RETLLM: Training and Data-Free MLLMs for Multimodal Information Retrieval
作者: Dawei Su, Dongsheng Wang
分类: cs.IR, cs.LG
发布日期: 2026-02-28
💡 一句话要点
提出RetLLM,一种无需训练和数据的多模态信息检索MLLM框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态信息检索 大型语言模型 零样本学习 提示学习 视觉增强
📋 核心要点
- 现有MMIR方法依赖对比微调,存在预训练不一致问题,且需要大量标注数据。
- RetLLM将MMIR建模为相似度评分任务,通过提示MLLM直接预测检索分数,无需训练数据。
- 实验表明,RetLLM在MMIR基准测试中优于微调模型,验证了其多模态推理能力。
📝 摘要(中文)
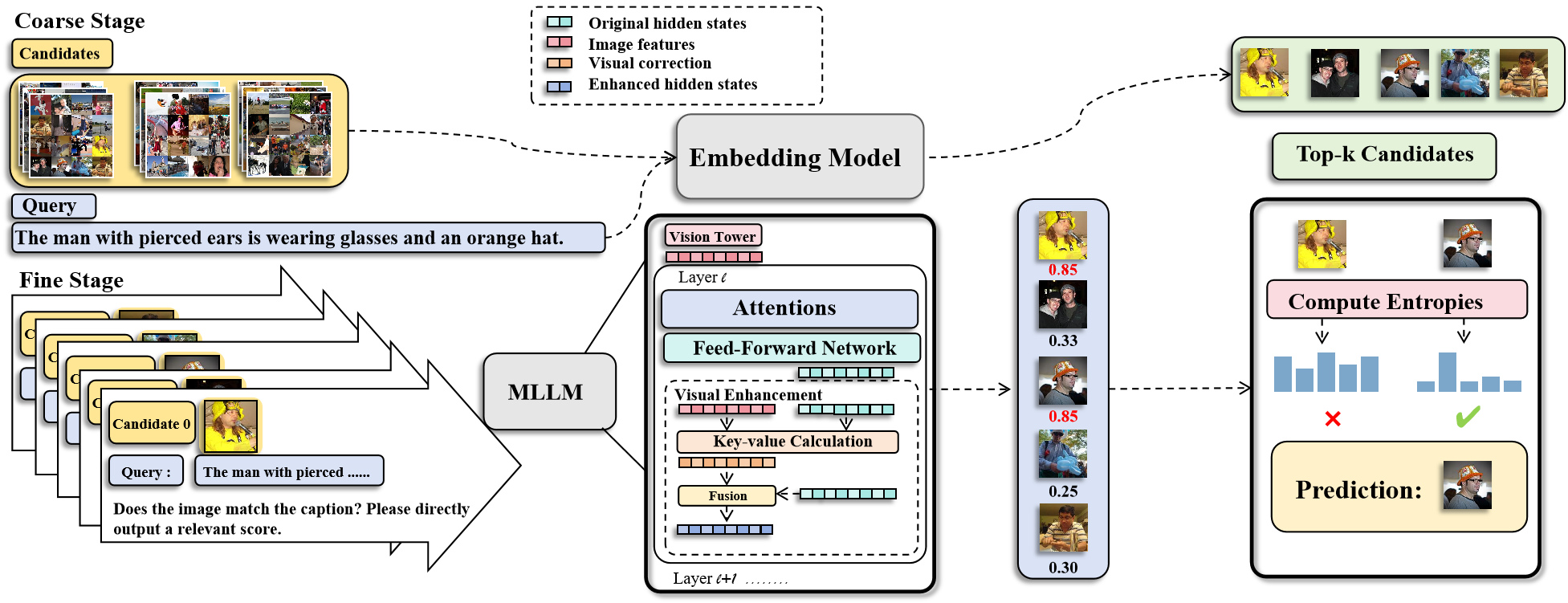
多模态信息检索(MMIR)因其处理文本、图像或混合查询和候选对象的灵活性而备受关注。最近,多模态大型语言模型(MLLM)的突破通过在对比微调框架下结合MLLM知识,提高了MMIR的性能。然而,它们受到预训练不一致性的影响,并且需要大型数据集。本文介绍了一种新颖的框架RetLLM,旨在以无需训练和数据的方式查询MLLM以进行MMIR。具体来说,我们将MMIR定义为相似度得分生成任务,并提示MLLM直接在由粗到精的流程中预测检索得分。在粗略阶段,top-k过滤策略为每个查询构建一个小的但高质量的候选池,使MLLM能够专注于语义相关的候选对象。随后,通过在精细阶段将查询和候选对象都输入到MLLM中来预测检索得分。重要的是,我们在推理过程中提出了一个视觉增强模块,以帮助MLLM重新拾取被遗忘的视觉信息,从而改进检索。在MMIR基准上的大量实验表明,RetLLM优于微调模型。消融研究进一步验证了每个组件。我们的工作表明,MLLM可以在没有任何训练的情况下实现强大的MMIR性能,突出了它们在一个简单、可扩展的框架中固有的多模态推理能力。
🔬 方法详解
问题定义:论文旨在解决多模态信息检索(MMIR)中,现有方法依赖大量标注数据进行对比学习和微调,导致训练成本高昂,且容易受到预训练数据与下游任务数据分布不一致性影响的问题。现有方法难以充分利用MLLM本身蕴含的知识和推理能力。
核心思路:论文的核心思路是利用MLLM强大的多模态理解和推理能力,将MMIR任务转化为一个相似度评分预测问题,通过设计合适的Prompt,直接让MLLM对查询和候选文档之间的相关性进行打分,从而避免了传统的对比学习和微调过程。这样可以充分利用MLLM的预训练知识,并减少对标注数据的依赖。
技术框架:RetLLM框架包含两个主要阶段:粗略筛选阶段和精细评分阶段。在粗略筛选阶段,使用Top-K过滤策略,为每个查询构建一个小的但高质量的候选池,减少后续MLLM需要处理的候选文档数量。在精细评分阶段,将查询和候选文档输入到MLLM中,通过Prompt引导MLLM预测检索得分。此外,还包含一个视觉增强模块,用于在推理过程中帮助MLLM重新关注重要的视觉信息。
关键创新:RetLLM的关键创新在于提出了一个完全无需训练和数据的MMIR框架,充分利用了MLLM的固有能力。通过将MMIR任务建模为相似度评分预测问题,并设计了粗略筛选和精细评分相结合的流程,实现了高效且准确的多模态信息检索。视觉增强模块进一步提升了检索性能。
关键设计:在粗略筛选阶段,Top-K过滤策略的选择会影响候选池的质量和大小。在精细评分阶段,Prompt的设计至关重要,需要引导MLLM正确理解查询和候选文档,并准确预测相似度得分。视觉增强模块的具体实现方式(例如,使用注意力机制重新加权视觉特征)也会影响最终的检索效果。论文中具体参数设置、损失函数和网络结构等细节未知。
🖼️ 关键图片

📊 实验亮点
RetLLM在MMIR基准测试中取得了显著的性能提升,优于经过微调的模型。消融实验验证了每个组件的有效性,特别是视觉增强模块对检索性能的贡献。该研究表明,即使没有训练数据,MLLM也能在MMIR任务中表现出色,突显了其强大的多模态推理能力。具体性能数据和对比基线未知。
🎯 应用场景
RetLLM可应用于各种多模态信息检索场景,例如图像搜索、视频搜索、跨模态文档检索等。该方法无需训练数据,降低了应用门槛,可以快速部署到新的领域。未来,可以进一步探索如何利用RetLLM进行更复杂的推理和决策,例如多轮对话式信息检索。
📄 摘要(原文)
Multimodal information retrieval (MMIR) has gained attention for its flexibility in handling text, images, or mixed queries and candidates. Recent breakthroughs in multimodal large language models (MLLMs) boost MMIR performance by incorporating MLLM knowledge under the contrastive finetuning framework. However, they suffer from pre-training inconsistency and require large datasets. In this work, we introduce a novel framework, RetLLM, designed to query MLLMs for MMIR in a training- and data-free manner. Specifically, we formulate MMIR as a similarity score generation task and prompt MLLMs to directly predict retrieval scores in a coarse-then-fine pipeline. At the coarse stage, a top-k filtering strategy builds a small yet high-quality candidate pool for each query, enabling MLLMs to focus on semantically relevant candidates. Subsequently, the retrieval score is predicted by feeding both the query and candidate into MLLMs at the fine stage. Importantly, we propose a visual enhancement module during reasoning to help MLLMs re-pick forgotten visuals, improving retrieval. Extensive experiments on MMIR benchmarks show that RetLLM outperforms fine-tuned models. Ablation studies further verify each component. Our work demonstrates that MLLMs can achieve strong MMIR performance without any training, highlighting their inherent multimodal reasoning ability in a simple, scalable framework. We release our code at:this https URL