xRFM: Accurate, scalable, and interpretable feature learning models for tabular data
作者: Daniel Beaglehole, David Holzmüller, Adityanarayanan Radhakrishnan, Mikhail Belkin
分类: cs.LG, stat.ML
发布日期: 2026-04-07
💡 一句话要点
xRFM:一种准确、可扩展且可解释的表格数据特征学习模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表格数据 特征学习 核机器 决策树 可解释性 机器学习 分类 回归
📋 核心要点
- 表格数据推断是重要基础,但现有方法(如GBDTs)发展相对停滞,难以满足日益增长的需求。
- xRFM结合特征学习核机器与树结构,旨在适应数据局部结构并具备良好的可扩展性。
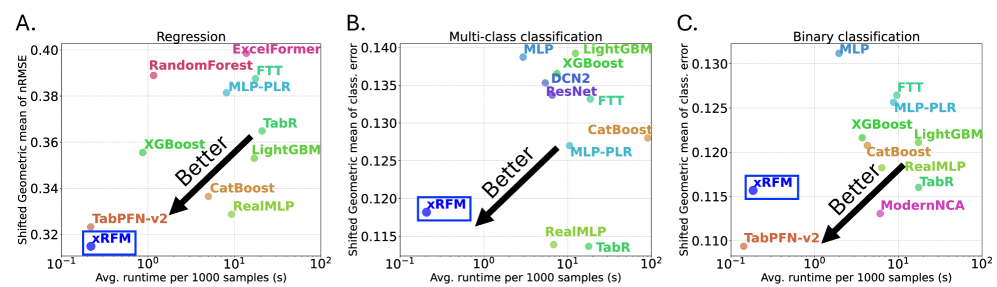
- 实验表明,xRFM在回归任务上优于其他31种方法,并在分类任务上与最佳方法竞争,同时提供可解释性。
📝 摘要(中文)
表格数据(组织成矩阵的连续和分类变量集合)的推断是现代技术和科学的基础。然而,与人工智能领域爆炸性的变化相比,这些预测任务的最佳实践相对没有变化,并且仍然主要基于梯度提升决策树(GBDTs)的变体。最近,人们重新燃起了对基于神经网络和特征学习方法开发表格数据最先进方法的兴趣。在这项工作中,我们介绍了一种名为xRFM的算法,该算法将特征学习核机器与树结构相结合,既能适应数据的局部结构,又能扩展到几乎无限量的训练数据。我们表明,与包括最近引入的表格基础模型(TabPFNv2)和GBDTs在内的31种其他方法相比,xRFM在100个回归数据集上实现了最佳性能,并且在200个分类数据集上与最佳方法相比具有竞争力,优于GBDTs。此外,xRFM通过平均梯度外积原生提供可解释性。
🔬 方法详解
问题定义:论文旨在解决表格数据预测任务中现有方法(主要是GBDTs)的局限性。现有方法虽然有效,但在适应复杂数据结构、可扩展性和可解释性方面存在不足,难以充分利用现代机器学习的最新进展。
核心思路:xRFM的核心思路是将特征学习核机器的强大特征提取能力与树结构的局部适应性和可扩展性相结合。通过特征学习,模型能够自动提取数据中的有效特征,而树结构则允许模型根据数据的局部特征进行自适应调整,从而提高预测精度和泛化能力。
技术框架:xRFM的整体架构包含特征学习模块和树结构模块。特征学习模块负责从原始表格数据中提取高阶特征表示,可以使用各种核机器方法。树结构模块则基于学习到的特征进行决策,最终输出预测结果。训练过程通常采用端到端的方式,联合优化特征学习模块和树结构模块。
关键创新:xRFM的关键创新在于将特征学习和树结构有机结合,克服了传统方法的局限性。与GBDTs相比,xRFM能够自动学习更有效的特征表示,无需手动特征工程。与深度学习模型相比,xRFM具有更好的可解释性和可扩展性。
关键设计:xRFM的具体实现细节取决于所选择的特征学习方法和树结构。例如,特征学习模块可以使用高斯核或多项式核,树结构可以使用决策树或随机森林。损失函数通常选择均方误差(回归任务)或交叉熵损失(分类任务)。关键参数包括核函数的参数、树的深度和叶子节点的最小样本数等。
🖼️ 关键图片


📊 实验亮点
实验结果表明,xRFM在100个回归数据集上取得了最佳性能,显著优于包括TabPFNv2和GBDTs在内的31种其他方法。在200个分类数据集上,xRFM的性能与最佳方法相当,并且优于GBDTs。这些结果证明了xRFM在表格数据预测任务中的有效性和竞争力。
🎯 应用场景
xRFM可广泛应用于各种涉及表格数据的预测任务,例如金融风险评估、医疗诊断、客户行为分析、推荐系统等。其可解释性使其在需要理解模型决策过程的场景中尤为有价值。未来,xRFM有望成为表格数据分析的标准工具,推动相关领域的发展。
📄 摘要(原文)
Inference from tabular data, collections of continuous and categorical variables organized into matrices, is a foundation for modern technology and science. Yet, in contrast to the explosive changes in the rest of AI, the best practice for these predictive tasks has been relatively unchanged and is still primarily based on variations of Gradient Boosted Decision Trees (GBDTs). Very recently, there has been renewed interest in developing state-of-the-art methods for tabular data based on recent developments in neural networks and feature learning methods. In this work, we introduce xRFM, an algorithm that combines feature learning kernel machines with a tree structure to both adapt to the local structure of the data and scale to essentially unlimited amounts of training data.We show that compared to $31$ other methods, including recently introduced tabular foundation models (TabPFNv2) and GBDTs, xRFM achieves best performance across $100$ regression datasets and is competitive to the best methods across $200$ classification datasets outperforming GBDTs. Additionally, xRFM provides interpretability natively through the Average Gradient Outer Product.