Symmetry in language statistics shapes the geometry of model representations
作者: Dhruva Karkada, Daniel J. Korchinski, Andres Nava, Matthieu Wyart, Yasaman Bahri
分类: cs.LG, cs.CL
发布日期: 2026-02-28
💡 一句话要点
揭示语言模型表征几何结构的对称性起源,源于语言统计中的平移对称性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 表征学习 几何结构 对称性 词嵌入 流形学习 统计语言模型
📋 核心要点
- 语言模型内部表征呈现出有趣的几何结构,但其内在机制尚不明确,现有方法缺乏对这种现象的解释。
- 论文提出语言统计中的平移对称性是模型表征几何结构的关键驱动因素,并从理论上推导了词表征的流形几何。
- 实验结果表明,理论预测与大型语言模型和文本嵌入模型的结果一致,并且该几何结构对统计扰动具有鲁棒性。
📝 摘要(中文)
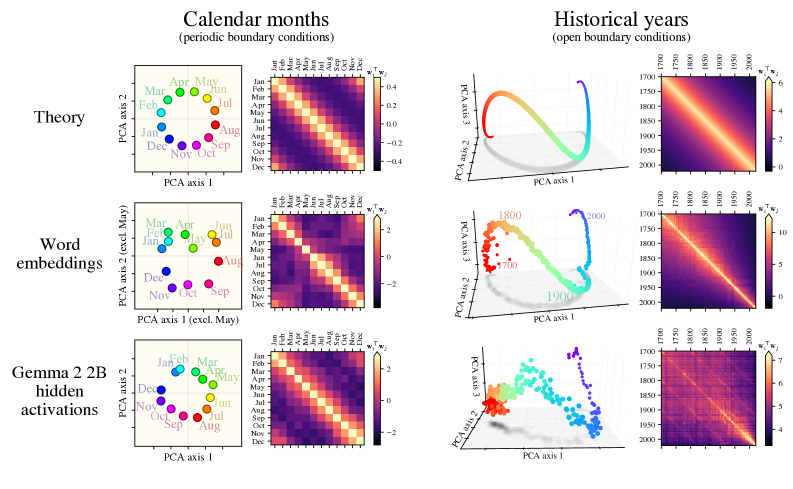
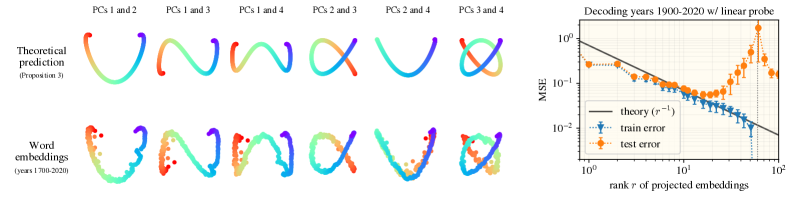
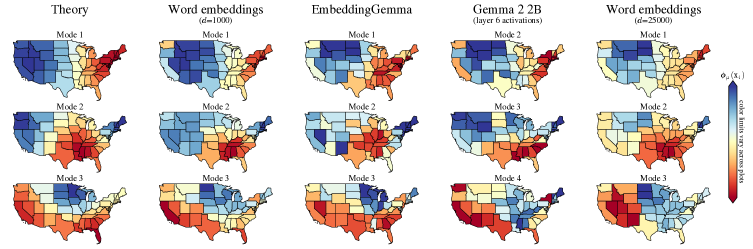
本文旨在解释语言模型学习到的内部表征所展现出的显著几何结构,例如日历月份呈现圆形排列,历史年份形成平滑的一维流形,城市经纬度可以通过线性探测解码。研究表明,语言统计具有平移对称性,即任意两个月份在文本中共现的频率仅取决于它们之间的时间间隔。论文证明了这种对称性决定了高维词嵌入模型中的几何结构,并解析地推导了词表征的流形几何。这些预测与大型文本嵌入模型和大型语言模型的结果相符。此外,即使在相关统计数据受到扰动时(例如,删除所有两个月份共现的句子),表征几何仍然存在。论文证明,当共现统计由潜在变量控制时,这种鲁棒性自然产生。这些结果表明,表征流形具有普遍的起源:自然数据统计中的对称性。
🔬 方法详解
问题定义:论文旨在解决语言模型内部表征几何结构的起源问题。现有的语言模型在学习过程中,会将词汇映射到高维空间中,形成特定的几何结构,例如月份呈现圆形,年份呈现线性排列。然而,现有方法缺乏对这些几何结构形成原因的解释,以及这些结构是否具有普遍性和鲁棒性。
核心思路:论文的核心思路是,语言统计中的平移对称性是这些几何结构的关键驱动因素。具体来说,如果两个词的共现频率只取决于它们之间的某种关系(例如时间间隔),那么它们在嵌入空间中的位置也会呈现出相应的几何关系。这种对称性可以解释为什么月份会呈现圆形排列,因为月份之间的关系是周期性的。
技术框架:论文首先分析了语言统计中的平移对称性,并证明了这种对称性决定了高维词嵌入模型中的几何结构。然后,论文解析地推导了词表征的流形几何,得到了理论预测。最后,论文通过实验验证了理论预测与大型语言模型和文本嵌入模型的结果是否一致。实验中,论文还研究了表征几何对统计扰动的鲁棒性。
关键创新:论文最重要的技术创新点在于,它将语言统计中的平移对称性与语言模型内部表征的几何结构联系起来,并从理论上解释了这些几何结构的起源。与现有方法相比,该论文提供了一个更加普遍和深入的解释,并且能够预测模型表征的几何形状。
关键设计:论文的关键设计包括:1) 对语言统计中的平移对称性进行数学建模;2) 推导词表征的流形几何;3) 设计实验验证理论预测;4) 研究表征几何对统计扰动的鲁棒性。论文没有涉及具体的网络结构或损失函数的设计,而是侧重于理论分析和实验验证。
🖼️ 关键图片
📊 实验亮点
论文通过实验验证了理论预测与大型语言模型和文本嵌入模型的结果一致。例如,实验表明,模型能够学习到月份的圆形排列和年份的线性排列。此外,实验还表明,即使在相关统计数据受到扰动时,表征几何仍然存在,这说明模型具有一定的鲁棒性。
🎯 应用场景
该研究成果可应用于提升语言模型的理解和生成能力,例如,通过理解模型内部表征的几何结构,可以更好地控制模型的输出,使其更加符合人类的语言习惯。此外,该研究还可以用于分析和比较不同语言模型的表征能力,从而为模型选择和优化提供指导。
📄 摘要(原文)
The internal representations learned by language models consistently exhibit striking geometric structure: calendar months organize into a circle, historical years form a smooth one-dimensional manifold, and cities' latitudes and longitudes can be decoded using a linear probe. To explain this neural code, we first show that language statistics exhibit translation symmetry (for example, the frequency with which any two months co-occur in text depends only on the time interval between them). We prove that this symmetry governs these geometric structures in high-dimensional word embedding models, and we analytically derive the manifold geometry of word representations. These predictions empirically match large text embedding models and large language models. Moreover, the representational geometry persists at moderate embedding dimension even when the relevant statistics are perturbed (e.g., by removing all sentences in which two months co-occur). We prove that this robustness emerges naturally when the co-occurrence statistics are controlled by an underlying latent variable. These results suggest that representational manifolds have a universal origin: symmetry in the statistics of natural data.