Why Pass@k Optimization Can Degrade Pass@1: Prompt Interference in LLM Post-training
作者: Anas Barakat, Souradip Chakraborty, Khushbu Pahwa, Amrit Singh Bedi
分类: cs.LG, cs.AI
发布日期: 2026-02-24
💡 一句话要点
揭示Pass@k优化降低Pass@1的Prompt干扰现象,并提供理论解释。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 Pass@k优化 Pass@1 Prompt干扰 梯度冲突
📋 核心要点
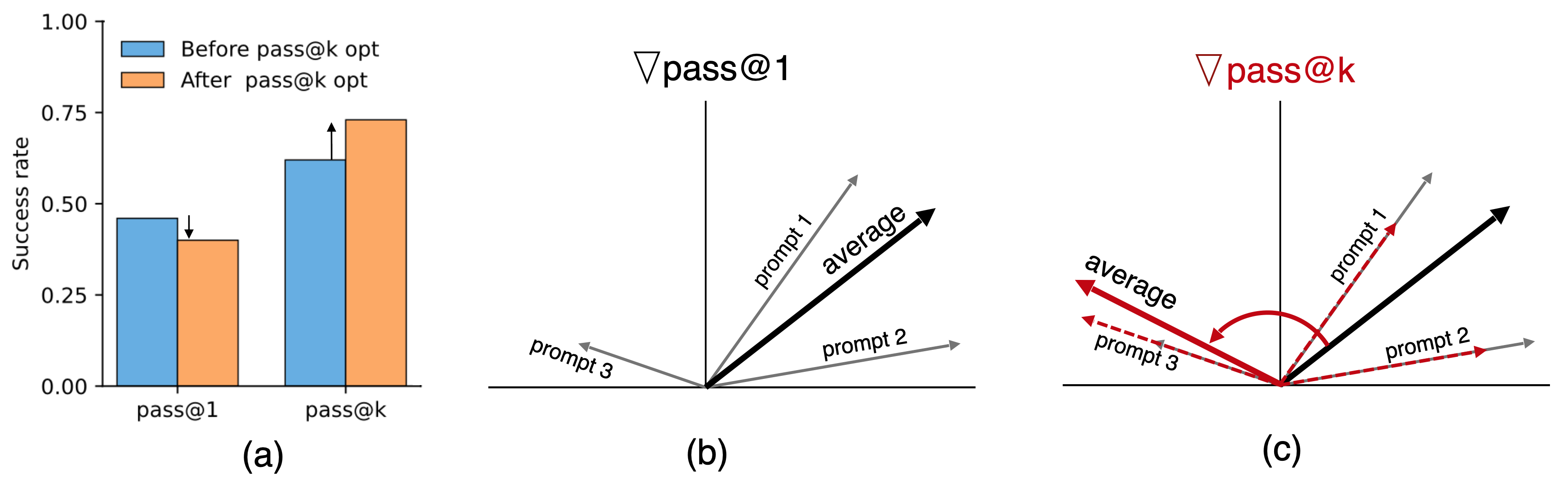
- 现有Pass@k优化方法在提升多样本性能的同时,常常牺牲单样本性能Pass@1,这限制了实际应用。
- 论文指出Pass@k优化会隐式地对低成功率的Prompt进行重加权,导致梯度冲突,从而降低Pass@1。
- 通过数学推理任务的实验,验证了Pass@k优化过程中Prompt干扰现象,支持了理论分析结果。
📝 摘要(中文)
Pass@k是可验证的大型语言模型任务(包括数学推理、代码生成和简答推理)中广泛使用的性能指标。如果k个独立采样的解决方案中任何一个通过验证器,则定义为成功。这种多样本推理指标推动了直接优化pass@k的推理感知微调方法。然而,先前的工作报告了一个反复出现的权衡:在这种方法下,pass@k得到改善,而pass@1却下降。这种权衡在实践中非常重要,因为由于延迟和成本预算、不完善的验证器覆盖以及对可靠的单次回退的需求,pass@1通常仍然是一个硬性的操作约束。我们研究了这种权衡的起源,并提供了pass@k策略优化何时会通过prompt干扰引起的梯度冲突来降低pass@1的理论表征。我们表明,pass@k策略梯度可能与pass@1梯度冲突,因为pass@k优化隐式地将prompt重新加权到低成功率的prompt;当这些prompt是我们所说的负干扰时,它们的加权会使pass@k更新方向偏离pass@1方向。我们用大型语言模型在可验证的数学推理任务上的实验来说明我们的理论发现。
🔬 方法详解
问题定义:论文旨在解决Pass@k优化方法在提升多样本性能的同时,单样本性能Pass@1下降的问题。现有方法虽然能提高Pass@k,但由于Pass@1在实际应用中具有重要意义(如低延迟、低成本),因此这种trade-off限制了Pass@k优化方法的应用。
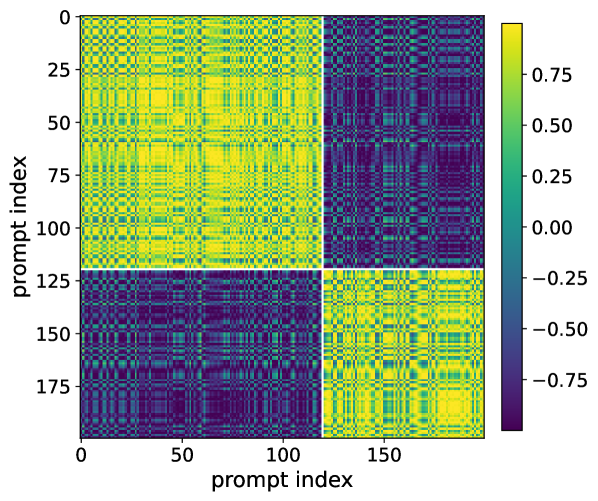
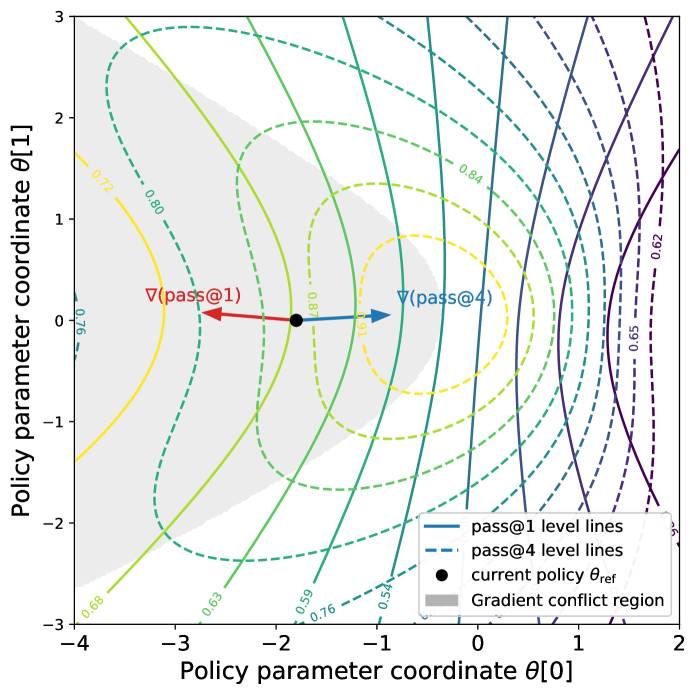
核心思路:论文的核心思路是揭示Pass@k优化过程中,由于Prompt之间的干扰,导致Pass@k的梯度更新方向与Pass@1的梯度更新方向冲突,从而降低了Pass@1。具体来说,Pass@k优化会隐式地对低成功率的Prompt进行重加权,如果这些Prompt是“负干扰”的,那么这种重加权就会导致梯度冲突。
技术框架:论文主要通过理论分析和实验验证来研究Prompt干扰现象。理论分析部分,论文推导了Pass@k优化过程中梯度冲突的条件。实验验证部分,论文在大型语言模型上,针对数学推理任务,进行了Pass@k优化实验,并观察Pass@1的变化,验证了理论分析的正确性。
关键创新:论文最重要的创新点在于揭示了Pass@k优化过程中Prompt干扰现象,并从理论上解释了为什么Pass@k优化会导致Pass@1下降。这为后续研究如何避免Prompt干扰,从而同时提升Pass@k和Pass@1提供了理论基础。
关键设计:论文的关键设计在于如何定义和识别“负干扰”Prompt。论文通过分析Pass@k和Pass@1的梯度方向,定义了负干扰Prompt,并提出了相应的识别方法。此外,论文在实验中,选择了数学推理任务,并设计了相应的验证器,以评估模型的性能。
🖼️ 关键图片
📊 实验亮点
论文通过在大型语言模型上进行数学推理任务的实验,验证了Pass@k优化过程中Prompt干扰现象的存在,并观察到Pass@k提升的同时,Pass@1出现下降。实验结果支持了论文的理论分析,表明Prompt干扰是导致Pass@k优化降低Pass@1的重要原因。
🎯 应用场景
该研究成果可应用于各种需要可验证的大型语言模型任务,如数学推理、代码生成和简答推理。通过避免Prompt干扰,可以同时提升Pass@k和Pass@1,从而提高模型在实际应用中的性能和可靠性。该研究对于开发更有效的推理感知微调方法具有指导意义。
📄 摘要(原文)
Pass@k is a widely used performance metric for verifiable large language model tasks, including mathematical reasoning, code generation, and short-answer reasoning. It defines success if any of $k$ independently sampled solutions passes a verifier. This multi-sample inference metric has motivated inference-aware fine-tuning methods that directly optimize pass@$k$. However, prior work reports a recurring trade-off: pass@k improves while pass@1 degrades under such methods. This trade-off is practically important because pass@1 often remains a hard operational constraint due to latency and cost budgets, imperfect verifier coverage, and the need for a reliable single-shot fallback. We study the origin of this trade-off and provide a theoretical characterization of when pass@k policy optimization can reduce pass@1 through gradient conflict induced by prompt interference. We show that pass@$k$ policy gradients can conflict with pass@1 gradients because pass@$k$ optimization implicitly reweights prompts toward low-success prompts; when these prompts are what we term negatively interfering, their upweighting can rotate the pass@k update direction away from the pass@1 direction. We illustrate our theoretical findings with large language model experiments on verifiable mathematical reasoning tasks.