Scaling State-Space Models on Multiple GPUs with Tensor Parallelism
作者: Anurag Dutt, Nimit Shah, Hazem Masarani, Anshul Gandhi
分类: cs.DC, cs.LG
发布日期: 2026-02-24
备注: Submitted to 46th IEEE International Conference on Distributed Computing Systems (ICDCS 2026)
💡 一句话要点
提出一种通信高效的张量并行方案,加速选择性状态空间模型在多GPU上的推理。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 状态空间模型 张量并行 多GPU推理 长上下文 量化 通信优化 Mamba 深度学习
📋 核心要点
- 现有SSM模型推理受限于单GPU的内存和带宽,无法有效处理长上下文,多GPU并行成为必然。
- 论文提出一种通信高效的张量并行(TP)设计,优化SSM在多GPU上的推理效率,兼顾局部性和减少通信。
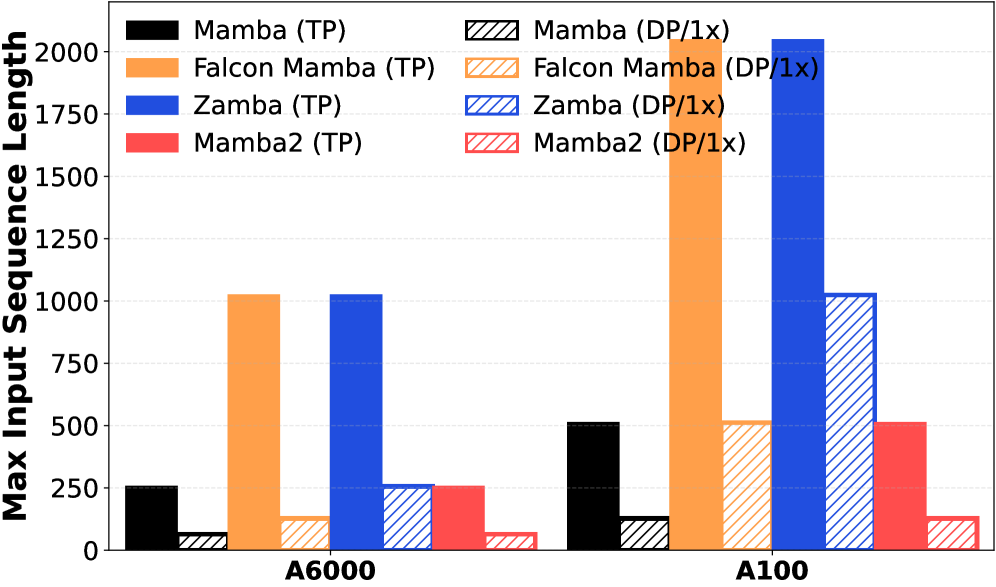
- 实验表明,该方法在Mamba等模型上实现了显著的吞吐量提升,尤其是在长上下文场景下,量化AllReduce进一步提升性能。
📝 摘要(中文)
选择性状态空间模型(SSM)已迅速成为大型语言模型,特别是长上下文工作负载的强大骨干。然而,在部署中,它们的推理性能通常受到单个GPU的内存容量、带宽和延迟限制,使得多GPU执行变得越来越必要。虽然张量并行(TP)被广泛用于扩展Transformer推理,但将其应用于选择性SSM块并非易事,因为SSM混合器将大型投影与序列式递归状态更新和局部混合相结合,而后者的效率取决于保持局部性并避免关键路径中的同步。本文提出了一种通信高效的TP设计,用于选择性SSM推理,解决了三个实际工程挑战:通过跨预填充和解码的SSM状态缓存实现TTFT改进,对混合器的打包参数张量进行分区,以便递归更新保持局部性,同时最小化通信,以及通过量化的AllReduce减少TP聚合开销。我们在NVIDIA A6000和A100集群上,对三种具有代表性的基于SSM的LLM(包括纯SSM和混合架构)- Mamba、Falcon-Mamba和Zamba进行了评估。实验表明,张量并行SSM推理带来了显著的吞吐量提升,在2个GPU上将批量请求吞吐量提高了约1.6-2.1倍,在4个GPU上提高了约2.6-4.0倍(对于Mamba),在长上下文长度下收益最大,并通过降低同步带宽开销,从量化的all-reduce中进一步实现了约10-18%的吞吐量提升。
🔬 方法详解
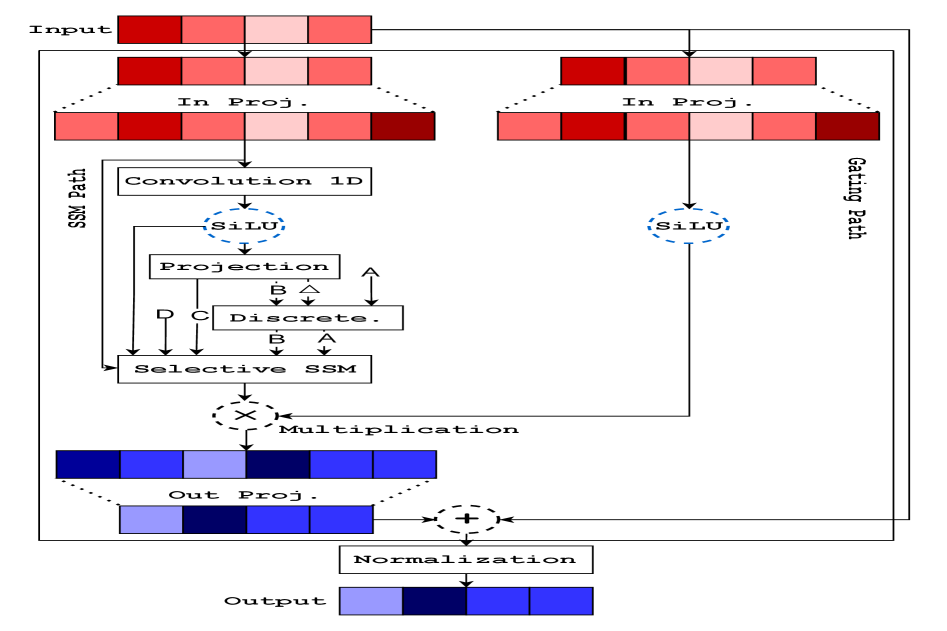
问题定义:论文旨在解决选择性状态空间模型(SSM)在多GPU上进行高效推理的问题。现有方法在将张量并行应用于SSM时面临挑战,因为SSM的混合器(mixer)模块包含大型投影、序列式递归状态更新和局部混合,这些操作对内存、带宽和延迟都有较高要求。直接应用传统张量并行会导致大量的跨GPU通信,降低效率。
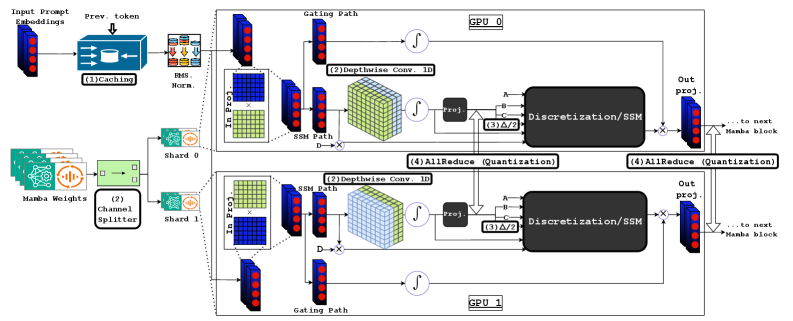
核心思路:论文的核心思路是设计一种通信高效的张量并行方案,该方案能够最大限度地减少GPU之间的通信,同时保持SSM计算的局部性。通过优化参数张量的划分方式,使得递归更新尽可能在单个GPU上完成,从而减少跨GPU的数据传输。此外,利用量化的AllReduce操作来降低TP聚合的开销。
技术框架:该方法主要包含以下几个关键模块:1) SSM状态缓存:用于在预填充(prefill)和解码(decode)阶段之间共享SSM状态,从而提高TTFT(Time To First Token)。2) 参数张量分区:将SSM混合器的参数张量进行划分,使得递归更新尽可能在单个GPU上完成,减少通信。3) 量化的AllReduce:使用量化的AllReduce操作来聚合梯度或激活,从而降低通信带宽开销。
关键创新:论文的关键创新在于针对SSM的特性,设计了一种通信高效的张量并行方案。该方案通过优化参数张量的划分方式和利用量化的AllReduce操作,显著降低了GPU之间的通信量,从而提高了推理效率。与传统的张量并行方法相比,该方案更适合于SSM的结构,能够更好地利用多GPU的计算资源。
关键设计:论文的关键设计包括:1) SSM状态缓存的实现细节,如何有效地存储和共享状态。2) 参数张量分区的具体策略,如何根据SSM的结构选择最佳的划分方式。3) 量化的AllReduce的具体实现,包括量化方法、量化位数等参数的选择。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在Mamba、Falcon-Mamba和Zamba等模型上实现了显著的吞吐量提升。在2个GPU上,Mamba的批量请求吞吐量提高了约1.6-2.1倍,在4个GPU上提高了约2.6-4.0倍。此外,通过量化的AllReduce,进一步实现了约10-18%的吞吐量提升。尤其是在长上下文长度下,性能提升更为明显。
🎯 应用场景
该研究成果可广泛应用于需要处理长上下文的语言模型推理场景,例如机器翻译、文本摘要、对话生成等。通过提高SSM模型在多GPU上的推理效率,可以支持更大规模的模型和更长的上下文长度,从而提升下游任务的性能和用户体验。该方法还可应用于其他具有类似结构的序列模型。
📄 摘要(原文)
Selective state space models (SSMs) have rapidly become a compelling backbone for large language models, especially for long-context workloads. Yet in deployment, their inference performance is often bounded by the memory capacity, bandwidth, and latency limits of a single GPU, making multi-GPU execution increasingly necessary. Although tensor parallelism (TP) is widely used to scale Transformer inference, applying it to selective SSM blocks is non-trivial because the SSM mixer couples large projections with a sequence-wise recurrent state update and local mixing whose efficiency depends on preserving locality and avoiding synchronization in the critical path. This paper presents a communication-efficient TP design for selective SSM inference that addresses three practical engineering challenges: enabling TTFT improvements via an SSM state cache across prefill and decode, partitioning the mixer's packed parameter tensor so that recurrent updates remain local while minimizing communication, and reducing TP aggregation overhead with quantized AllReduce. We evaluate on three representative SSM-based LLMs spanning pure-SSM and hybrid architectures - Mamba, Falcon-Mamba, and Zamba - on NVIDIA A6000 and A100 clusters. Our experiments show substantial throughput gains from tensor-parallel SSM inference, improving batch-request throughput by ~1.6-2.1x on 2 GPUs and ~2.6-4.0x on 4 GPUs for Mamba, with the largest benefits at long context lengths, and achieving a further ~10-18% throughput improvement from quantized all-reduce by lowering synchronization bandwidth overhead.