Principal Prototype Analysis on Manifold for Interpretable Reinforcement Learning
作者: Bodla Krishna Vamshi, Haizhao Yang
分类: cs.LG
发布日期: 2026-03-30
💡 一句话要点
提出基于流形的主成分原型分析方法,用于可解释强化学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 可解释性 原型学习 流形学习 主成分分析 自动原型选择 原型包装网络
📋 核心要点
- 强化学习模型日益复杂,但可解释性不足,现有方法难以兼顾性能与可解释性。
- 提出一种自动选择最优原型的方案,无需人工干预,提升强化学习模型的可解释性。
- 在标准Gym环境的实验表明,该方法在性能上与现有原型网络相当,并保持了竞争力。
📝 摘要(中文)
近年来,强化学习(RL)得到了广泛应用,从解决实时游戏到使用人类偏好数据微调大型语言模型,显著提高了与用户期望的对齐。然而,随着模型复杂性呈指数级增长,这些系统的可解释性变得越来越具有挑战性。虽然已经为计算机视觉和自然语言处理开发了许多可解释性方法来阐明局部和全局推理模式,但它们在RL中的应用仍然有限。这些方法的直接扩展通常难以维持RL环境中可解释性和性能之间的微妙平衡。原型包装网络(PW-Nets)最近在弥合这一差距方面显示出希望,通过增强RL领域的可解释性而不牺牲原始黑盒模型的效率。然而,这些方法通常需要手动定义的参考原型,这通常需要专家领域知识。在这项工作中,我们提出了一种方法,通过自动从可用数据中选择最佳原型来消除这种依赖性。在标准Gym环境上的初步实验表明,我们的方法与现有PW-Nets的性能相匹配,同时与原始黑盒模型相比仍具有竞争力。
🔬 方法详解
问题定义:强化学习模型的可解释性问题日益突出,现有原型包装网络(PW-Nets)依赖于手动定义的参考原型,需要专家领域知识,限制了其应用范围和自动化程度。因此,需要一种自动选择最优原型的方法,以提高强化学习模型的可解释性,同时保持其性能。
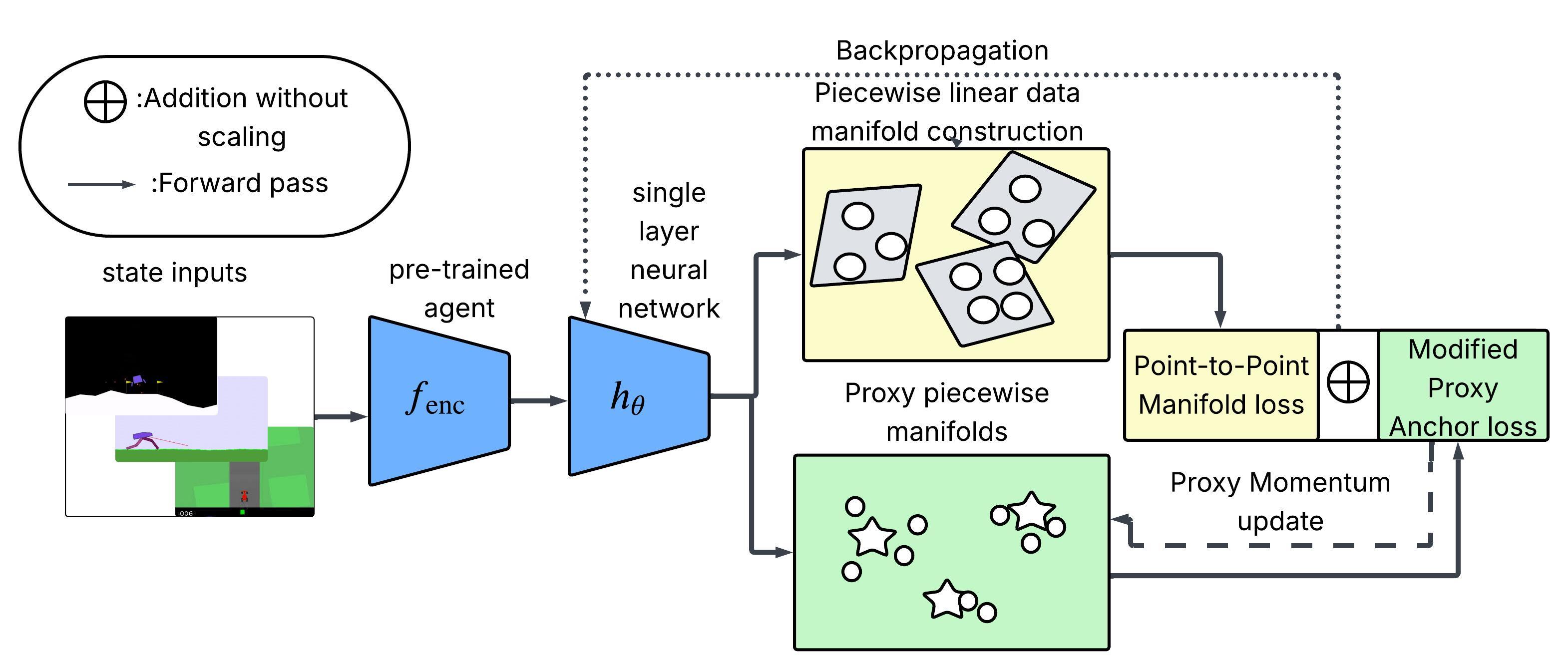
核心思路:该论文的核心思路是通过主成分分析(PCA)在流形上自动选择最优原型。通过分析状态空间的流形结构,找到最具代表性的状态作为原型,从而避免了手动选择的依赖性,并能够更好地捕捉状态空间的关键特征。
技术框架:该方法的技术框架主要包括以下几个步骤:1)收集强化学习过程中的状态数据;2)使用流形学习技术(如PCA)对状态空间进行降维和分析;3)基于PCA的结果,自动选择最具代表性的状态作为原型;4)将选择的原型集成到原型包装网络(PW-Nets)中,用于增强模型的可解释性。
关键创新:该方法最重要的技术创新点在于自动原型选择机制。与现有方法需要手动定义原型不同,该方法通过主成分分析在流形上自动选择最优原型,无需专家领域知识,提高了方法的通用性和自动化程度。这种自动选择机制能够更好地捕捉状态空间的关键特征,从而提高模型的可解释性。
关键设计:该方法的关键设计包括:1)使用PCA进行流形学习,提取状态空间的主成分;2)基于主成分的方差贡献率,选择最具代表性的状态作为原型;3)设计合适的损失函数,鼓励原型能够有效地解释状态空间;4)调整PW-Nets的网络结构,使其能够更好地利用自动选择的原型。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在标准Gym环境中与现有的原型包装网络(PW-Nets)性能相当,并且与原始黑盒模型相比仍具有竞争力。这表明该方法在提高可解释性的同时,没有显著降低模型的性能。自动选择的原型能够有效地解释状态空间,并提供有价值的决策依据。
🎯 应用场景
该研究成果可应用于各种强化学习任务中,尤其是在需要高可解释性的场景,例如自动驾驶、医疗诊断、金融交易等。通过提供可解释的决策过程,可以增强用户对强化学习系统的信任,并促进其在实际应用中的部署。此外,该方法还可以用于调试和优化强化学习模型,提高其性能和鲁棒性。
📄 摘要(原文)
Recent years have witnessed the widespread adoption of reinforcement learning (RL), from solving real-time games to fine-tuning large language models using human preference data significantly improving alignment with user expectations. However, as model complexity grows exponentially, the interpretability of these systems becomes increasingly challenging. While numerous explainability methods have been developed for computer vision and natural language processing to elucidate both local and global reasoning patterns, their application to RL remains limited. Direct extensions of these methods often struggle to maintain the delicate balance between interpretability and performance within RL settings. Prototype-Wrapper Networks (PW-Nets) have recently shown promise in bridging this gap by enhancing explainability in RL domains without sacrificing the efficiency of the original black-box models. However, these methods typically require manually defined reference prototypes, which often necessitate expert domain knowledge. In this work, we propose a method that removes this dependency by automatically selecting optimal prototypes from the available data. Preliminary experiments on standard Gym environments demonstrate that our approach matches the performance of existing PW-Nets, while remaining competitive with the original black-box models.