Structure and Redundancy in Large Language Models: A Spectral Study via Random Matrix Theory
作者: Davide Ettori
分类: cs.LG, cs.AI
发布日期: 2026-02-28
💡 一句话要点
利用随机矩阵理论进行谱分析,提升大语言模型的可靠性和效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 随机矩阵理论 谱分析 知识蒸馏 模型压缩 幻觉检测 可靠性 效率
📋 核心要点
- 现有大语言模型面临内部行为不透明、易产生幻觉、泛化能力弱等问题,同时计算和能源需求巨大。
- 论文核心思想是利用谱几何和随机矩阵理论,分析模型内部激活的特征值动态,区分结构化信息和噪声。
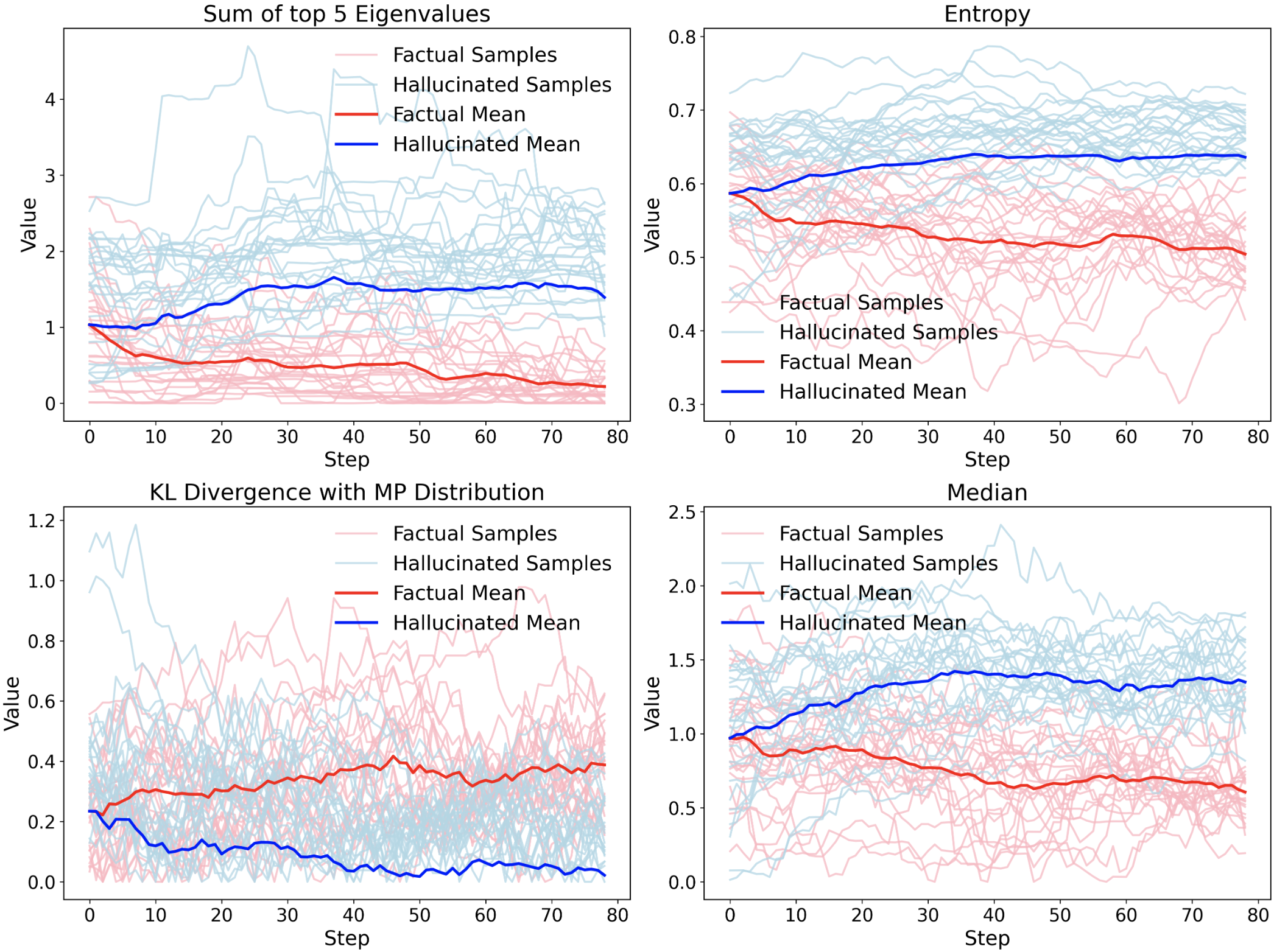
- 论文提出EigenTrack和RMT-KD两种方法,分别用于检测幻觉和压缩模型,提升可靠性和效率。
📝 摘要(中文)
本论文通过谱几何和随机矩阵理论(RMT)的统一框架,解决现代深度学习中可靠性和效率这两个密切相关的挑战。随着深度网络和大型语言模型规模的持续扩大,其内部行为变得越来越不透明,导致幻觉、分布偏移下的脆弱泛化以及不断增长的计算和能源需求。通过分析跨层和输入的隐藏激活的特征值动态,本文表明谱统计提供了一个紧凑、稳定且可解释的模型行为视角,能够将结构化的因果表示与噪声主导的可变性区分开来。在此框架内,第一个贡献 EigenTrack 提出了一种实时方法,用于检测大型语言和视觉语言模型中的幻觉和分布外行为。EigenTrack 将流式激活转换为谱描述符,例如熵、方差以及与 Marchenko-Pastur 基线的偏差,并使用轻量级循环分类器对它们的时序演化进行建模,从而能够在模型输出中出现可靠性故障之前对其进行早期检测,同时提供对表示动态的可解释性洞察。第二个贡献 RMT-KD 提出了一种通过随机矩阵理论知识蒸馏压缩深度网络的原则性方法。通过将激活谱中的异常值特征值解释为任务相关信息的载体,RMT-KD 通过迭代自蒸馏将网络逐步投影到较低维子空间,从而产生更紧凑、更节能的模型,同时保持准确性和密集的、硬件友好的结构。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)和深度神经网络,随着规模的增大,其内部运作机制变得难以理解,导致模型在面对未知的输入时容易产生幻觉,泛化能力下降,并且计算资源消耗巨大。现有的方法难以有效地识别和缓解这些问题,同时也缺乏对模型内部表示的深入理解。
核心思路:本论文的核心思路是利用随机矩阵理论(RMT)分析模型内部激活的谱特性。通过将激活矩阵的特征值分布与RMT的理论结果进行比较,可以区分模型学习到的结构化信息和噪声。异常的特征值往往携带了与任务相关的重要信息,而噪声则表现为符合特定分布的随机波动。基于此,可以设计算法来检测异常行为,并对模型进行压缩。
技术框架:论文提出了两个主要的技术框架:EigenTrack和RMT-KD。EigenTrack用于实时检测LLM中的幻觉和分布外行为。它将模型的激活转化为谱描述符,如熵、方差等,并使用循环分类器对这些描述符的时序演化进行建模,从而实现对异常行为的早期预警。RMT-KD则是一种基于RMT的知识蒸馏方法,用于压缩深度网络。它通过迭代自蒸馏,将网络投影到低维子空间,从而减少模型的参数量和计算复杂度。
关键创新:论文的关键创新在于将随机矩阵理论应用于分析和改进深度神经网络。传统的深度学习方法往往将模型视为黑盒,缺乏对模型内部表示的深入理解。而本论文通过RMT提供了一种新的视角,可以从谱的角度理解模型的行为,并基于此设计更有效的算法。EigenTrack能够实时检测幻觉,RMT-KD能够在保持精度的前提下显著压缩模型。
关键设计:EigenTrack的关键设计在于选择合适的谱描述符和循环分类器。谱描述符需要能够有效地捕捉激活矩阵的异常变化,循环分类器需要能够对时序信息进行建模。RMT-KD的关键设计在于如何选择合适的低维子空间,以及如何设计自蒸馏的损失函数,以保证学生模型能够有效地学习到教师模型的知识。具体的参数设置和网络结构的选择需要根据具体的任务和数据集进行调整。
🖼️ 关键图片


📊 实验亮点
论文提出了EigenTrack,一种实时检测幻觉的方法,能够在模型输出错误之前预警。同时,论文提出了RMT-KD,一种基于随机矩阵理论的知识蒸馏方法,能够在保持精度的前提下显著压缩模型,实现更低的计算成本和能源消耗。具体性能数据未知。
🎯 应用场景
该研究成果可应用于提升大型语言模型在各种实际场景中的可靠性和效率,例如智能客服、机器翻译、自动驾驶等。通过实时检测幻觉,可以避免模型产生错误或误导性的输出。通过模型压缩,可以降低模型的部署成本和能源消耗,使其更易于在移动设备或边缘设备上运行。此外,该研究也为理解深度神经网络的内部运作机制提供了新的思路。
📄 摘要(原文)
This thesis addresses two persistent and closely related challenges in modern deep learning, reliability and efficiency, through a unified framework grounded in Spectral Geometry and Random Matrix Theory (RMT). As deep networks and large language models continue to scale, their internal behavior becomes increasingly opaque, leading to hallucinations, fragile generalization under distribution shift, and growing computational and energy demands. By analyzing the eigenvalue dynamics of hidden activations across layers and inputs, this work shows that spectral statistics provide a compact, stable, and interpretable lens on model behavior, capable of separating structured, causal representations from noise-dominated variability. Within this framework, the first contribution, EigenTrack, introduces a real-time method for detecting hallucinations and out-of-distribution behavior in large language and vision-language models. EigenTrack transforms streaming activations into spectral descriptors such as entropy, variance, and deviations from the Marchenko-Pastur baseline, and models their temporal evolution using lightweight recurrent classifiers, enabling early detection of reliability failures before they appear in model outputs while offering interpretable insight into representation dynamics. The second contribution, RMT-KD, presents a principled approach to compressing deep networks via random matrix theoretic knowledge distillation. By interpreting outlier eigenvalues in activation spectra as carriers of task-relevant information, RMT-KD progressively projects networks onto lower-dimensional subspaces through iterative self-distillation, yielding significantly more compact and energy-efficient models while preserving accuracy and dense, hardware-friendly structure.