Versor: A Geometric Sequence Architecture
作者: Truong Minh Huy, Edward Hirst
分类: cs.LG, cs.AI
发布日期: 2026-02-28
💡 一句话要点
Versor:一种基于共形几何代数的序列架构,提升泛化能力与效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 共形几何代数 序列建模 几何深度学习 等变神经网络 注意力机制
📋 核心要点
- 现有序列模型在处理具有复杂几何关系的数据时,泛化能力不足,需要显式结构编码。
- Versor利用共形几何代数CGA,将序列状态嵌入到几何空间中,通过几何变换自然地表达SE(3)等变关系。
- 实验表明,Versor在多个任务上超越了Transformer和图网络等基线,同时显著减少了参数量并提高了效率。
📝 摘要(中文)
本文提出了一种新的序列架构Versor,它使用共形几何代数(CGA)代替传统的线性运算,从而在各种任务上实现结构泛化和显著的性能提升,同时提供更好的可解释性和效率。通过将状态嵌入到$Cl_{4,1}$流形中,并通过几何变换(转子)演化它们,Versor原生表示$SE(3)$-等变关系,而无需显式的结构编码。Versor在混沌N体动力学、拓扑推理和标准多模态基准(CIFAR-10、WikiText-103)上进行了验证,始终优于Transformers、图网络和几何基线(GATr、EGNN)。关键结果包括:参数数量级减少(比Transformers少200倍);可解释的注意力分解为邻近性和方向分量;零样本尺度泛化(ViT的MCC为0.993 vs. 0.070);以及用于动态系统中$O(L)$线性时间复杂度的递归转子累加器(RRA),以及用于$O(L^{2})$全局关系建模的几何积注意力(GPA)机制,允许根据所需的规模进行特定于任务的架构修剪或混合。在分布外测试中,Versor保持稳定的预测,而Transformers则出现灾难性的失败。定制的Clifford内核通过位掩码收缩和专门的矩阵同构内核实现了超过100倍的累积加速,将每步延迟降低到1.05毫秒,并优于高度优化的Transformer基线。
🔬 方法详解
问题定义:现有序列模型,特别是Transformer,在处理需要理解几何结构和关系的任务时,存在泛化能力不足的问题。它们通常需要显式地编码结构信息,例如通过位置编码或图神经网络,这增加了模型的复杂性,并且可能限制了模型对新结构数据的适应性。此外,Transformer的计算复杂度较高,尤其是在处理长序列时,限制了其在资源受限环境中的应用。
核心思路:Versor的核心思路是利用共形几何代数(CGA)来表示和演化序列状态。CGA提供了一种自然的方式来表示点、线、面等几何对象,以及它们之间的关系,例如距离、角度和方向。通过将序列状态嵌入到CGA空间中,并使用几何变换(例如旋转和平移)来演化这些状态,Versor能够原生表示SE(3)等变关系,而无需显式的结构编码。这种方法可以提高模型的泛化能力,并减少参数量。
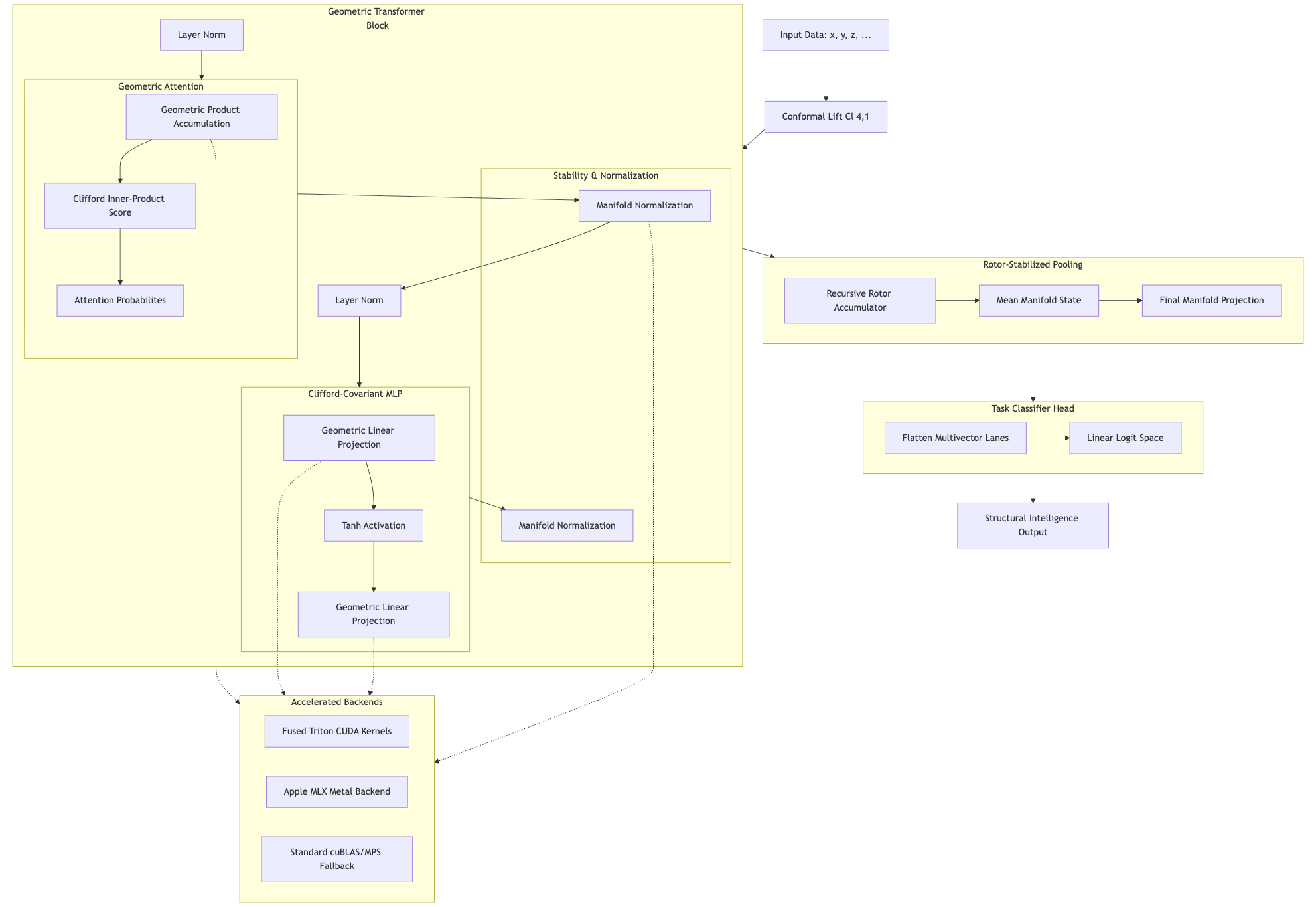
技术框架:Versor的整体架构包括以下几个主要模块:1) 输入嵌入:将输入序列嵌入到CGA空间中,得到初始的几何状态表示。2) 递归转子累加器(RRA):使用一系列转子(CGA中的旋转算子)来演化几何状态,实现线性时间复杂度的序列建模。3) 几何积注意力(GPA):使用几何积来计算注意力权重,从而捕捉序列中不同元素之间的关系。4) 输出解码:将CGA空间中的状态解码为最终的输出。根据具体任务,可以选择使用RRA或GPA,或者将两者结合使用。
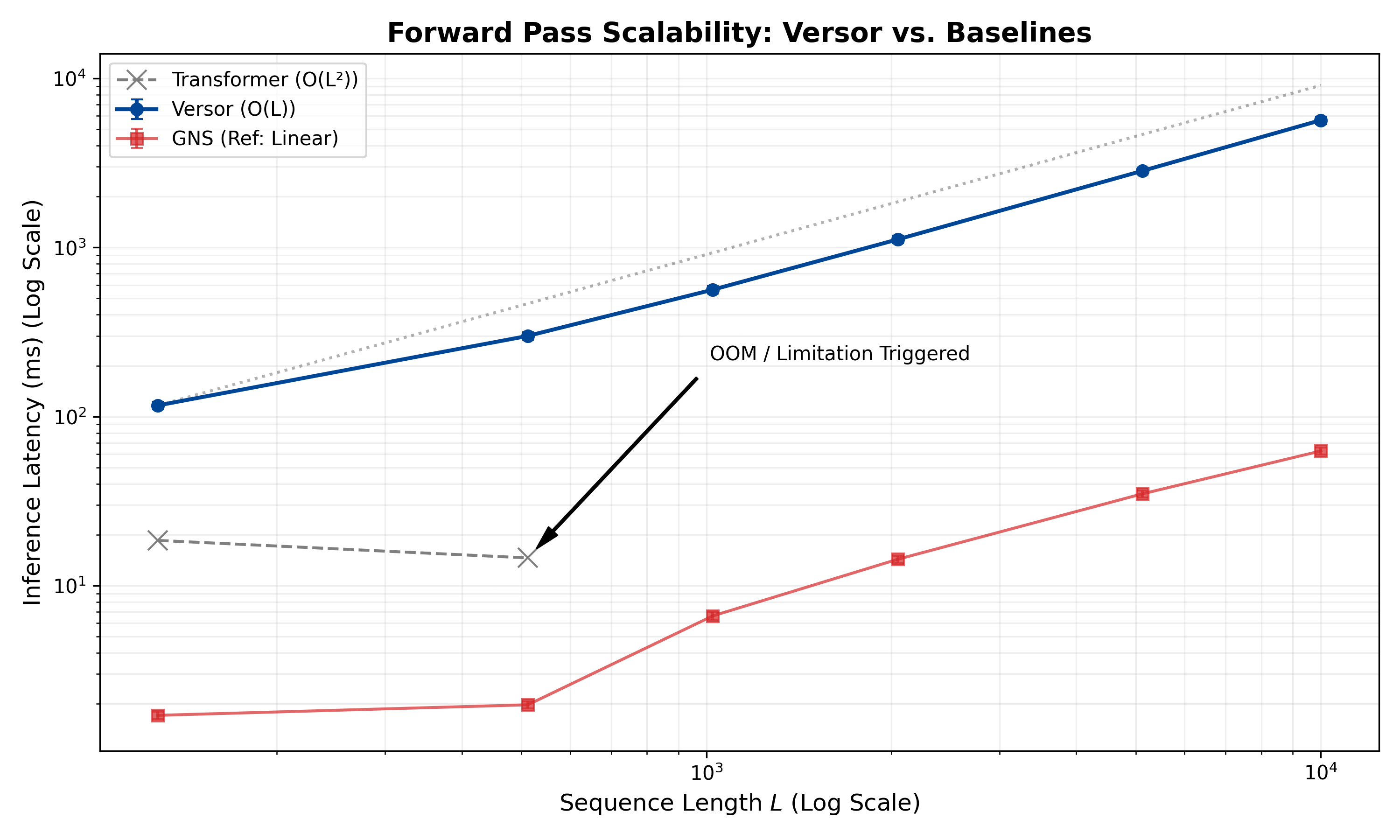
关键创新:Versor最重要的技术创新点在于使用CGA来表示和演化序列状态。与传统的线性运算相比,CGA能够更自然地表达几何关系,从而提高模型的泛化能力和效率。此外,Versor还提出了递归转子累加器(RRA)和几何积注意力(GPA)两种新的序列建模机制,分别实现了线性时间和二次时间复杂度,可以根据任务需求进行选择。
关键设计:Versor的关键设计包括:1) 使用$Cl_{4,1}$作为CGA空间,该空间能够表示三维空间中的点、线、面等几何对象。2) 使用转子作为几何变换的基本单元,转子可以通过指数映射从李代数生成,从而保证变换的等变性。3) 设计了定制的Clifford内核,通过位掩码收缩和专门的矩阵同构内核实现了超过100倍的加速。
🖼️ 关键图片
📊 实验亮点
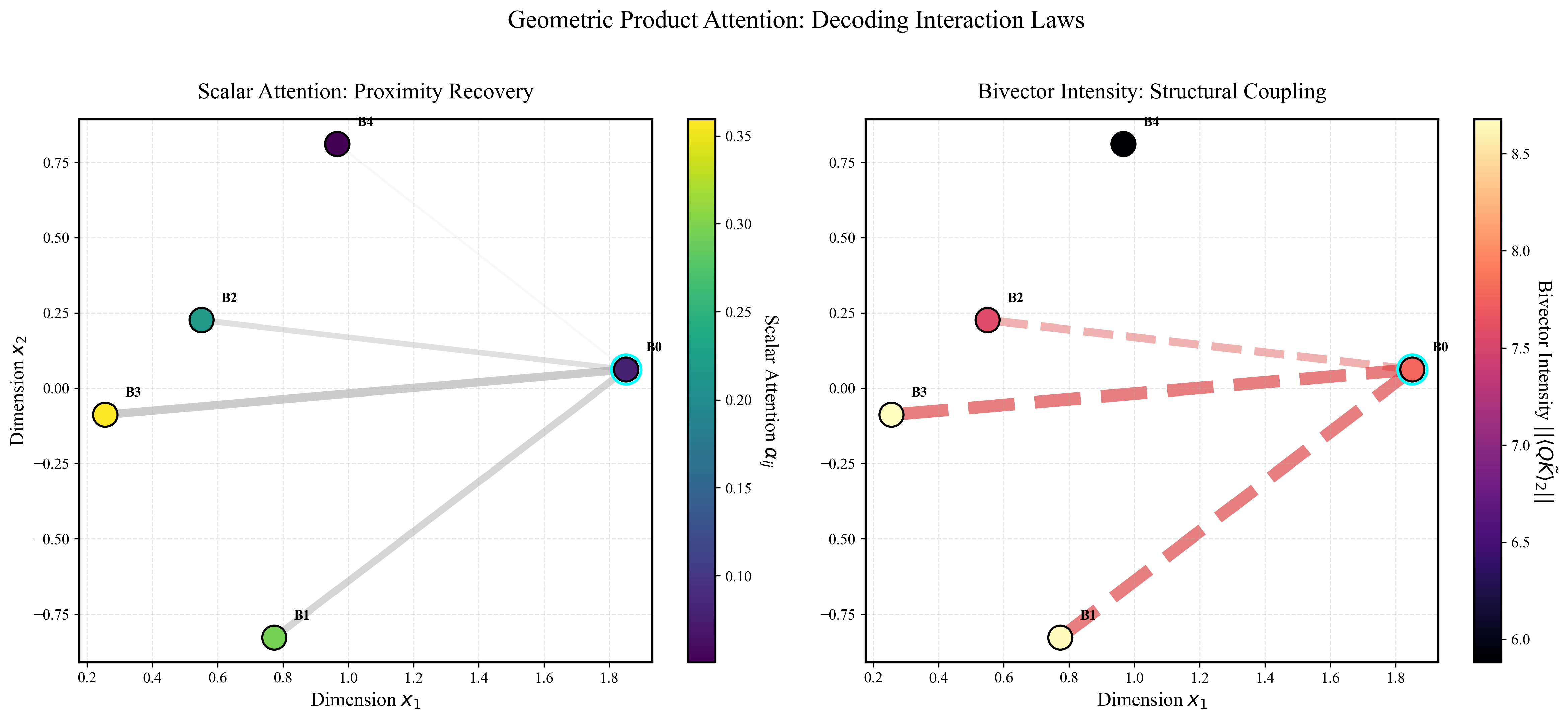
Versor在多个任务上取得了显著的性能提升。在混沌N体动力学任务中,Versor实现了零样本尺度泛化,MCC达到0.993,而ViT仅为0.070。在标准多模态基准测试中,Versor始终优于Transformers、图网络和几何基线。此外,Versor的参数量比Transformers少200倍,并且通过定制的Clifford内核实现了超过100倍的加速,每步延迟仅为1.05毫秒。
🎯 应用场景
Versor具有广泛的应用前景,包括机器人导航、三维场景理解、药物发现和材料设计等领域。其高效的几何推理能力使其能够处理复杂的空间关系,并为这些领域带来更智能、更高效的解决方案。未来,Versor有望成为一种通用的序列建模框架,应用于更多需要理解几何结构的场景。
📄 摘要(原文)
A novel sequence architecture is introduced, Versor, which uses Conformal Geometric Algebra (CGA) in place of traditional linear operations to achieve structural generalization and significant performance improvements on a variety of tasks, while offering improved interpretability and efficiency. By embedding states in the $Cl_{4,1}$ manifold and evolving them via geometric transformations (rotors), Versor natively represents $SE(3)$-equivariant relationships without requiring explicit structural encoding. Versor is validated on chaotic N-body dynamics, topological reasoning, and standard multimodal benchmarks (CIFAR-10, WikiText-103), consistently outperforming Transformers, Graph Networks, and geometric baselines (GATr, EGNN). Key results include: orders-of-magnitude fewer parameters ($200\times$ vs. Transformers); interpretable attention decomposing into proximity and orientational components; zero-shot scale generalization (0.993 vs. 0.070 MCC for ViT); and featuring a Recursive Rotor Accumulator (RRA) for $O(L)$ linear temporal complexity in dynamical systems, and a Geometric Product Attention (GPA) mechanism for $O(L^{2})$ global relational modeling, allowing for task-specific architectural pruning or hybridization depending on the required scale. In out-of-distribution tests, Versor maintains stable predictions while Transformers fail catastrophically. Custom Clifford kernels achieve a cumulative over $100\times$ speedup via bit-masked contraction and specialized Matrix Isomorphism kernels, reducing per-step latency to 1.05 ms and outperforming highly-optimized Transformer baselines.