Extending $μ$P: Spectral Conditions for Feature Learning Across Optimizers
作者: Akshita Gupta, Marieme Ngom, Sam Foreman, Venkatram Vishwanath
分类: cs.LG
发布日期: 2026-02-24
备注: 10 main pages, 16 appendix pages and 17 figures; Amended version of the publication in 17th International OPT Workshop on Optimization for Machine Learning
💡 一句话要点
提出基于谱条件的μP扩展框架,实现跨优化器特征学习与零样本迁移
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 最大更新参数化 μP 谱条件 优化器 零样本学习 超参数迁移 深度学习 模型缩放
📋 核心要点
- 大型模型训练中,优化器的超参数调整计算成本高昂,成为性能瓶颈。
- 论文提出基于谱条件的μP框架,旨在实现超参数在不同模型大小间的迁移。
- 实验证明,该方法成功实现了多种优化器在模型宽度上的零样本学习率迁移。
📝 摘要(中文)
为了加速和扩展大型语言模型的训练,人们提出了多种自适应一阶和二阶优化方法。这些优化算法的性能对超参数(HPs)的选择非常敏感,而对于大型模型来说,超参数的调整在计算上非常昂贵。最大更新参数化(μP)是一组缩放规则,旨在使最优超参数独立于模型大小,从而允许在较小(计算成本较低)的模型上调整的超参数转移到训练较大的目标模型。尽管在SGD和Adam上取得了可喜的结果,但为其他优化器推导μP具有挑战性,因为底层张量编程方法难以掌握。在最近引入谱条件作为张量程序替代方案的工作基础上,我们提出了一个新的框架,用于为更广泛的优化器类别(包括AdamW、ADOPT、LAMB、Sophia、Shampoo和Muon)推导μP。我们在多个基准模型上实现了我们的μP推导,并证明了上述优化器在增加模型宽度上的零样本学习率迁移。此外,我们还提供了关于这些优化器的深度缩放参数化的经验见解。
🔬 方法详解
问题定义:论文旨在解决大型语言模型训练中,各种优化器(如AdamW、LAMB等)的超参数调整困难问题。现有方法,如基于张量程序的μP推导,难以应用于多种优化器,且理解和实现复杂。因此,如何为更广泛的优化器类别推导出有效的μP规则,并实现超参数的零样本迁移,是本研究要解决的核心问题。
核心思路:论文的核心思路是利用谱条件作为张量程序的替代方案,推导出适用于多种优化器的μP规则。谱条件关注的是权重矩阵的奇异值分解,通过分析奇异值的缩放行为,可以推导出模型参数和超参数的缩放规则,从而实现μP。这种方法避免了复杂的张量编程,更易于理解和应用。
技术框架:该框架主要包含以下几个阶段:1) 分析目标优化器的更新规则;2) 基于谱条件,推导权重矩阵奇异值的缩放行为;3) 根据奇异值的缩放行为,确定模型参数和超参数的缩放规则,即μP规则;4) 在不同模型大小上验证μP规则的有效性,例如通过零样本学习率迁移实验。
关键创新:论文的关键创新在于将谱条件引入到μP推导中,从而提供了一种更通用、更易于理解和实现的μP推导框架。与传统的基于张量程序的μP推导方法相比,该方法能够更容易地应用于多种优化器,并且避免了复杂的张量编程。
关键设计:论文的关键设计包括:1) 选择合适的谱条件,例如关注权重矩阵奇异值的最大值和最小值;2) 根据优化器的具体更新规则,调整谱条件的分析方法;3) 设计零样本学习率迁移实验,以验证μP规则的有效性。具体的参数设置和网络结构取决于实验所使用的基准模型。
🖼️ 关键图片

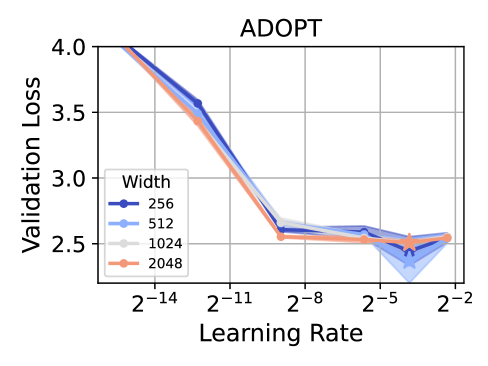
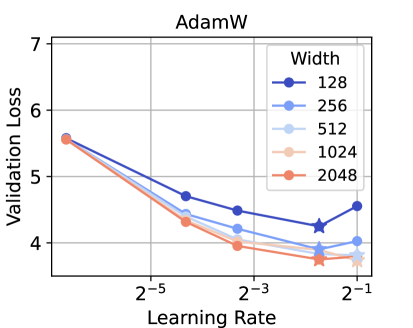
📊 实验亮点
实验结果表明,该方法成功实现了AdamW、ADOPT、LAMB、Sophia、Shampoo和Muon等多种优化器在不同模型宽度上的零样本学习率迁移。这意味着在小模型上调整好的超参数可以直接应用于大模型,而无需重新调整,从而节省了大量的计算资源。具体的性能提升数据和对比基线需要在论文中查找。
🎯 应用场景
该研究成果可广泛应用于大型语言模型的训练和优化。通过实现超参数的零样本迁移,可以显著降低超参数调整的计算成本,加速模型开发周期。此外,该方法还可以应用于其他深度学习模型和优化器,具有广泛的应用前景和实际价值。未来,可以进一步研究深度缩放参数化,以提升模型的性能和效率。
📄 摘要(原文)
Several variations of adaptive first-order and second-order optimization methods have been proposed to accelerate and scale the training of large language models. The performance of these optimization routines is highly sensitive to the choice of hyperparameters (HPs), which are computationally expensive to tune for large-scale models. Maximal update parameterization $(μ$P$)$ is a set of scaling rules which aims to make the optimal HPs independent of the model size, thereby allowing the HPs tuned on a smaller (computationally cheaper) model to be transferred to train a larger, target model. Despite promising results for SGD and Adam, deriving $μ$P for other optimizers is challenging because the underlying tensor programming approach is difficult to grasp. Building on recent work that introduced spectral conditions as an alternative to tensor programs, we propose a novel framework to derive $μ$P for a broader class of optimizers, including AdamW, ADOPT, LAMB, Sophia, Shampoo and Muon. We implement our $μ$P derivations on multiple benchmark models and demonstrate zero-shot learning rate transfer across increasing model width for the above optimizers. Further, we provide empirical insights into depth-scaling parameterization for these optimizers.