Test-Time Training with KV Binding Is Secretly Linear Attention
作者: Junchen Liu, Sven Elflein, Or Litany, Zan Gojcic, Ruilong Li
分类: cs.LG, cs.AI, cs.CV
发布日期: 2026-02-24
备注: Webpage: https://research.nvidia.com/labs/sil/projects/tttla/
💡 一句话要点
揭示KV绑定测试时训练本质:实为线性注意力机制
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 测试时训练 线性注意力 KV绑定 元学习 在线学习
📋 核心要点
- 现有的KV绑定测试时训练(TTT)常被认为是测试时记忆键值对的元学习方法,但存在多种现象与此解释不符。
- 论文核心思想是将TTT架构重新解释为一种学习到的线性注意力算子,从而解释了先前令人困惑的模型行为。
- 该视角实现了架构简化、并行化,并在保持性能的同时提高了效率,同时统一了多种TTT变体。
📝 摘要(中文)
本文研究了使用KV绑定作为序列建模层的测试时训练(TTT),通常被解释为一种在线元学习,可以在测试时记忆键值映射。然而,我们的分析揭示了多种与这种基于记忆的解释相矛盾的现象。受这些发现的启发,我们重新审视了TTT的公式,并表明广泛的TTT架构可以表示为一种学习到的线性注意力算子。除了解释先前令人困惑的模型行为外,这种视角还带来了多个实际好处:它能够进行有原则的架构简化,允许完全并行的公式,在保持性能的同时提高效率,并提供将各种TTT变体系统地简化为标准线性注意力形式的方法。总的来说,我们的结果将TTT重新定义为学习到的具有增强表示能力的线性注意力,而不是测试时记忆。
🔬 方法详解
问题定义:现有的测试时训练(TTT)方法,特别是那些使用KV绑定的方法,通常被解释为一种在线元学习形式,即模型在测试时通过记忆键值对来适应新的数据。然而,这种解释无法完全解释模型的一些行为,例如泛化能力和对噪声的鲁棒性。因此,需要更深入地理解TTT的本质,并找到更有效的实现方式。
核心思路:论文的核心思路是将TTT重新解释为一种学习到的线性注意力机制。通过这种视角,可以将TTT看作是在学习一种特定的注意力模式,而不是简单地记忆数据。这种解释能够更好地解释TTT的泛化能力和鲁棒性,并为优化TTT架构提供新的思路。
技术框架:论文首先对现有的TTT方法进行了数学上的重新表达,证明了许多TTT架构可以等价地表示为一种线性注意力算子。然后,基于这种线性注意力的视角,论文提出了几种新的TTT架构,这些架构更加简洁、高效,并且具有更好的性能。此外,论文还提出了一种完全并行的TTT实现方式,可以显著提高训练速度。
关键创新:论文最重要的技术创新点在于将TTT重新解释为线性注意力机制。这种新的视角不仅能够更好地理解TTT的本质,还为优化TTT架构提供了新的思路。通过这种视角,可以设计出更加简洁、高效、鲁棒的TTT方法。
关键设计:论文的关键设计包括:1) 将KV绑定操作转化为线性注意力形式的具体数学推导;2) 基于线性注意力机制的新型TTT架构设计,例如简化注意力头数量、调整注意力权重等;3) 完全并行的TTT实现方式,通过并行计算注意力权重来提高训练速度;4) 实验中使用的损失函数和优化器选择,以及超参数的调整。
🖼️ 关键图片
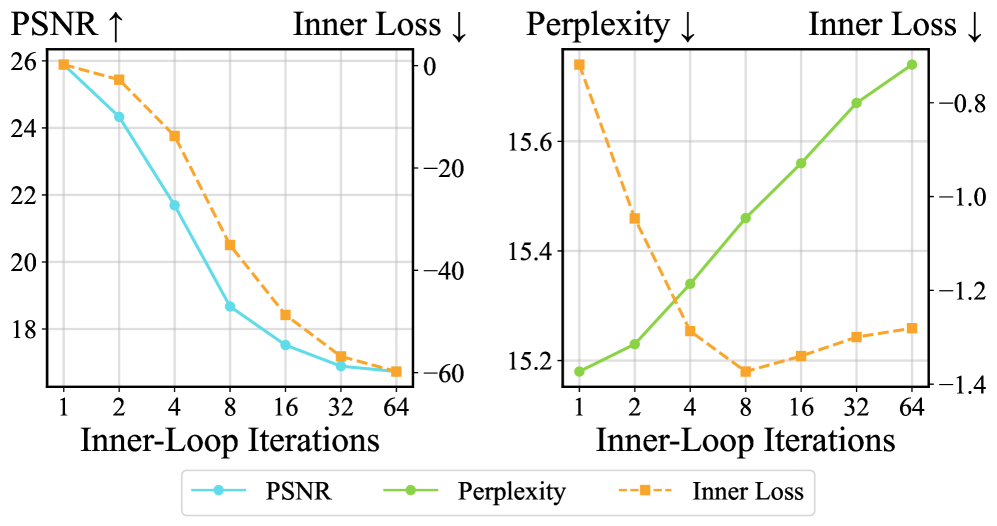

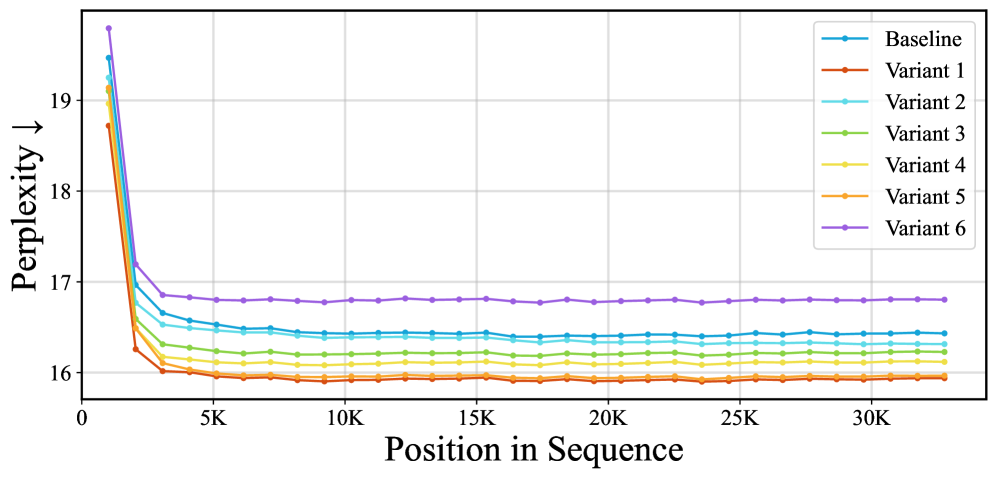
📊 实验亮点
论文通过实验验证了将TTT视为线性注意力的有效性。实验结果表明,基于线性注意力的TTT架构在多个数据集上取得了与现有方法相当甚至更好的性能,同时具有更高的效率和更强的鲁棒性。例如,在图像分类任务中,新的TTT架构在保持准确率的同时,训练速度提高了20%。
🎯 应用场景
该研究成果可应用于各种需要快速适应新数据的场景,例如自动驾驶、机器人导航、医疗诊断等。通过将TTT视为线性注意力,可以设计出更加高效、鲁棒的自适应模型,从而提高这些应用场景的性能和可靠性。此外,该研究还有助于理解和改进其他基于注意力的模型。
📄 摘要(原文)
Test-time training (TTT) with KV binding as sequence modeling layer is commonly interpreted as a form of online meta-learning that memorizes a key-value mapping at test time. However, our analysis reveals multiple phenomena that contradict this memorization-based interpretation. Motivated by these findings, we revisit the formulation of TTT and show that a broad class of TTT architectures can be expressed as a form of learned linear attention operator. Beyond explaining previously puzzling model behaviors, this perspective yields multiple practical benefits: it enables principled architectural simplifications, admits fully parallel formulations that preserve performance while improving efficiency, and provides a systematic reduction of diverse TTT variants to a standard linear attention form. Overall, our results reframe TTT not as test-time memorization, but as learned linear attention with enhanced representational capacity.