AngelSlim: A more accessible, comprehensive, and efficient toolkit for large model compression
作者: Rui Cen, QiangQiang Hu, Hong Huang, Hong Liu, Song Liu, Xin Luo, Lin Niu, Yifan Tan, Decheng Wu, Linchuan Xie, Rubing Yang, Guanghua Yu, Jianchen Zhu
分类: cs.LG, cs.AI
发布日期: 2026-02-28
💡 一句话要点
AngelSlim:腾讯混元团队推出的大模型压缩工具包,提升效率与可及性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大模型压缩 量化 推测解码 稀疏注意力 多模态学习 模型部署 工具包
📋 核心要点
- 现有大模型部署面临高计算成本和内存需求挑战,阻碍了其在资源受限环境中的应用。
- AngelSlim通过集成量化、推测解码和token剪枝等多种压缩技术,提供统一的压缩和部署流程。
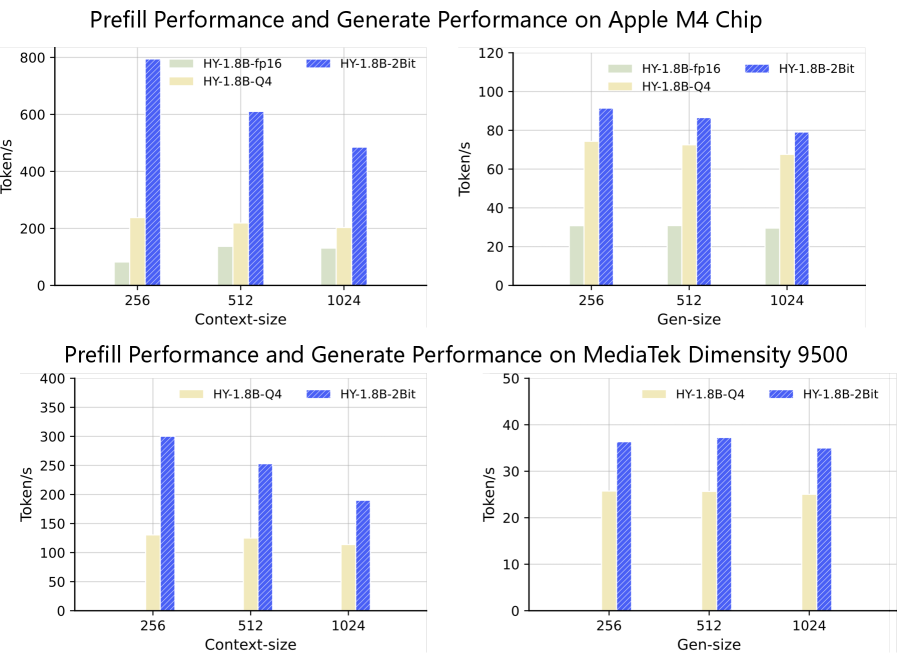
- 实验表明,AngelSlim在吞吐量和首token时间上均有显著提升,并支持工业级2比特量化模型。
📝 摘要(中文)
本技术报告介绍了AngelSlim,这是腾讯混元团队开发的一款全面且多功能的大模型压缩工具包。通过整合包括量化、推测解码、token剪枝和蒸馏等前沿算法,AngelSlim提供了一个统一的流程,简化了从模型压缩到工业规模部署的过渡。为了促进高效加速,我们集成了最先进的FP8和INT8后训练量化(PTQ)算法,以及超低比特领域的前沿研究,其中HY-1.8B-int2是首个工业上可行的2比特大型模型。除了量化之外,我们还提出了一个与训练对齐的推测解码框架,该框架与多模态架构和现代推理引擎兼容,在不影响输出正确性的前提下,实现了1.8倍至2.0倍的吞吐量提升。此外,我们开发了一种无需训练的稀疏注意力框架,通过将稀疏核与模型架构分离,利用静态模式和动态token选择的混合,减少了长上下文场景中的首token时间(TTFT)。对于多模态模型,AngelSlim集成了专门的剪枝策略,即用于通过最大边缘相关性优化视觉token的IDPruner,以及用于自适应音频token合并和剪枝的Samp。通过整合这些来自底层实现的压缩策略,AngelSlim实现了以算法为中心的研究和工具辅助的部署。
🔬 方法详解
问题定义:现有大模型在部署时面临着计算资源消耗大、推理速度慢的问题,尤其是在长文本和多模态场景下,效率瓶颈更加明显。现有的压缩方法往往是孤立的,缺乏统一的框架支持,难以快速部署和验证。
核心思路:AngelSlim的核心思路是提供一个全面、易用且高效的大模型压缩工具包,通过整合多种先进的压缩算法,并提供统一的pipeline,降低模型压缩和部署的门槛。该工具包旨在支持算法研究和工业部署,实现性能和效率的平衡。
技术框架:AngelSlim包含以下主要模块:1) 量化模块,支持FP8、INT8以及超低比特量化;2) 推测解码模块,提供训练对齐的推测解码框架;3) 稀疏注意力模块,用于减少长上下文场景中的TTFT;4) 多模态模型压缩模块,包含IDPruner和Samp等剪枝策略。这些模块共同构成了一个完整的模型压缩流程。
关键创新:AngelSlim的关键创新在于:1) 整合了多种先进的压缩算法,提供统一的pipeline;2) 提出了训练对齐的推测解码框架,兼容多模态架构;3) 开发了无需训练的稀疏注意力框架,降低TTFT;4) 实现了工业可用的2比特量化大模型。这些创新使得AngelSlim在压缩效率和易用性方面具有显著优势。
关键设计:在量化方面,AngelSlim支持多种量化策略,包括PTQ和训练感知量化。推测解码框架通过与训练过程对齐,保证了输出的正确性。稀疏注意力框架采用静态模式和动态token选择的混合策略,平衡了计算复杂度和性能。IDPruner利用最大边缘相关性选择视觉token,Samp自适应地合并和剪枝音频token。
🖼️ 关键图片


📊 实验亮点
AngelSlim实现了多个实验亮点:1) 实现了工业可用的2比特量化大模型HY-1.8B-int2;2) 推测解码框架在不影响输出正确性的前提下,实现了1.8倍至2.0倍的吞吐量提升;3) 稀疏注意力框架有效降低了长上下文场景中的首token时间(TTFT)。这些结果表明AngelSlim在模型压缩和加速方面具有显著优势。
🎯 应用场景
AngelSlim可广泛应用于自然语言处理、计算机视觉和多模态学习等领域。它可以帮助企业和研究机构更高效地部署大模型,降低计算成本,提升推理速度,从而加速人工智能技术的落地和应用。例如,在智能客服、机器翻译、图像识别等场景中,AngelSlim可以显著提升用户体验。
📄 摘要(原文)
This technical report introduces AngelSlim, a comprehensive and versatile toolkit for large model compression developed by the Tencent Hunyuan team. By consolidating cutting-edge algorithms, including quantization, speculative decoding, token pruning, and distillation. AngelSlim provides a unified pipeline that streamlines the transition from model compression to industrial-scale deployment. To facilitate efficient acceleration, we integrate state-of-the-art FP8 and INT8 Post-Training Quantization (PTQ) algorithms alongside pioneering research in ultra-low-bit regimes, featuring HY-1.8B-int2 as the first industrially viable 2-bit large model. Beyond quantization, we propose a training-aligned speculative decoding framework compatible with multimodal architectures and modern inference engines, achieving 1.8x to 2.0x throughput gains without compromising output correctness. Furthermore, we develop a training-free sparse attention framework that reduces Time-to-First-Token (TTFT) in long-context scenarios by decoupling sparse kernels from model architectures through a hybrid of static patterns and dynamic token selection. For multimodal models, AngelSlim incorporates specialized pruning strategies, namely IDPruner for optimizing vision tokens via Maximal Marginal Relevance and Samp for adaptive audio token merging and pruning. By integrating these compression strategies from low-level implementations, AngelSlim enables algorithm-focused research and tool-assisted deployment.