Integrating Machine Learning Ensembles and Large Language Models for Heart Disease Prediction Using Voting Fusion
作者: Md. Tahsin Amin, Tanim Ahmmod, Zannatul Ferdus, Talukder Naemul Hasan Naem, Ehsanul Ferdous, Arpita Bhattacharjee, Ishmam Ahmed Solaiman, Nahiyan Bin Noor
分类: cs.LG, cs.AI
发布日期: 2026-02-28
💡 一句话要点
融合机器学习集成模型与大语言模型,利用投票融合提升心脏病预测精度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 心脏病预测 机器学习集成 大语言模型 投票融合 临床决策支持
📋 核心要点
- 现有方法在处理复杂非线性医疗数据时存在局限性,需要更精确的风险分类和决策支持。
- 提出融合机器学习集成模型与大语言模型的混合方法,利用二者的优势互补,提升预测精度。
- 实验结果表明,该混合方法在心脏病预测中取得了更高的准确率和AUC,优于单独使用机器学习或大语言模型。
📝 摘要(中文)
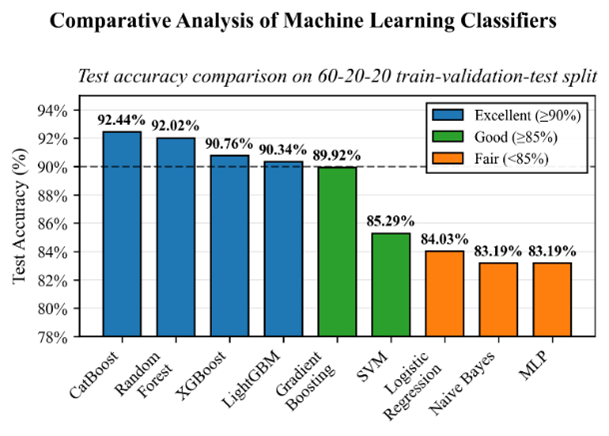
心血管疾病是全球首要死因,早期识别、精确风险分类和可靠的决策支持技术至关重要。尽管机器学习算法,特别是随机森林、XGBoost、LightGBM和CatBoost等集成方法,在建模复杂、非线性患者数据方面表现出色,且通常优于逻辑回归,但大型语言模型(LLM)的出现提供了新的零样本和少样本推理能力。本研究使用包含1190条患者记录的合并数据集预测心血管疾病,比较了传统机器学习模型(95.78%准确率,ROC-AUC 0.96)与通过OpenRouter API访问的开源大型语言模型。最终,在Gemini 2.5 Flash下,机器学习集成模型与LLM推理的混合融合取得了最佳结果(96.62%准确率,0.97 AUC),表明LLM(78.9%准确率)与机器学习模型结合使用效果最佳,而非单独使用。结果表明,机器学习集成模型取得了最高的性能(95.78%准确率,ROC-AUC 0.96),而LLM在零样本(78.9%)和少样本(72.6%)设置中表现一般。所提出的混合方法增强了在不确定情况下的优势,表明集成机器学习被认为是最佳的结构化表格预测案例,但它可以与混合ML-LLM系统集成,以提供少量增加,并为更可靠的临床决策支持工具开辟道路。
🔬 方法详解
问题定义:论文旨在解决心血管疾病预测精度不高的问题。现有方法,如传统的机器学习模型,虽然在结构化数据上表现良好,但缺乏利用外部知识进行推理的能力。而单独使用大语言模型,在医疗领域的专业知识方面存在不足,导致预测准确率较低。
核心思路:论文的核心思路是将机器学习集成模型(如随机森林、XGBoost等)与大语言模型(LLM)相结合,利用机器学习模型在结构化数据上的优势,以及LLM的推理能力,通过投票融合的方式,提升整体预测性能。这样可以弥补单一模型的不足,提高预测的鲁棒性和准确性。
技术框架:整体框架包括数据预处理、机器学习模型训练、LLM推理和投票融合四个主要阶段。首先,对包含患者信息的结构化数据进行预处理。然后,训练多个机器学习集成模型,并使用LLM进行零样本或少样本推理。最后,将机器学习模型和LLM的预测结果进行投票融合,得到最终的预测结果。使用的LLM通过OpenRouter APIs访问。
关键创新:论文的关键创新在于提出了将机器学习集成模型与大语言模型进行混合融合的方法,并采用投票融合策略。这种方法充分利用了两种模型的优势,克服了各自的局限性,从而提高了预测精度。此外,论文还探索了不同LLM在心脏病预测任务中的表现,并分析了其优缺点。
关键设计:论文的关键设计包括选择合适的机器学习集成模型(如随机森林、XGBoost、LightGBM、CatBoost),以及选择合适的LLM(如Gemini 2.5 Flash)。投票融合策略采用简单的多数投票规则,即选择预测结果中出现次数最多的类别作为最终预测结果。没有提及损失函数和网络结构的具体设计,可能使用了默认的参数设置。
🖼️ 关键图片


📊 实验亮点
实验结果表明,机器学习集成模型取得了95.78%的准确率和0.96的ROC-AUC。LLM在零样本设置下准确率为78.9%,在少样本设置下为72.6%。而将机器学习集成模型与LLM进行混合融合后,准确率提升至96.62%,ROC-AUC提升至0.97。该结果表明,混合融合方法能够有效提升心脏病预测的准确性。
🎯 应用场景
该研究成果可应用于临床决策支持系统,辅助医生进行心脏病早期诊断和风险评估,提高诊断效率和准确性。此外,该混合融合方法也可推广到其他医疗领域的预测任务中,例如癌症诊断、疾病预后等,具有广阔的应用前景和实际价值。未来,可以进一步探索更复杂的融合策略,并结合患者的病史、影像学资料等多模态数据,构建更智能化的医疗决策支持系统。
📄 摘要(原文)
Cardiovascular disease is the primary cause of death globally, necessitating early identification, precise risk classification, and dependable decision-support technologies. The advent of large language models (LLMs) provides new zero-shot and few-shot reasoning capabilities, even though machine learning (ML) algorithms, especially ensemble approaches like Random Forest, XGBoost, LightGBM, and CatBoost, are excellent at modeling complex, non-linear patient data and routinely beat logistic regression. This research predicts cardiovascular disease using a merged dataset of 1,190 patient records, comparing traditional machine learning models (95.78% accuracy, ROC-AUC 0.96) with open-source large language models via OpenRouter APIs. Finally, a hybrid fusion of the ML ensemble and LLM reasoning under Gemini 2.5 Flash achieved the best results (96.62% accuracy, 0.97 AUC), showing that LLMs (78.9 % accuracy) work best when combined with ML models rather than used alone. Results show that ML ensembles achieved the highest performance (95.78% accuracy, ROC-AUC 0.96), while LLMs performed moderately in zero-shot (78.9%) and slightly better in few-shot (72.6%) settings. The proposed hybrid method enhanced the strength in uncertain situations, illustrating that ensemble ML is considered the best structured tabular prediction case, but it can be integrated with hybrid ML-LLM systems to provide a minor increase and open the way to more reliable clinical decision-support tools.