Predicting LLM Reasoning Performance with Small Proxy Model
作者: Woosung Koh, Juyoung Suk, Sungjun Han, Se-Young Yun, Jamin Shin
分类: cs.LG, cs.AI
发布日期: 2026-02-28
💡 一句话要点
提出rBridge,利用小规模代理模型预测大规模LLM的推理性能,降低数据集优化成本。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 推理能力 代理模型 预训练 数据集优化
📋 核心要点
- 大型语言模型预训练成本高昂,需要小型代理模型进行数据集优化,但推理能力的涌现性使得小模型难以预测大模型的推理性能。
- rBridge通过使小模型更紧密地对齐预训练目标和目标任务,从而实现小模型对大模型推理能力的有效预测。
- 实验表明,rBridge显著降低了数据集排序成本,并在多个推理基准测试中实现了最强的相关性,同时具备跨数据集的零样本迁移能力。
📝 摘要(中文)
由于预训练大型语言模型的成本高昂,利用小型代理模型在扩展模型规模之前优化数据集至关重要。然而,对于推理能力而言,这种方法面临挑战,因为推理能力表现出涌现行为,只有在较大的模型尺寸(通常超过70亿参数)下才能可靠地显现。为了解决这个问题,我们提出了rBridge,它表明小型代理模型(≤10亿参数)可以通过更紧密地与(1)预训练目标和(2)目标任务对齐,从而有效地预测大型模型的推理能力。rBridge通过使用来自前沿模型的推理轨迹作为黄金标签,并使用任务对齐来加权负对数似然来实现这一点。在我们的实验中,rBridge(i)相对于最佳基线,将数据集排序成本降低了100倍以上,(ii)在10亿到320亿规模的六个推理基准测试中实现了最强的相关性,并且(iii)在10亿到70亿规模的预训练数据集之间零样本迁移了预测关系。这些发现表明,rBridge为以较低成本探索面向推理的预训练提供了一条切实可行的途径。
🔬 方法详解
问题定义:论文旨在解决的问题是如何利用小规模的代理模型来预测大规模语言模型(LLM)的推理性能,从而降低预训练数据集优化的成本。现有的方法难以有效预测LLM的推理能力,因为推理能力通常只在大规模模型中才会涌现出来,小模型难以捕捉到这种涌现行为。
核心思路:论文的核心思路是通过使小规模代理模型更紧密地与大规模LLM的预训练目标和目标任务对齐,从而提高小模型预测大模型推理性能的准确性。这种对齐是通过一种特殊的训练方式实现的,该训练方式利用大规模LLM的推理轨迹作为黄金标签,并使用任务对齐来加权负对数似然损失。
技术框架:rBridge 的整体框架包括以下几个主要步骤:1) 使用大规模LLM在推理任务上生成推理轨迹,作为黄金标签。2) 使用这些黄金标签来训练小规模代理模型,目标是让小模型能够模仿大模型的推理过程。3) 在训练过程中,使用任务对齐来加权负对数似然损失,以确保小模型能够更好地学习到与目标任务相关的知识。4) 使用训练好的小模型来预测大规模LLM在不同数据集上的推理性能。
关键创新:rBridge 的关键创新在于它提出了一种新的训练方法,该方法能够使小规模代理模型更紧密地与大规模LLM的预训练目标和目标任务对齐。与现有方法相比,rBridge 不需要直接模拟大规模LLM的内部结构,而是通过模仿其推理过程来学习其推理能力。这种方法更加高效,并且能够更好地捕捉到LLM的涌现行为。
关键设计:rBridge 的关键设计包括:1) 使用大规模LLM的推理轨迹作为黄金标签,这确保了小模型能够学习到与大模型相同的推理策略。2) 使用任务对齐来加权负对数似然损失,这使得小模型能够更好地学习到与目标任务相关的知识。3) 小规模代理模型的选择,论文中使用了参数量小于等于10亿的模型。4) 损失函数的具体形式,即任务对齐加权的负对数似然损失。
🖼️ 关键图片


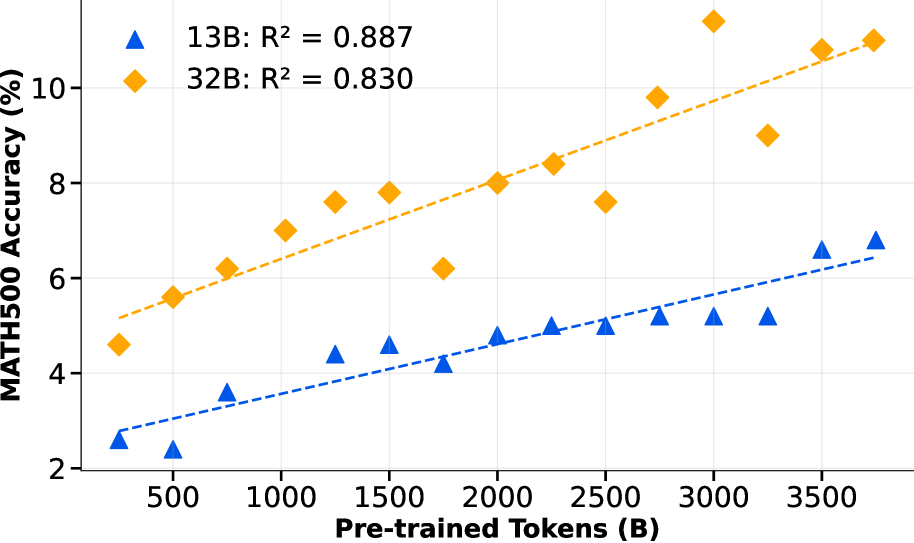
📊 实验亮点
rBridge在数据集排序成本上相比最佳基线降低了超过100倍,并在1B到32B规模的六个推理基准测试中实现了最强的相关性。此外,rBridge还展示了在1B到7B规模的预训练数据集之间零样本迁移预测关系的能力,证明了其良好的泛化性能。
🎯 应用场景
rBridge可应用于大规模语言模型的预训练数据集优化,通过低成本的小模型预测,高效筛选出更适合提升推理能力的数据集。这有助于降低LLM的训练成本,加速AI模型的研发进程,并推动AI技术在问答系统、知识推理等领域的应用。
📄 摘要(原文)
Given the prohibitive cost of pre-training large language models, it is essential to leverage smaller proxy models to optimize datasets before scaling up. However, this approach becomes challenging for reasoning capabilities, which exhibit emergent behavior that only appear reliably at larger model sizes, often exceeding 7B parameters. To address this, we introduce rBridge, showing that small proxies ($\leq$1B) can effectively predict large-model reasoning by aligning more closely with (1) the pre-training objective and (2) the target task. rBridge achieves this by weighting negative log-likelihood with task alignment, using reasoning traces from frontier models as gold labels. In our experiments, rBridge (i) reduces dataset ranking costs by over 100x relative to the best baseline, (ii) achieves the strongest correlation across six reasoning benchmarks at 1B to 32B scale, and (iii) zero-shot transfers predictive relationships across pre-training datasets at 1B to 7B scale. These findings indicate that rBridge offers a practical path for exploring reasoning-oriented pre-training at lower cost.