LLM嵌入之间的权重。
🖼️ 关键图片
📊 实验亮点
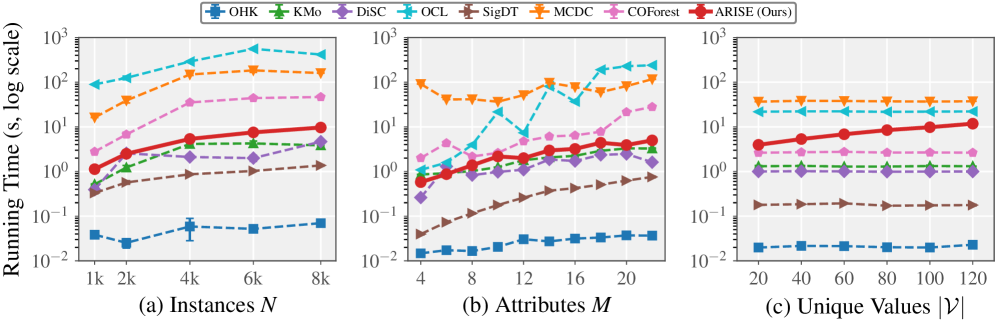
在八个基准数据集上的实验结果表明,ARISE相对于七个代表性方法取得了显著的性能提升,平均增益达到19-27%。这些数据集涵盖了不同的领域和数据特征,证明了ARISE的通用性和有效性。实验结果表明,ARISE能够有效地利用LLM的语义信息,提高分类数据聚类的准确性。
🎯 应用场景
ARISE可广泛应用于医疗、市场营销、生物信息学等领域,例如,在医疗领域,可以利用患者的病史、症状等分类数据进行聚类,发现具有相似疾病特征的患者群体;在市场营销领域,可以对客户的购买行为、偏好等数据进行聚类,实现精准营销;在生物信息学领域,可以对基因表达数据进行聚类,发现具有相似生物学功能的基因。
📄 摘要(原文)
Categorical data are prevalent in domains such as healthcare, marketing, and bioinformatics, where clustering serves as a fundamental tool for pattern discovery. A core challenge in categorical data clustering lies in measuring similarity among attribute values that lack inherent ordering or distance. Without appropriate similarity measures, values are often treated as equidistant, creating a semantic gap that obscures latent structures and degrades clustering quality. Although existing methods infer value relationships from within-dataset co-occurrence patterns, such inference becomes unreliable when samples are limited, leaving the semantic context of the data underexplored. To bridge this gap, we present ARISE (Attention-weighted Representation with Integrated Semantic Embeddings), which draws on external semantic knowledge from Large Language Models (LLMs) to construct semantic-aware representations that complement the metric space of categorical data for accurate clustering. That is, LLM is adopted to describe attribute values for representation enhancement, and the LLM-enhanced embeddings are combined with the original data to explore semantically prominent clusters. Experiments on eight benchmark datasets demonstrate consistent improvements over seven representative counterparts, with gains of 19-27%. Code is available atthis https URL