Improving Discrete Diffusion Unmasking Policies Beyond Explicit Reference Policies
作者: Chunsan Hong, Seonho An, Min-Soo Kim, Jong Chul Ye
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-02-28
💡 一句话要点
提出基于KL正则化MDP的掩码扩散模型优化策略,提升序列生成质量
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 掩码扩散模型 马尔可夫决策过程 KL正则化 策略学习 序列生成
📋 核心要点
- 掩码扩散模型依赖启发式规则确定unmask顺序,缺乏理论保证且性能提升有限。
- 将去噪过程建模为KL正则化MDP,通过优化正则化目标学习更优的unmask策略。
- 实验表明,该方法在多个基准测试中显著优于现有启发式策略,尤其在SUDOKU数据集上提升明显。
📝 摘要(中文)
掩码扩散模型(MDMs)作为一种新型语言建模框架,通过迭代地对掩码序列进行去噪,逐步填充[MASK]标记来生成句子。MDMs支持任意顺序的采样,但性能对下一个要unmask的位置的选择非常敏感。现有方法通常依赖于基于规则的策略(例如,最大置信度、最大边际),这些策略提供了临时性的改进。本文提出用学习到的调度器取代这些启发式方法。具体而言,我们将去噪过程建模为一个带有显式参考策略的KL正则化马尔可夫决策过程(MDP),并优化一个正则化目标,该目标在标准假设下允许策略改进和收敛保证。我们证明,在该框架下优化的策略比启发式调度生成更接近数据分布的样本。在四个基准测试中,我们的学习策略始终优于最大置信度策略:例如,在unmask顺序至关重要的SUDOKU上,它比随机策略提高了20.1%,比最大置信度策略提高了11.2%。
🔬 方法详解
问题定义:掩码扩散模型(MDMs)在生成序列时,如何选择下一个要unmask的位置是一个关键问题。现有的方法,如最大置信度或最大边际,依赖于人工设计的启发式规则,缺乏理论基础,且性能提升受限,难以达到最优的生成效果。这些方法无法保证生成的序列更接近真实数据分布。
核心思路:本文的核心思路是将MDM的去噪过程建模为一个马尔可夫决策过程(MDP),并引入KL散度正则化,鼓励学习到的策略接近一个已知的参考策略。通过优化一个正则化的目标函数,可以保证策略的改进和收敛。这种方法允许模型学习到更优的unmask策略,从而生成更符合数据分布的序列。
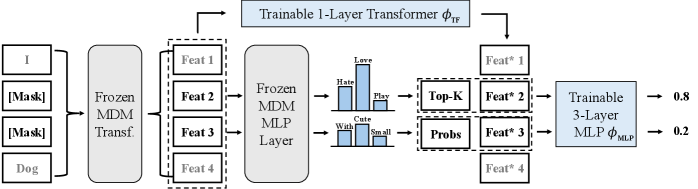
技术框架:整体框架包含以下几个关键部分:1) 将MDM的去噪过程定义为一个MDP,其中状态是当前已unmask的序列,动作是选择下一个要unmask的位置。2) 定义一个奖励函数,用于衡量当前状态的好坏。3) 引入一个参考策略,例如随机策略或最大置信度策略。4) 构建一个KL正则化的目标函数,该函数同时考虑了奖励和与参考策略的KL散度。5) 使用策略梯度等方法优化该目标函数,学习最优的unmask策略。
关键创新:最重要的技术创新点在于将MDM的unmask策略学习问题转化为一个KL正则化的MDP优化问题。与现有方法依赖启发式规则不同,该方法通过学习的方式获得unmask策略,并提供了理论上的收敛保证。KL正则化的引入可以避免策略过于偏离参考策略,从而提高学习的稳定性和效率。
关键设计:关键设计包括:1) 奖励函数的选择,需要能够准确反映当前状态的质量。2) 参考策略的选择,可以根据具体任务选择合适的参考策略。3) KL散度的系数,需要根据实验调整,以平衡奖励和与参考策略的相似度。4) 优化算法的选择,可以使用策略梯度、TRPO或PPO等算法。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在四个基准测试中均优于现有的启发式策略。在SUDOKU数据集上,该方法比随机策略提高了20.1%,比最大置信度策略提高了11.2%。这些结果表明,学习到的unmask策略能够显著提高MDM的生成性能,尤其是在unmask顺序至关重要的任务中。
🎯 应用场景
该研究成果可广泛应用于自然语言生成、图像修复、语音合成等领域。通过学习更优的掩码策略,可以提高生成序列的质量和多样性,例如在文本生成中生成更流畅、更自然的句子,在图像修复中填充更逼真的图像内容。该方法还可应用于数据增强,通过生成新的样本来扩充训练数据集。
📄 摘要(原文)
Masked diffusion models (MDMs) have recently emerged as a novel framework for language modeling. MDMs generate sentences by iteratively denoising masked sequences, filling in [MASK] tokens step by step. Although MDMs support any-order sampling, performance is highly sensitive to the choice of which position to unmask next. Prior work typically relies on rule-based schedules (e.g., max-confidence, max-margin), which provide ad hoc improvements. In contrast, we replace these heuristics with a learned scheduler. Specifically, we cast denoising as a KL-regularized Markov decision process (MDP) with an explicit reference policy and optimize a regularized objective that admits policy improvement and convergence guarantees under standard assumptions. We prove that the optimized policy under this framework generates samples that more closely match the data distribution than heuristic schedules. Empirically, across four benchmarks, our learned policy consistently outperforms max-confidence: for example, on SUDOKU, where unmasking order is critical, it yields a 20.1% gain over random and a 11.2% gain over max-confidence. Code is available atthis https URL.