Collaborative Temporal Feature Generation via Critic-Free Reinforcement Learning for Cross-User Sensor-Based Activity Recognition
作者: Xiaozhou Ye, Feng Jiang, Zihan Wang, Xiulai Wang, Yutao Zhang, Kevin I-Kai Wang
分类: cs.LG, cs.AI, cs.CV
发布日期: 2026-03-17
💡 一句话要点
提出CTFG框架以解决跨用户传感器活动识别问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人体活动识别 跨用户泛化 强化学习 特征生成 传感器数据 Transformer 无评论优化 时间序列分析
📋 核心要点
- 现有的人体活动识别方法未能有效处理跨用户的异质性,导致识别准确率低下。
- 本文提出CTFG框架,通过强化学习实现特征的协作生成,克服了传统方法的局限性。
- 在DSADS和PAMAP2数据集上,CTFG实现了88.53%和75.22%的跨用户准确率,显著提升了模型的泛化能力。
📝 摘要(中文)
使用可穿戴惯性传感器的人体活动识别在医疗监测、健身分析和上下文感知计算中具有基础性意义,但由于用户间生理特征、运动习惯和传感器放置的异质性,导致其应用受到限制。现有的领域泛化方法要么忽视传感器流中的时间依赖性,要么依赖于不切实际的目标领域标注。本文提出了一种新范式,将可泛化特征提取建模为一个由强化学习驱动的协作序列生成过程。我们的框架CTFG采用基于Transformer的自回归生成器,逐步构建特征令牌序列,并通过无评论算法Group-Relative Policy Optimization进行优化,消除了基于评论方法的分布依赖偏差。实验结果表明,在DSADS和PAMAP2基准上实现了最先进的跨用户准确率,显著降低了任务间训练方差,加速了收敛,并在不同动作空间维度下展现了强大的泛化能力。
🔬 方法详解
问题定义:本文旨在解决跨用户传感器基础活动识别中的生理特征和运动习惯的异质性问题。现有方法往往忽视时间依赖性或依赖于不切实际的目标领域标注,导致识别效果不佳。
核心思路:论文提出将可泛化特征提取视为一个协作序列生成过程,利用强化学习优化生成器,逐步构建特征令牌序列,以提高跨用户活动识别的准确性和稳定性。
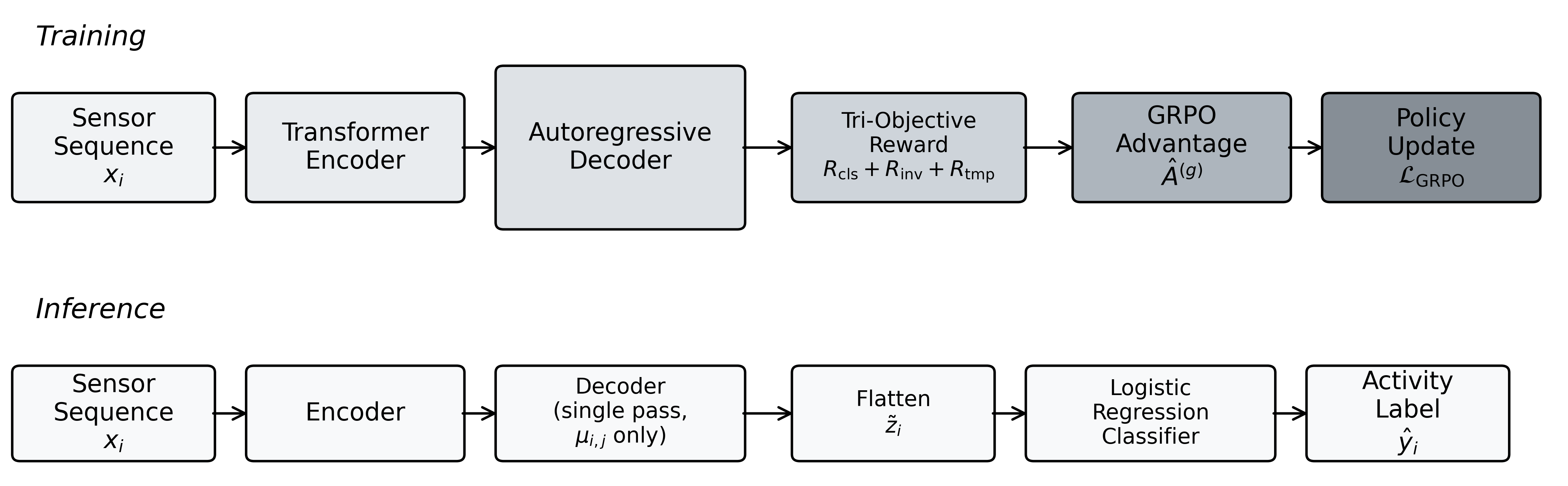
技术框架:CTFG框架包括一个基于Transformer的自回归生成器,生成器根据先前的上下文和编码的传感器输入逐步生成特征序列。优化过程采用Group-Relative Policy Optimization算法,避免了传统评论方法的偏差。
关键创新:CTFG的主要创新在于采用无评论的优化方法,通过组内归一化评估生成序列,消除了分布依赖的偏差,提供了稳定的自校准优化信号。
关键设计:CTFG设计了三目标奖励机制,包括类别区分、跨用户不变性和时间保真度,确保生成的特征能够有效分离活动、对齐用户分布并保留细粒度的时间内容。
🖼️ 关键图片


📊 实验亮点
在DSADS和PAMAP2基准测试中,CTFG框架分别达到了88.53%和75.22%的跨用户准确率,显著降低了任务间训练方差,并加速了模型收敛,展现出在不同动作空间维度下的强大泛化能力。
🎯 应用场景
该研究在医疗监测、智能健身和上下文感知计算等领域具有广泛的应用潜力。通过提高跨用户活动识别的准确性,CTFG框架能够为个性化健康管理和智能设备交互提供更可靠的支持,推动相关技术的进步与普及。
📄 摘要(原文)
Human Activity Recognition using wearable inertial sensors is foundational to healthcare monitoring, fitness analytics, and context-aware computing, yet its deployment is hindered by cross-user variability arising from heterogeneous physiological traits, motor habits, and sensor placements. Existing domain generalization approaches either neglect temporal dependencies in sensor streams or depend on impractical target-domain annotations. We propose a different paradigm: modeling generalizable feature extraction as a collaborative sequential generation process governed by reinforcement learning. Our framework, CTFG (Collaborative Temporal Feature Generation), employs a Transformer-based autoregressive generator that incrementally constructs feature token sequences, each conditioned on prior context and the encoded sensor input. The generator is optimized via Group-Relative Policy Optimization, a critic-free algorithm that evaluates each generated sequence against a cohort of alternatives sampled from the same input, deriving advantages through intra-group normalization rather than learned value estimation. This design eliminates the distribution-dependent bias inherent in critic-based methods and provides self-calibrating optimization signals that remain stable across heterogeneous user distributions. A tri-objective reward comprising class discrimination, cross-user invariance, and temporal fidelity jointly shapes the feature space to separate activities, align user distributions, and preserve fine-grained temporal content. Evaluations on the DSADS and PAMAP2 benchmarks demonstrate state-of-the-art cross-user accuracy (88.53\% and 75.22\%), substantial reduction in inter-task training variance, accelerated convergence, and robust generalization under varying action-space dimensionalities.