UniQL: Unified Quantization and Low-rank Compression for Adaptive Edge LLMs
作者: Hung-Yueh Chiang, Chi-Chih Chang, Yu-Chen Lu, Chien-Yu Lin, Kai-Chiang Wu, Mohamed S. Abdelfattah, Diana Marculescu
分类: cs.LG, cs.AI
发布日期: 2026-02-28
💡 一句话要点
提出UniQL框架以解决边缘设备上大语言模型的资源限制问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 量化 低秩压缩 边缘计算 大语言模型 移动设备 模型优化 深度学习
📋 核心要点
- 现有方法在移动设备上部署大型语言模型时,面临内存和计算资源的限制,影响模型的实际应用。
- UniQL框架通过结合后训练量化和低秩压缩,提供了可配置的剪枝率,支持多种边缘应用场景。
- 实验表明,经过量化和剪枝的模型在内存和吞吐量上有显著提升,且准确率保持在可接受范围内。
📝 摘要(中文)
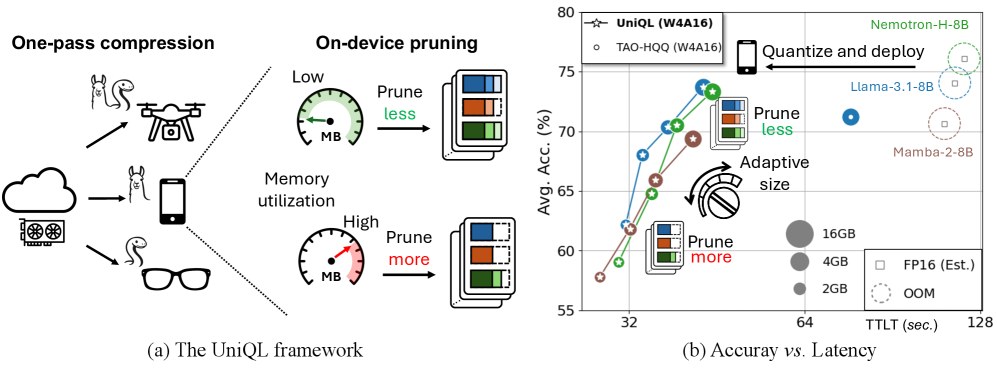
在移动平台上部署大型语言模型(LLMs)面临显著挑战,主要由于设备的内存和计算资源有限。资源的可用性受当前设备工作负载的直接影响,增加了模型部署的不确定性。本文提出了UniQL,一个统一的后训练量化和低秩压缩框架,具有可配置的剪枝率,旨在支持边缘LLMs的多样化应用。UniQL集成了对变换器、状态空间模型(SSMs)和混合模型的量化和低秩压缩,采用高效的结构化权重排序方法、量化感知的奇异值分解(SVD)等技术,显著提高了计算效率和模型性能。实验结果表明,量化和剪枝后的模型在内存上减少了4倍至5.7倍,令token吞吐量提升了2.7倍至3.4倍,同时在15%剪枝下保持了原模型5%的准确率。
🔬 方法详解
问题定义:本文旨在解决在移动设备上部署大型语言模型时,由于内存和计算资源有限而导致的性能瓶颈,现有方法无法有效适应动态的设备工作负载。
核心思路:UniQL框架通过将量化和低秩压缩结合,允许在设备上配置剪枝率,从而在保证模型性能的同时,显著减少内存占用和计算需求。
技术框架:UniQL的整体架构包括权重排序、微调和量化三个主要模块,采用单次工作流在云端完成这些步骤,同时在设备上实现可配置的剪枝率。
关键创新:引入了高效的结构化权重排序方法和量化感知的奇异值分解(SVD),有效减少了量化误差,并通过状态感知的权重排序和融合的旋转位置嵌入(RoPE)内核提升了剪枝模型的性能。
关键设计:框架允许高达35%的剪枝率,实验中在变换器(如Llama3和Qwen2.5)、状态空间模型(如Mamba2)和混合模型(如Nemotron-H和Bamba-v2)上进行验证,确保在15%剪枝下,准确率保持在原模型的5%之内。
🖼️ 关键图片


📊 实验亮点
实验结果显示,经过UniQL处理的量化和剪枝模型在内存上减少了4倍至5.7倍,token吞吐量提升了2.7倍至3.4倍,且在15%剪枝情况下,模型的准确率保持在原模型的5%以内,证明了其在边缘计算中的有效性。
🎯 应用场景
UniQL框架的潜在应用领域包括移动设备上的自然语言处理、智能助手和边缘计算等场景。通过有效降低模型的内存和计算需求,UniQL能够使得大型语言模型在资源受限的环境中更为高效地运行,推动智能应用的普及与发展。
📄 摘要(原文)
Deploying large language models (LLMs) on mobile platforms faces significant challenges due to the limited memory and shared computational resources of the device. Resource availability may be an issue as it is directly impacted by the current device workload, adding to the uncertainty of model deployment. We introduce UniQL, a unified post-training quantization and low-rank compression framework with on-device configurable pruning rates for edge LLMs. UniQL is a general framework that integrates quantization and low-rank compression for Transformers, State Space Models (SSMs), and hybrid models to support diverse edge applications. In our proposed joint framework, we introduce an efficient structured weight-sorting method that speeds up computation by 20x, quantization-aware singular value decomposition (SVD) to minimize quantization errors, state-aware weight sorting for SSMs, and a fused rotary positional embedding (RoPE) kernel for pruned models. Our framework performs weight-sorting, fine-tuning, and quantization in the cloud in a single-pass workflow, while enabling on-device configurable pruning rates up to 35%. Our experiments show that quantized and pruned models achieve a memory reduction of 4x-5.7x and a token-throughput improvement of 2.7x-3.4x, maintaining accuracy within 5% of the original models at 15% pruning across Transformers (Llama3 and Qwen2.5), SSMs (Mamba2), and hybrid models (Nemotron-H and Bamba-v2). The code and quantized models are available at:this https URL.