Decision MetaMamba: Enhancing Selective SSM in Offline RL with Heterogeneous Sequence Mixing
作者: Wall Kim, Chaeyoung Song, Hanul Kim
分类: cs.LG, cs.AI
发布日期: 2026-02-28
💡 一句话要点
Decision MetaMamba:异构序列混合增强离线强化学习中的选择性SSM
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 Mamba模型 选择性扫描 序列混合 决策序列 强化学习 状态空间模型
📋 核心要点
- Mamba模型在离线强化学习中表现出色,但其选择性机制在关键步骤缺失时会造成信息损失。
- Decision MetaMamba (DMM)通过密集层序列混合器和改进的位置结构,在Mamba之前进行全局信息融合,避免信息丢失。
- 实验表明,DMM在多种强化学习任务中取得了领先性能,同时保持了较小的参数规模,利于实际应用。
📝 摘要(中文)
基于Mamba的模型在离线强化学习中备受关注。然而,当强化学习序列中的关键步骤被省略时,它们的选择机制通常会产生不利影响。为了解决这些问题,我们提出了一种简单而有效的结构,称为Decision MetaMamba (DMM),它用基于密集层的序列混合器取代了Mamba的token混合器,并修改了位置结构以保留局部信息。通过在Mamba之前执行同时考虑所有通道的序列混合,DMM可以防止由于选择性扫描和残差门控导致的信息丢失。大量的实验表明,我们的DMM在各种强化学习任务中都实现了最先进的性能。此外,DMM以紧凑的参数规模实现了这些结果,展示了在实际应用中的强大潜力。
🔬 方法详解
问题定义:现有基于Mamba的离线强化学习模型,由于其选择性扫描机制,在处理不完整或关键步骤缺失的序列时,容易丢失重要信息,导致性能下降。尤其是在决策序列中,关键决策步骤的遗漏会严重影响策略学习。
核心思路:DMM的核心思路是在Mamba模型之前,引入一个全局的序列混合层,该层能够同时考虑所有通道的信息,从而弥补选择性扫描可能导致的信息丢失。通过这种方式,模型可以在进行选择性扫描之前,先对序列进行充分的全局信息融合。
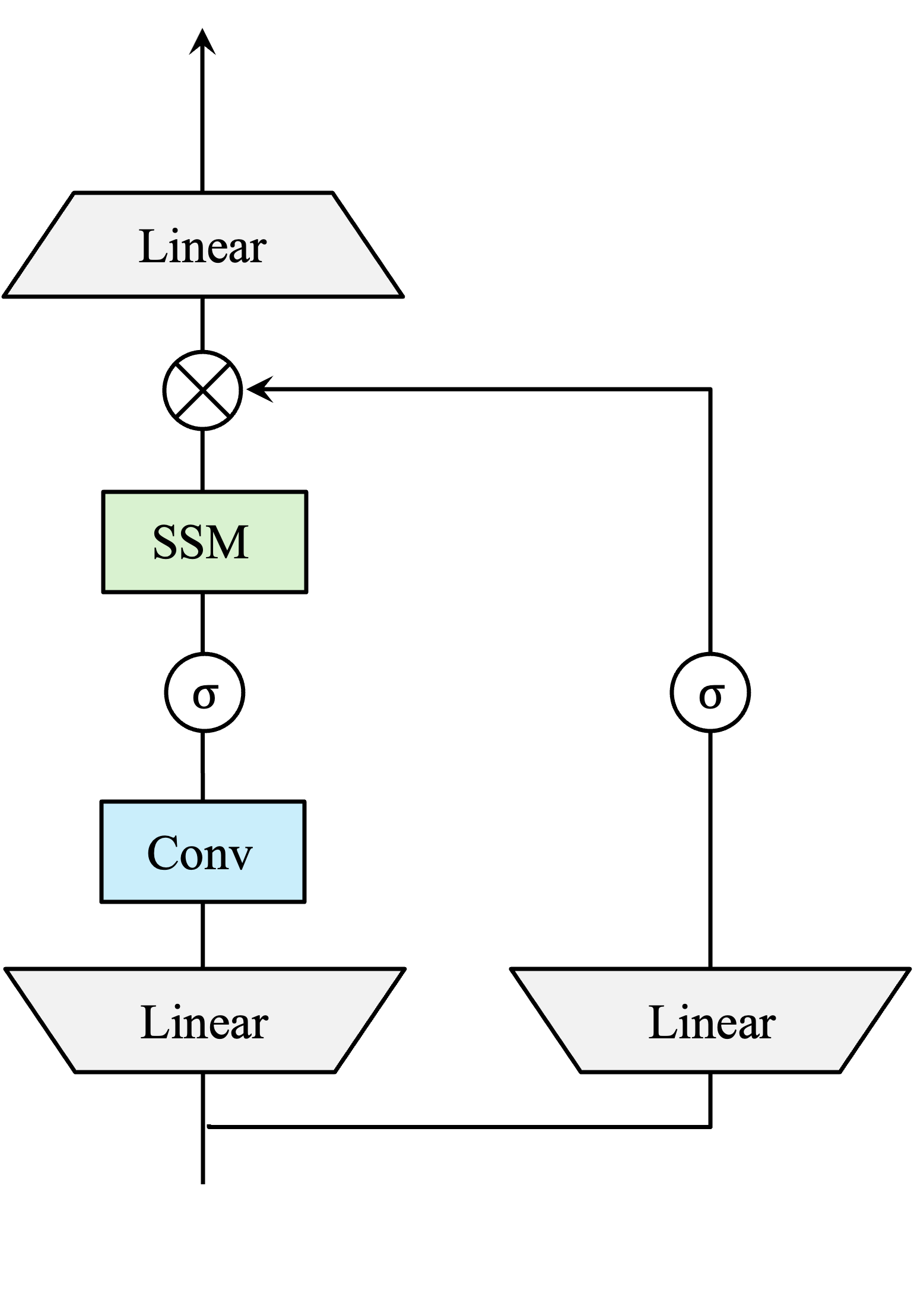
技术框架:DMM主要由三个部分组成:输入嵌入层、序列混合层和Mamba层。输入嵌入层将状态、动作等信息映射到高维空间。序列混合层使用一个基于密集层的网络,对所有通道的信息进行混合。Mamba层则进行选择性扫描,提取序列中的关键信息。整体流程是:输入 -> 嵌入 -> 序列混合 -> Mamba -> 输出。
关键创新:DMM的关键创新在于使用密集层进行序列混合,替代了Mamba原有的token混合器。这种全局混合方式能够有效防止信息丢失,尤其是在处理不完整序列时。此外,DMM还修改了位置结构,以更好地保留局部信息。
关键设计:序列混合层使用一个多层感知机(MLP),输入是整个序列的嵌入表示,输出是混合后的序列表示。位置编码采用相对位置编码,以增强模型对局部信息的感知能力。损失函数采用标准的策略梯度损失函数,优化目标是最大化累积奖励。
🖼️ 关键图片
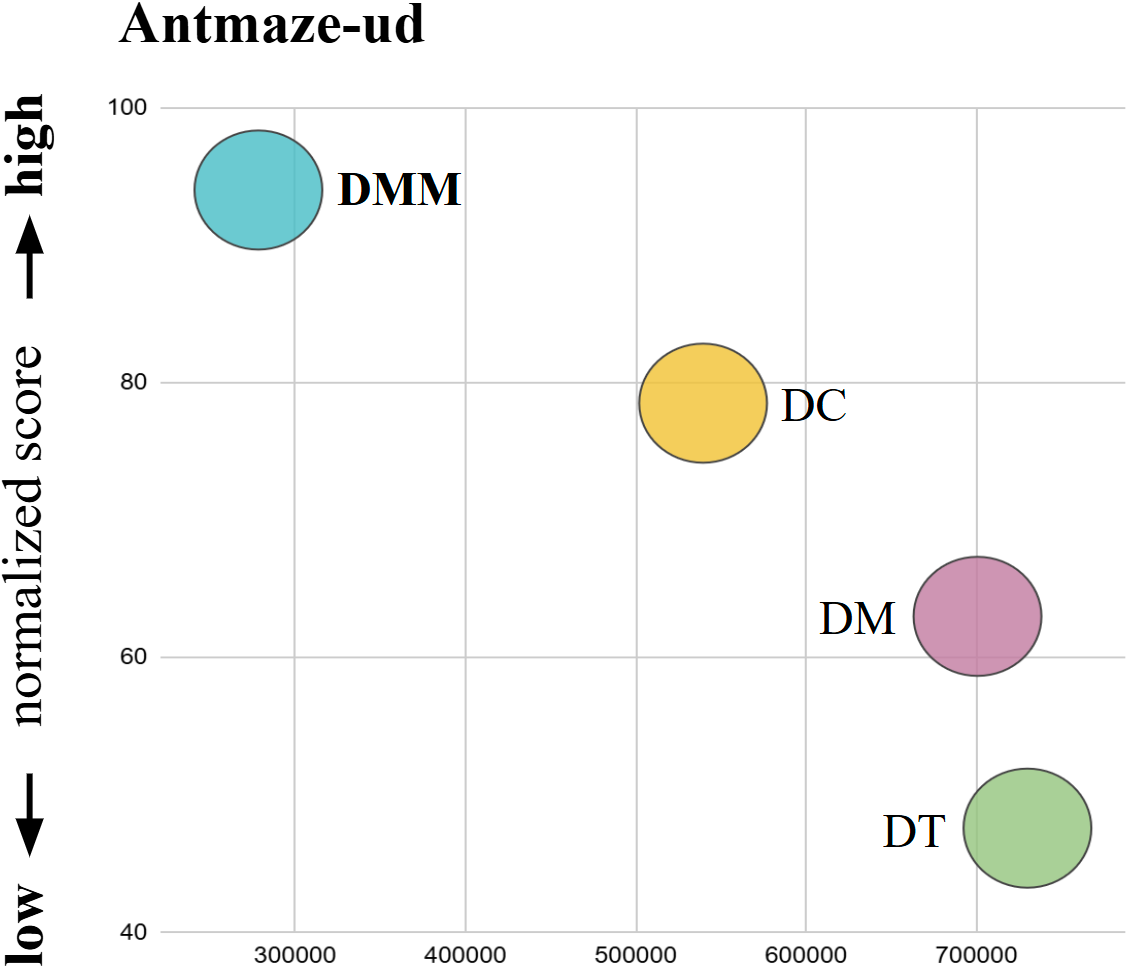
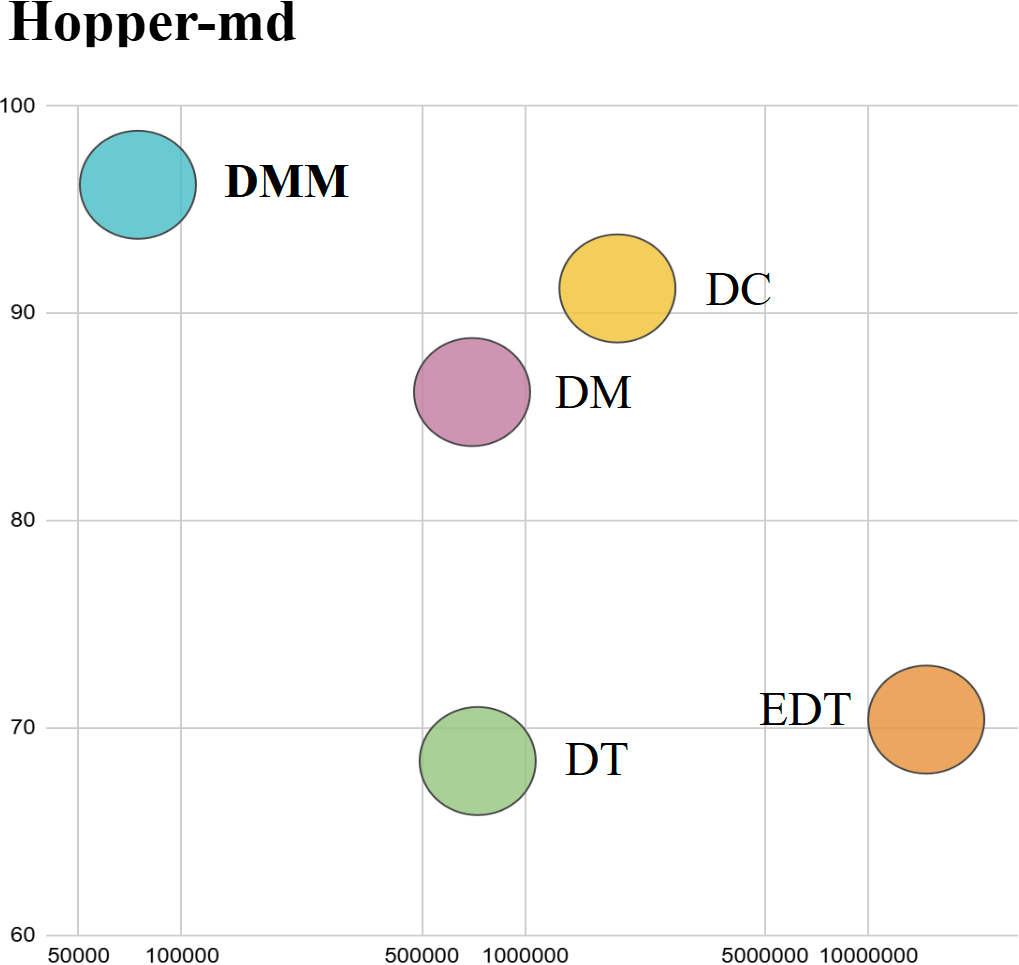
📊 实验亮点
实验结果表明,DMM 在多个离线强化学习任务中取得了最先进的性能。例如,在 D4RL 基准测试中,DMM 在多个环境上的平均得分显著优于其他基线方法,包括基于 Transformer 的模型和原始的 Mamba 模型。此外,DMM 在保持高性能的同时,参数规模相对较小,这使得它更易于部署到实际应用中。
🎯 应用场景
Decision MetaMamba (DMM) 在离线强化学习领域具有广泛的应用前景,例如机器人控制、自动驾驶、推荐系统和金融交易等。通过利用离线数据进行策略学习,DMM 可以帮助智能体在复杂环境中做出更优的决策,降低试错成本,并提高学习效率。未来,DMM 有望应用于更多需要从历史数据中学习策略的实际场景。
📄 摘要(原文)
Mamba-based models have drawn much attention in offline RL. However, their selective mechanism often detrimental when key steps in RL sequences are omitted. To address these issues, we propose a simple yet effective structure, called Decision MetaMamba (DMM), which replaces Mamba's token mixer with a dense layer-based sequence mixer and modifies positional structure to preserve local information. By performing sequence mixing that considers all channels simultaneously before Mamba, DMM prevents information loss due to selective scanning and residual gating. Extensive experiments demonstrate that our DMM delivers the state-of-the-art performance across diverse RL tasks. Furthermore, DMM achieves these results with a compact parameter footprint, demonstrating strong potential for real-world applications.