Support Tokens, Stability Margins, and a New Foundation for Robust LLMs
作者: Deepak Agarwal, Dhyey Dharmendrakumar Mavani, Suyash Gupta, Karthik Sethuraman, Tejas Dharamsi
分类: cs.LG, math.PR, math.ST
发布日期: 2026-02-28
💡 一句话要点
提出基于支持Token和稳定裕度的鲁棒LLM新框架,提升模型稳定性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 自注意力机制 鲁棒性 支持Token 稳定裕度 概率模型 贝叶斯框架
📋 核心要点
- 现有LLM在自注意力机制中存在潜在的不稳定性,影响模型的鲁棒性。
- 论文提出基于概率框架的LLM新解释,引入支持token和稳定裕度的概念。
- 通过在训练中加入对数障碍惩罚,提升模型鲁棒性,同时保持准确率。
📝 摘要(中文)
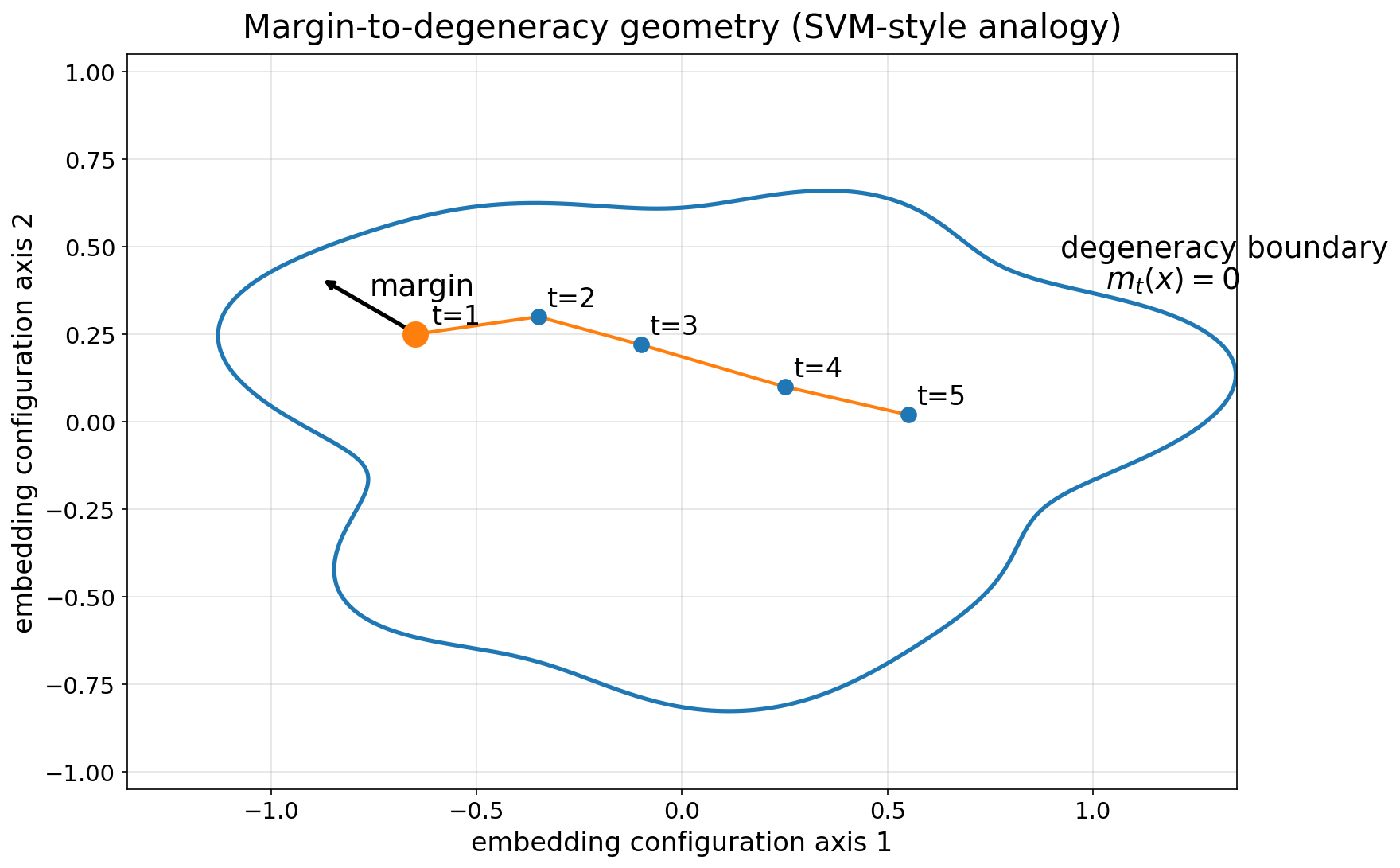
本文从概率框架重新解读了因果自注意力Transformer,这是现代基础模型的核心。这种重新表述揭示了一个令人惊讶的结构性见解:由于变量变换现象,自注意力参数上出现了一个障碍约束。这在token空间上诱导出一个高度结构化的几何,为LLM解码的动态提供了理论见解。这揭示了一个注意力变得病态的边界,从而产生类似于经典支持向量机的裕度解释。就像支持向量一样,这自然地产生了支持token的概念。此外,本文表明LLM可以被解释为token空间幂集上的随机过程,为序列建模提供了一个严格的概率框架。本文提出了一个贝叶斯框架,并推导出一个MAP估计目标,该目标仅需对标准LLM训练进行最小的修改:在通常的交叉熵损失中添加一个平滑的对数障碍惩罚。实验表明,这提供了更鲁棒的模型,而不会牺牲样本外准确性,并且在实践中易于整合。
🔬 方法详解
问题定义:现有大型语言模型(LLM)的自注意力机制在某些情况下可能变得不稳定,导致模型预测结果的波动或错误。现有的训练方法未能充分解决这一问题,缺乏对自注意力参数的约束,从而影响了模型的鲁棒性。
核心思路:论文的核心思路是将因果自注意力Transformer重新解释为一个概率模型,并在此基础上发现自注意力参数上的障碍约束。通过引入支持token和稳定裕度的概念,类比支持向量机,旨在提高模型的稳定性和鲁棒性。通过在损失函数中加入对数障碍惩罚,约束自注意力参数,避免其进入不稳定区域。
技术框架:该方法主要包含以下几个阶段:1) 将LLM的自注意力机制重新表述为概率模型;2) 推导自注意力参数上的障碍约束;3) 引入支持token和稳定裕度的概念;4) 构建贝叶斯框架,并推导出MAP估计目标;5) 在标准LLM训练的交叉熵损失中添加平滑的对数障碍惩罚。
关键创新:最重要的技术创新点在于发现了自注意力参数上的障碍约束,并将其与支持向量机的裕度概念联系起来。这种联系为理解LLM的稳定性和鲁棒性提供了一个新的视角。此外,将LLM解释为token空间幂集上的随机过程,为序列建模提供了一个严格的概率框架。
关键设计:关键的设计包括:1) 对数障碍惩罚函数的选择,需要保证其平滑性,避免引入不必要的优化难度;2) 惩罚系数的设置,需要在鲁棒性和准确率之间进行权衡;3) 支持token的定义和选择,需要能够代表token空间的关键信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,通过在标准LLM训练中加入对数障碍惩罚,可以显著提高模型的鲁棒性,而不会牺牲样本外准确性。具体性能数据未知,但论文强调该方法在实践中易于整合,具有较强的应用潜力。
🎯 应用场景
该研究成果可应用于各种需要高稳定性和鲁棒性的自然语言处理任务,例如机器翻译、文本摘要、对话系统等。通过提升LLM的鲁棒性,可以减少模型在实际应用中出现错误或异常情况的概率,提高用户体验和系统可靠性。此外,该研究为理解和改进LLM的自注意力机制提供了新的思路。
📄 摘要(原文)
Self-attention is usually described as a flexible, content-adaptive way to mix a token with information from its past. We re-interpret causal self-attention transformers, the backbone of modern foundation models, within a probabilistic framework, much like how classical PCA is extended to probabilistic PCA. However, this re-formulation reveals a surprising and deeper structural insight: due to a change-of-variables phenomenon, a barrier constraint emerges on the self-attention parameters. This induces a highly structured geometry on the token space, providing theoretical insights into the dynamics of LLM decoding. This reveals a boundary where attention becomes ill-conditioned, leading to a margin interpretation similar to classical support vector machines. Just like support vectors, this naturally gives rise to the concept of support tokens.Furthermore, we show that LLMs can be interpreted as a stochastic process over the power set of the token space, providing a rigorous probabilistic framework for sequence modeling. We propose a Bayesian framework and derive a MAP estimation objective that requires only a minimal modification to standard LLM training: the addition of a smooth log-barrier penalty to the usual cross-entropy loss. We demonstrate that this provides more robust models without sacrificing out-of-sample accuracy and that it is straightforward to incorporate in practice.