WebGym: Scaling Training Environments for Visual Web Agents with Realistic Tasks
作者: Hao Bai, Alexey Taymanov, Tong Zhang, Aviral Kumar, Spencer Whitehead
分类: cs.LG, cs.CV
发布日期: 2026-02-28
💡 一句话要点
WebGym:构建大规模真实Web环境,提升视觉Web代理任务性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉Web代理 强化学习 Web环境 异步Rollout Qwen-3-VL-8B-Instruct 分布外泛化 大规模数据集
📋 核心要点
- 现有视觉Web代理训练环境规模小、任务单一,难以适应真实Web环境的非静态性和多样性。
- WebGym通过构建大规模、多样化的真实Web环境,并结合高效的异步rollout系统,加速强化学习训练。
- 实验表明,在WebGym上微调的Qwen-3-VL-8B-Instruct模型在分布外测试集上显著优于GPT-4o和GPT-5-Thinking。
📝 摘要(中文)
本文提出了WebGym,一个迄今为止最大的开源环境,用于训练真实的视觉Web代理。真实的网站具有非静态性和多样性,使得人工或小规模的任务集不足以进行鲁棒的策略学习。WebGym包含近30万个任务,这些任务基于真实世界的网站,具有不同的难度级别,并采用基于规则的评估方法。我们使用简单的强化学习(RL)方法训练代理,该方法利用代理自身的交互轨迹(rollouts),并使用任务奖励作为反馈来指导学习。为了扩展RL,我们开发了一个高吞吐量的异步rollout系统,专门为Web代理设计,从而加快了WebGym中轨迹的采样速度,与朴素的实现相比,我们的系统实现了4-5倍的rollout加速。此外,我们扩展了任务集的广度、深度和大小,从而实现了持续的性能提升。在WebGym上微调一个强大的基础视觉-语言模型Qwen-3-VL-8B-Instruct,使得在分布外测试集上的成功率从26.2%提高到42.9%,显著优于基于专有模型的代理,如GPT-4o和GPT-5-Thinking,它们的成功率分别为27.1%和29.8%。这一改进非常显著,因为我们的测试集仅包含在训练期间从未见过的网站上的任务,这与之前许多关于训练视觉Web代理的工作不同。
🔬 方法详解
问题定义:现有视觉Web代理的训练环境通常是人工构建或规模较小,无法充分模拟真实Web环境的复杂性和多样性。这导致训练出的代理在面对真实世界的网站时,泛化能力较差,难以完成各种任务。现有方法的痛点在于缺乏一个大规模、真实、多样化的训练环境,以及高效的训练方法。
核心思路:本文的核心思路是构建一个大规模的真实Web环境WebGym,并结合高效的异步rollout系统,加速强化学习训练。通过在WebGym上训练,可以使代理更好地适应真实Web环境的复杂性和多样性,从而提高其泛化能力和任务完成能力。
技术框架:WebGym包含近30万个任务,这些任务来自真实世界的网站,具有不同的难度级别,并采用基于规则的评估方法。训练过程采用强化学习方法,利用代理自身的交互轨迹(rollouts),并使用任务奖励作为反馈来指导学习。为了加速训练,开发了一个高吞吐量的异步rollout系统,该系统专门为Web代理设计,可以并行地生成大量的交互轨迹。
关键创新:WebGym本身就是一个重要的创新,它提供了一个大规模、真实、多样化的视觉Web代理训练环境。此外,高吞吐量的异步rollout系统也是一个关键创新,它显著提高了训练效率。与现有方法的本质区别在于,WebGym提供了一个更接近真实世界的训练环境,并且通过高效的训练方法,可以训练出更强大的视觉Web代理。
关键设计:异步rollout系统采用了多进程或多线程的方式,并行地生成交互轨迹。具体实现细节未知,但可以推测其关键设计包括任务调度、数据同步、资源管理等方面。论文中提到,该系统实现了4-5倍的rollout加速,表明其设计是有效的。
🖼️ 关键图片

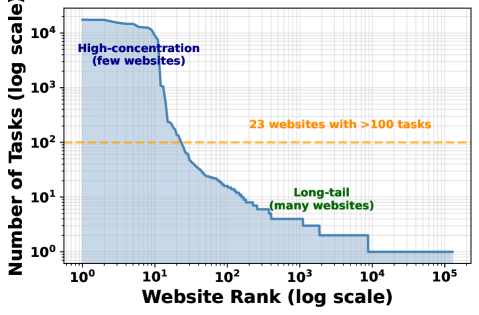
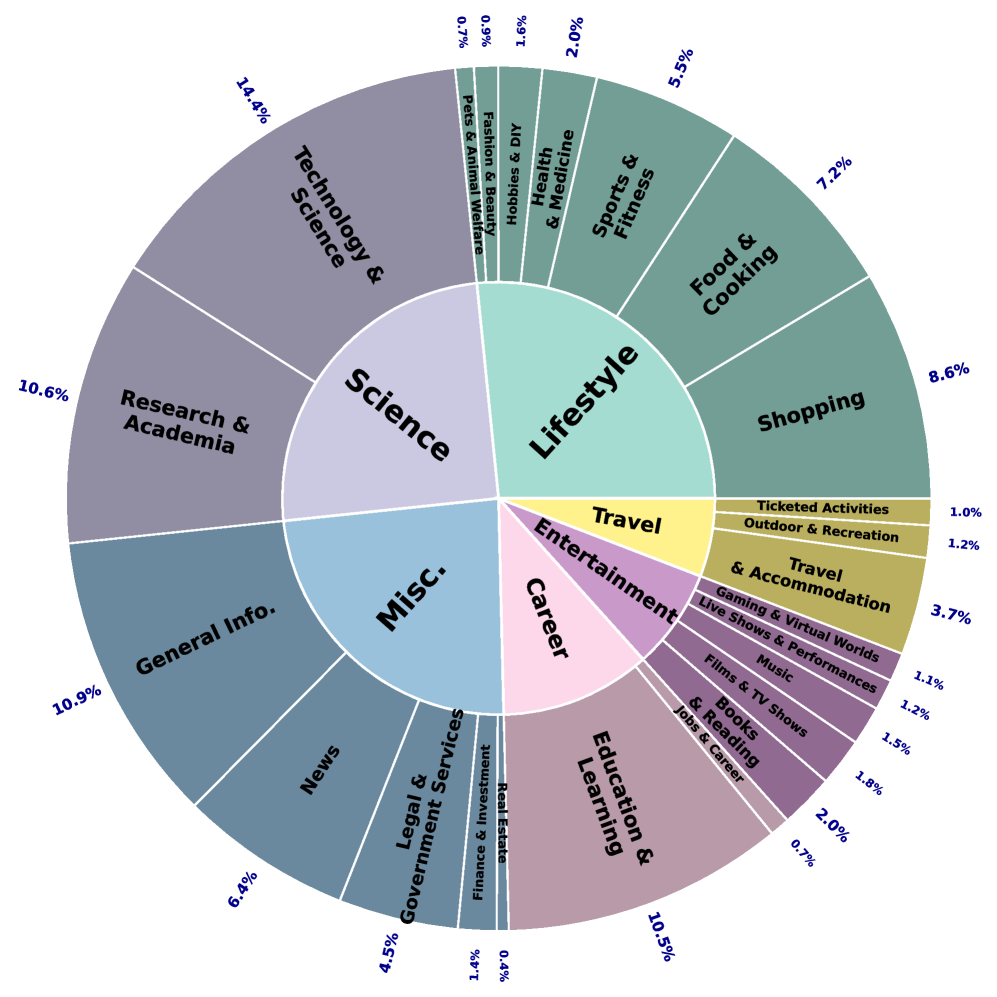
📊 实验亮点
在WebGym上微调Qwen-3-VL-8B-Instruct模型后,在分布外测试集上的成功率从26.2%显著提升至42.9%。该模型性能明显优于基于专有模型的GPT-4o (27.1%) 和 GPT-5-Thinking (29.8%),证明了WebGym在提升视觉Web代理泛化能力方面的有效性。测试集完全由训练期间未见过的网站组成,更具挑战性。
🎯 应用场景
该研究成果可应用于开发更智能、更通用的Web代理,例如智能助手、自动化测试工具、网页信息提取系统等。这些代理可以自动完成各种Web任务,如在线购物、信息搜索、数据录入等,从而提高工作效率和用户体验。未来,该研究有望推动Web自动化和人工智能的进一步发展。
📄 摘要(原文)
We present WebGym, the largest-to-date open-source environment for training realistic visual web agents. Real websites are non-stationary and diverse, making artificial or small-scale task sets insufficient for robust policy learning. WebGym contains nearly 300,000 tasks with rubric-based evaluations across diverse, real-world websites and difficulty levels. We train agents with a simple reinforcement learning (RL) recipe, which trains on the agent's own interaction traces (rollouts), using task rewards as feedback to guide learning. To enable scaling RL, we speed up sampling of trajectories in WebGym by developing a high-throughput asynchronous rollout system, designed specifically for web agents. Our system achieves a 4-5x rollout speedup compared to naive implementations. Second, we scale the task set breadth, depth, and size, which results in continued performance improvement. Fine-tuning a strong base vision-language model, Qwen-3-VL-8B-Instruct, on WebGym results in an improvement in success rate on an out-of-distribution test set from 26.2% to 42.9%, significantly outperforming agents based on proprietary models such as GPT-4o and GPT-5-Thinking that achieve 27.1% and 29.8%, respectively. This improvement is substantial because our test set consists only of tasks on websites never seen during training, unlike many other prior works on training visual web agents.