SOM-VQ: Topology-Aware Tokenization for Interactive Generative Models
作者: Alessandro Londei, Denise Lanzieri, Matteo Benati
分类: cs.LG, stat.ML
发布日期: 2026-02-24
💡 一句话要点
提出SOM-VQ以解决向量量化表示的语义结构缺失问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 向量量化 自组织映射 生成模型 人机交互 运动生成 拓扑感知 可解释性 交互生成
📋 核心要点
- 现有的向量量化生成模型在标记空间中缺乏语义结构,限制了人类的可解释控制能力。
- SOM-VQ结合了向量量化和自组织映射,通过拓扑感知的更新方式学习离散代码本,保持邻域结构。
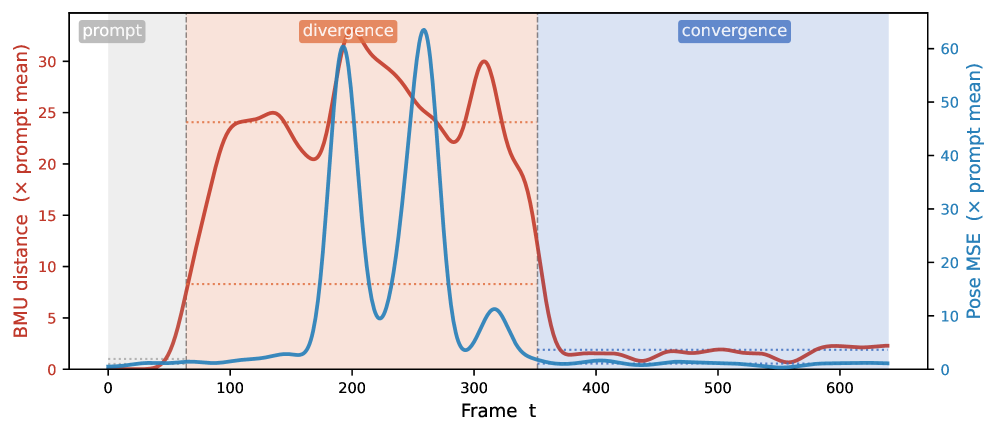
- 实验结果表明,SOM-VQ生成的标记序列更易于学习,并提供了可导航的几何结构,提升了人机交互的直观性。
📝 摘要(中文)
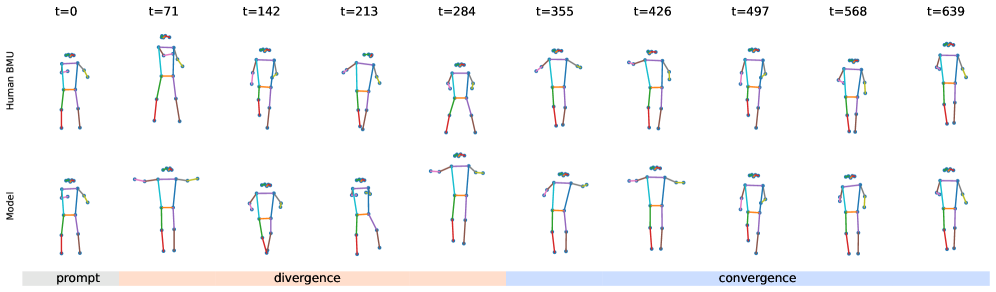
向量量化表示使得离散生成模型具备强大的能力,但在标记空间中缺乏语义结构,限制了可解释的人类控制。我们提出了SOM-VQ,这是一种结合向量量化和自组织映射的标记化方法,能够学习具有明确低维拓扑的离散代码本。与标准的VQ-VAE不同,SOM-VQ使用拓扑感知的更新方式,保持邻域结构:在学习的网格上相邻的标记对应于语义相似的状态,从而实现潜在空间的直接几何操控。我们展示了SOM-VQ在评估领域中生成了更易学习的标记序列,同时在代码空间中提供了明确的可导航几何结构。关键是,拓扑组织使得人机交互控制直观化:用户可以通过操控标记空间中的距离来引导生成,实现语义对齐而不受帧级约束。我们专注于人类运动生成,这一领域的运动学结构、平滑的时间连续性和交互使用场景(编舞、康复、人机交互)使得拓扑感知控制尤为自然,展示了通过简单的基于网格的采样实现对参考序列的受控发散和收敛。SOM-VQ为可解释的离散表示提供了一个通用框架,适用于音乐、手势和其他交互生成领域。
🔬 方法详解
问题定义:本论文旨在解决现有向量量化生成模型在标记空间中缺乏语义结构的问题,这导致人类控制能力受限,难以实现直观的生成操控。
核心思路:SOM-VQ的核心思想是将向量量化与自组织映射相结合,通过拓扑感知的更新方式来学习具有明确低维拓扑的离散代码本,从而实现语义相似状态的邻近标记。
技术框架:SOM-VQ的整体架构包括数据输入、向量量化、拓扑感知更新和生成输出几个主要模块。首先,通过自组织映射学习标记的拓扑结构,然后在此基础上进行向量量化和生成。
关键创新:SOM-VQ的主要创新在于其拓扑感知的更新机制,这与传统的VQ-VAE方法不同,能够保持标记之间的邻域关系,支持更直观的几何操控。
关键设计:在参数设置上,SOM-VQ使用了自组织映射的学习率和拓扑结构的定义,损失函数设计上强调了邻域保持,网络结构则结合了卷积和自组织映射的特点,确保了生成的标记序列在语义上具有一致性。
🖼️ 关键图片
📊 实验亮点
实验结果显示,SOM-VQ生成的标记序列在多个评估领域中表现出更高的可学习性,并提供了明确的可导航几何结构。与基线方法相比,SOM-VQ在语义对齐和用户控制方面显著提升,用户可以通过简单的距离操控实现对生成内容的有效引导。
🎯 应用场景
SOM-VQ的研究具有广泛的应用潜力,尤其在人类运动生成、音乐创作、手势识别等交互生成领域。其拓扑感知控制的特性使得用户能够更自然地参与生成过程,提升了交互体验和生成质量,未来可能在康复训练和人机交互等实际应用中发挥重要作用。
📄 摘要(原文)
Vector-quantized representations enable powerful discrete generative models but lack semantic structure in token space, limiting interpretable human control. We introduce SOM-VQ, a tokenization method that combines vector quantization with Self-Organizing Maps to learn discrete codebooks with explicit low-dimensional topology. Unlike standard VQ-VAE, SOM-VQ uses topology-aware updates that preserve neighborhood structure: nearby tokens on a learned grid correspond to semantically similar states, enabling direct geometric manipulation of the latent space. We demonstrate that SOM-VQ produces more learnable token sequences in the evaluated domains while providing an explicit navigable geometry in code space. Critically, the topological organization enables intuitive human-in-the-loop control: users can steer generation by manipulating distances in token space, achieving semantic alignment without frame-level constraints. We focus on human motion generation - a domain where kinematic structure, smooth temporal continuity, and interactive use cases (choreography, rehabilitation, HCI) make topology-aware control especially natural - demonstrating controlled divergence and convergence from reference sequences through simple grid-based sampling. SOM-VQ provides a general framework for interpretable discrete representations applicable to music, gesture, and other interactive generative domains.