Learning beyond Teacher: Generalized On-Policy Distillation with Reward Extrapolation
作者: Wenkai Yang, Weijie Liu, Ruobing Xie, Kai Yang, Saiyong Yang, Yankai Lin
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-02-28
💡 一句话要点
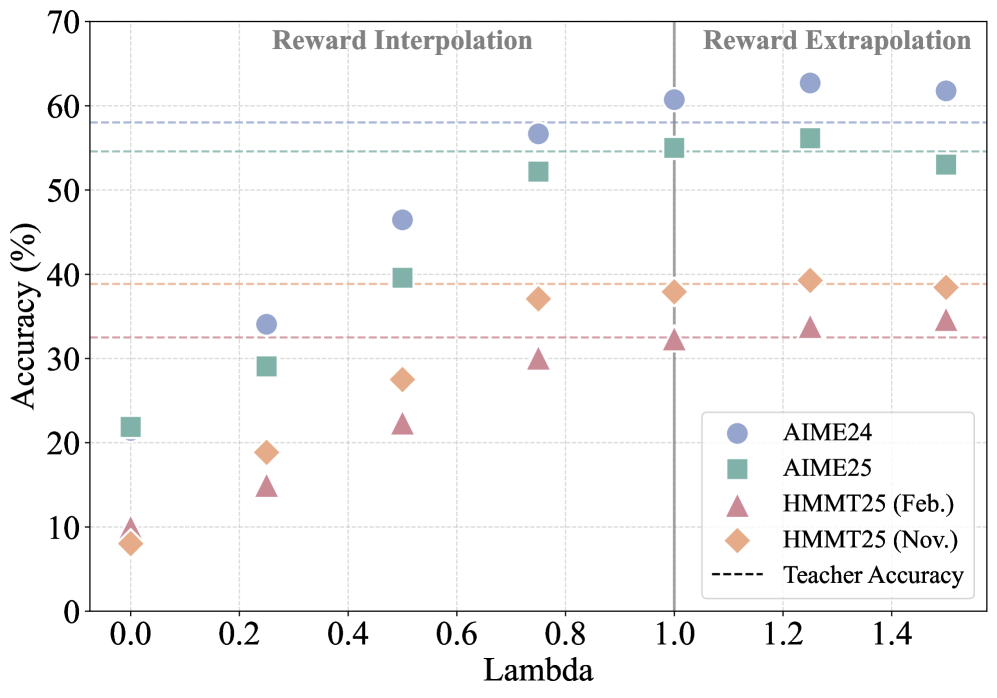
提出广义On-Policy蒸馏框架G-OPD,通过奖励外推提升学生模型性能,甚至超越教师模型。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: On-Policy蒸馏 奖励外推 知识迁移 模型压缩 强化学习 策略优化 奖励缩放
📋 核心要点
- 现有On-Policy蒸馏方法中,奖励函数和KL正则化权重固定,限制了学生模型的性能提升。
- 提出广义On-Policy蒸馏框架G-OPD,通过引入奖励缩放因子和灵活的参考模型,解耦奖励与正则化。
- 实验表明,奖励外推(ExOPD)能显著提升学生模型性能,甚至超越教师模型,尤其是在知识融合场景下。
📝 摘要(中文)
本文提出广义On-Policy蒸馏(G-OPD)框架,该框架扩展了标准OPD目标,引入了灵活的参考模型和奖励缩放因子,用于控制奖励项与KL正则化之间的相对权重。理论上,本文首先证明OPD是密集KL约束强化学习的一个特例,其中奖励函数和KL正则化始终等权重,且参考模型可以是任何模型。通过在数学推理和代码生成任务上的综合实验,本文得出两个新颖的见解:(1)将奖励缩放因子设置为大于1(即奖励外推),称为ExOPD,在各种教师-学生大小配对中,始终优于标准OPD。特别是,在将来自不同领域专家的知识合并回原始学生模型时,ExOPD使学生甚至能够超越教师的性能边界,并优于领域教师。(2)在强到弱的蒸馏设置中,通过选择教师的RL前基础模型作为参考模型进行奖励校正,可以产生更准确的奖励信号,并进一步提高蒸馏性能。然而,这种选择需要访问教师的预RL变体,并产生更多的计算开销。希望本文的工作能为OPD的未来研究提供新的见解。
🔬 方法详解
问题定义:现有的On-Policy Distillation (OPD)方法通常将奖励函数和KL散度正则化项以固定的权重结合,限制了学生模型探索更优策略的能力,尤其是在复杂任务中,固定的权重可能无法充分利用教师模型的知识。
核心思路:本文的核心思路是通过解耦奖励函数和KL散度正则化项的权重,允许学生模型在学习过程中更加灵活地调整对教师策略的模仿程度和自身探索的力度。具体来说,引入一个奖励缩放因子来控制奖励项的权重,并允许使用更灵活的参考模型,从而实现更广义的蒸馏。
技术框架:G-OPD框架的核心在于修改了标准的OPD目标函数。标准的OPD目标是最大化学生模型在学生自身轨迹上的期望奖励,同时最小化学生模型策略与教师模型策略之间的KL散度。G-OPD框架通过引入奖励缩放因子和灵活的参考模型来扩展这个目标函数。具体来说,目标函数变为最大化奖励缩放因子乘以期望奖励,减去学生模型策略与参考模型策略之间的KL散度。参考模型不再局限于教师模型,可以是教师模型的预训练版本或其他模型。
关键创新:本文最重要的技术创新点在于提出了奖励外推(ExOPD)的概念,即设置奖励缩放因子大于1。这使得学生模型在学习过程中更加重视奖励信号,从而能够探索到比教师模型更好的策略。此外,使用教师模型的预训练版本作为参考模型进行奖励校正,可以提供更准确的奖励信号,进一步提升蒸馏性能。
关键设计:G-OPD的关键设计包括:1) 奖励缩放因子:控制奖励项的权重,允许学生模型在模仿教师策略和自身探索之间进行权衡。2) 灵活的参考模型:允许使用教师模型的预训练版本或其他模型作为参考,从而提供更准确的奖励信号。3) 损失函数:修改后的OPD目标函数,包含奖励缩放因子和KL散度项。
🖼️ 关键图片


📊 实验亮点
实验结果表明,ExOPD在数学推理和代码生成任务上显著优于标准OPD。特别是在知识融合场景下,ExOPD使学生模型能够超越教师模型的性能边界。例如,在某些实验中,学生模型的性能提升超过了10%。此外,使用教师模型的预训练版本作为参考模型进行奖励校正,可以进一步提高蒸馏性能。
🎯 应用场景
该研究成果可应用于各种需要知识迁移和模型压缩的场景,例如:机器人控制、自然语言处理、计算机视觉等。通过将大型教师模型的知识迁移到小型学生模型,可以在资源受限的设备上部署高性能的AI应用。此外,该方法还可以用于融合多个领域专家的知识,提升模型的泛化能力。
📄 摘要(原文)
On-policy distillation (OPD), which aligns the student with the teacher's logit distribution on student-generated trajectories, has demonstrated strong empirical gains in improving student performance and often outperforms off-policy distillation and reinforcement learning (RL) paradigms. In this work, we first theoretically show that OPD is a special case of dense KL-constrained RL where the reward function and the KL regularization are always weighted equally and the reference model can by any model. Then, we propose the Generalized On-Policy Distillation (G-OPD) framework, which extends the standard OPD objective by introducing a flexible reference model and a reward scaling factor that controls the relative weight of the reward term against the KL regularization. Through comprehensive experiments on math reasoning and code generation tasks, we derive two novel insights: (1) Setting the reward scaling factor to be greater than 1 (i.e., reward extrapolation), which we term ExOPD, consistently improves over standard OPD across a range of teacher-student size pairings. In particular, in the setting where we merge the knowledge from different domain experts, obtained by applying domain-specific RL to the same student model, back into the original student, ExOPD enables the student to even surpass the teacher's performance boundary and outperform the domain teachers. (2) Building on ExOPD, we further find that in the strong-to-weak distillation setting (i.e., distilling a smaller student from a larger teacher), performing reward correction by choosing the reference model as the teacher's base model before RL yields a more accurate reward signal and further improves distillation performance. However, this choice assumes access to the teacher's pre-RL variant and incurs more computational overhead. We hope our work offers new insights for future research on OPD.