ÜberWeb: Insights from Multilingual Curation for a 20-Trillion-Token Dataset
作者: DatologyAI, Aldo Gael Carranza, Kaleigh Mentzer, Ricardo Pio Monti, Alex Fang, Alvin Deng, Amro Abbas, Anshuman Suri, Brett Larsen, Cody Blakeney, Darren Teh, David Schwab, Diego Kiner, Fan Pan, Haakon Mongstad, Haoli Yin, Jack Urbanek, Jason Lee, Jason Telanoff, Josh Wills, Luke Merrick, Maximilian Böther, Parth Doshi, Paul Burstein, Pratyush Maini, Rishabh Adiga, Siddharth Joshi, Spandan Das, Tony Jiang, Vineeth Dorna, Zhengping Wang, Bogdan Gaza, Ari Morcos, Matthew Leavitt
分类: cs.LG
发布日期: 2026-02-28
💡 一句话要点
ÜberWeb:通过多语言数据清洗,构建20万亿token数据集,提升多语言模型性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言模型 数据清洗 数据配比 预训练 自然语言处理
📋 核心要点
- 现有方法在多语言模型训练中面临数据质量不均和“多语言诅咒”导致的性能干扰问题。
- 论文提出通过多语言数据清洗,优化数据质量和组成,缓解多语言干扰,提升模型性能。
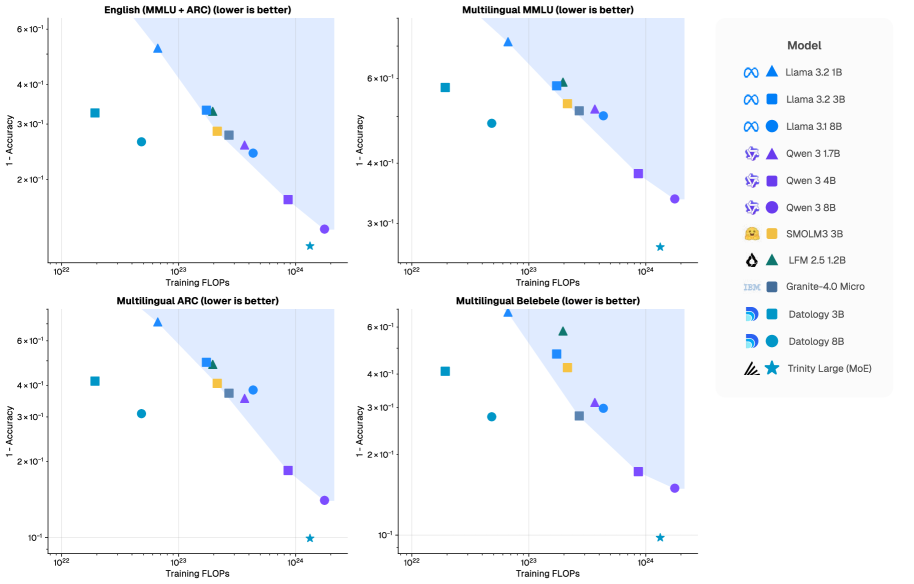
- 实验表明,精心策划的多语言数据分配(<8% token)能显著提升模型性能,并建立了新的性能-计算帕累托前沿。
📝 摘要(中文)
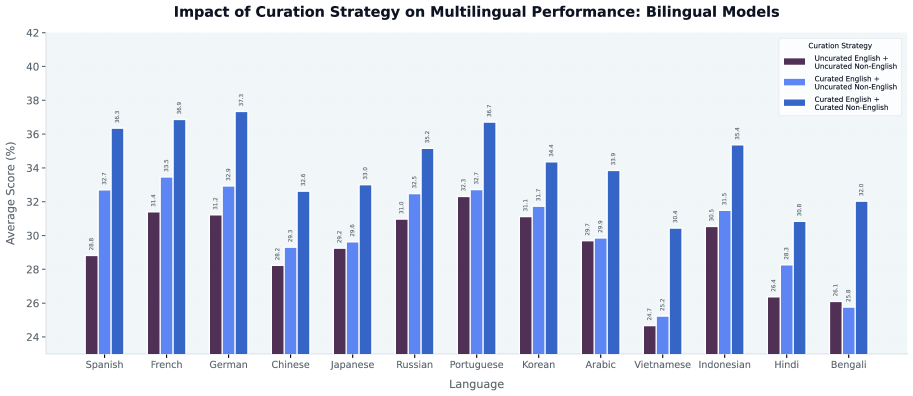
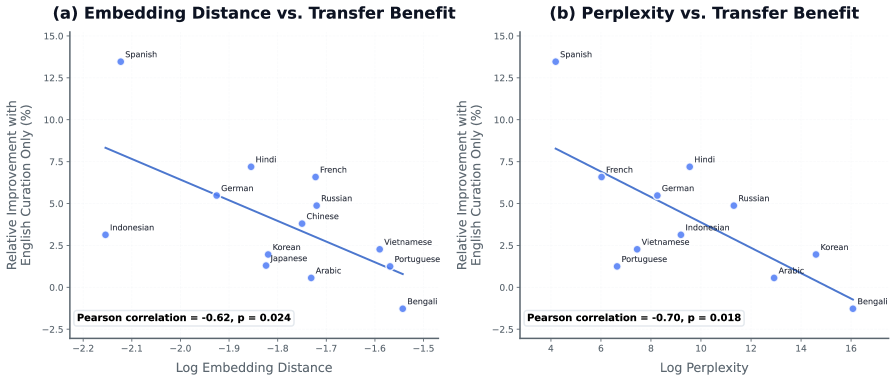
多语言能力是现代基础模型的核心,但由于各语言数据可用性不均,训练高质量的多语言模型仍然具有挑战性。另一个挑战是联合多语言训练中可能出现的性能干扰,通常被称为“多语言诅咒”。我们研究了跨13种语言的多语言数据清洗,发现许多报告的性能下降并非多语言扩展固有的,而是源于数据质量和组成的缺陷,而非根本的容量限制。在受控的双语实验中,提高任何一种语言的数据质量都有利于其他语言:清洗英语可以提高13种语言中12种非英语语言的性能,而清洗非英语语言也会对英语产生互惠的改进。定制的每种语言清洗会产生更大的语言内部改进。将这些发现扩展到大规模通用训练混合中,我们表明,包含不到总token 8%的精心策划的多语言分配仍然非常有效。我们在一个完全来自公共来源的20T-token预训练语料库的构建工作中实施了这种方法。在1T-token随机子集上训练的具有3B和8B参数的模型,以比强大的公共基线少4-10倍的训练FLOPs实现了具有竞争力的多语言准确性,从而在多语言性能与计算之间建立了新的帕累托前沿。此外,这些优势扩展到了前沿模型规模:20T-token语料库是Trinity Large(400B/A13B)预训练数据集的一部分,相对于其训练FLOPs,Trinity Large表现出强大的多语言性能。这些结果表明,有针对性的、每种语言的数据清洗可以减轻多语言干扰,并实现计算高效的多语言扩展。
🔬 方法详解
问题定义:论文旨在解决多语言模型训练中因数据质量和组成不佳导致的性能下降问题,即“多语言诅咒”。现有方法在处理多语言数据时,往往忽略了各语言数据质量的差异,导致模型在某些语言上表现不佳。此外,简单的混合多语言数据进行训练,容易造成语言间的干扰,降低整体性能。
核心思路:论文的核心思路是通过精细化的多语言数据清洗和配比,提高训练数据的质量和多样性,从而缓解多语言干扰,提升模型在所有语言上的性能。核心在于针对每种语言的特点进行定制化的数据清洗,并合理分配各语言数据在训练集中的比例。
技术框架:论文的技术框架主要包括以下几个阶段:1) 数据收集:从公共来源收集多语言数据。2) 数据清洗:针对每种语言,进行定制化的数据清洗,包括去除低质量文本、过滤有害内容等。3) 数据配比:根据各语言的特点和重要性,合理分配各语言数据在训练集中的比例。4) 模型训练:使用清洗后的多语言数据训练模型。5) 性能评估:在多个多语言benchmark上评估模型性能。
关键创新:论文的关键创新在于提出了精细化的多语言数据清洗和配比方法,能够有效缓解多语言干扰,提升模型在所有语言上的性能。与现有方法相比,该方法更加注重数据质量和多样性,能够更好地利用多语言数据。
关键设计:论文的关键设计包括:1) 针对每种语言,设计不同的数据清洗规则,例如,针对英语,可以去除语法错误较多的文本;针对某些低资源语言,可以进行数据增强。2) 根据各语言的特点和重要性,合理分配各语言数据在训练集中的比例,例如,对于重要的语言,可以增加其在训练集中的比例;对于低资源语言,可以进行过采样。
🖼️ 关键图片
📊 实验亮点
论文实验结果表明,通过精心策划的多语言数据分配(<8% token),在1T-token随机子集上训练的3B和8B参数模型,能够以比现有方法少4-10倍的训练FLOPs,达到具有竞争力的多语言准确性。此外,20T-token语料库被用于训练Trinity Large (400B/A13B),展现出强大的多语言性能。
🎯 应用场景
该研究成果可应用于各种需要多语言能力的人工智能系统,如多语言机器翻译、跨语言信息检索、多语言对话系统等。通过提升多语言模型的性能,可以更好地服务于全球用户,促进不同语言文化之间的交流与理解。此外,该研究提出的数据清洗和配比方法,也可以为其他多语言任务提供参考。
📄 摘要(原文)
Multilinguality is a core capability for modern foundation models, yet training high-quality multilingual models remains challenging due to uneven data availability across languages. A further challenge is the performance interference that can arise from joint multilingual training, commonly referred to as the "curse of multilinguality". We study multilingual data curation across thirteen languages and find that many reported regressions are not inherent to multilingual scaling but instead stem from correctable deficiencies in data quality and composition rather than fundamental capacity limits. In controlled bilingual experiments, improving data quality for any single language benefits others: curating English improves non-English performance in 12 of 13 languages, while curating non-English yields reciprocal improvements in English. Bespoke per-language curation produces substantially larger within-language improvements. Extending these findings to large-scale general-purpose training mixtures, we show that curated multilingual allocations comprising under 8% of total tokens remain remarkably effective. We operationalize this approach within an effort that produced a 20T-token pretraining corpus derived entirely from public sources. Models with 3B and 8B parameters trained on a 1T-token random subset achieve competitive multilingual accuracy with 4-10x fewer training FLOPs than strong public baselines, establishing a new Pareto frontier in multilingual performance versus compute. Moreover, these benefits extend to frontier model scale: the 20T-token corpus served as part of the pretraining dataset for Trinity Large (400B/A13B), which exhibits strong multilingual performance relative to its training FLOPs. These results show that targeted, per-language data curation mitigates multilingual interference and enables compute-efficient multilingual scaling.