Rethink Efficiency Side of Neural Combinatorial Solver: An Offline and Self-Play Paradigm
作者: Zhenxing Xu, Zeyuan Ma, Weidong Bao, Hui Yan, Yan Zheng, Ji Wang
分类: cs.LG
发布日期: 2026-02-24
💡 一句话要点
提出ECO:一种高效的神经组合优化离线自博弈学习范式
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 神经组合优化 离线学习 自博弈 直接偏好优化 Mamba架构 旅行商问题 车辆路径问题
📋 核心要点
- 神经组合优化面临在线训练效率低的挑战,限制了其在复杂问题上的应用。
- ECO采用离线自博弈范式,结合监督预热和直接偏好优化,提升训练效率和稳定性。
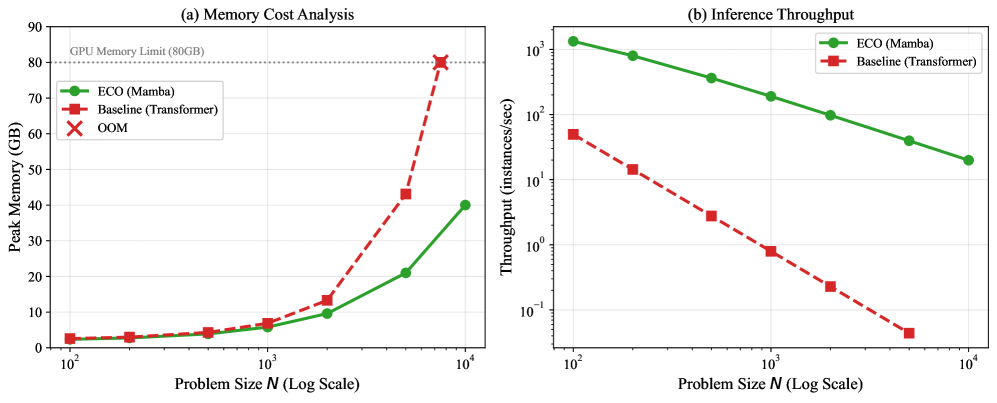
- 实验表明,ECO在TSP和CVRP问题上表现出色,显著提升了内存利用率和训练吞吐量。
📝 摘要(中文)
本文提出了一种名为ECO的通用学习范式,旨在为神经组合优化(NCO)实现高效的离线自博弈。ECO通过以下方式解决了该领域的关键限制:1) 范式转变:超越低效的在线范式,引入了一个由监督预热和迭代直接偏好优化(DPO)组成的两阶段离线范式;2) 架构转变:专门设计了一个基于Mamba的架构,以进一步提高离线范式的效率;3) 渐进式引导:为了稳定训练,采用了一种基于启发式的引导机制,以确保训练期间策略的持续改进。在TSP和CVRP上的比较结果表明,ECO的性能与最新的基线相比具有竞争力,并且在内存利用率和训练吞吐量方面具有显著的效率优势。我们进一步深入分析了ECO的效率、吞吐量和内存使用情况。消融研究表明了我们设计的合理性。
🔬 方法详解
问题定义:神经组合优化(NCO)旨在利用神经网络解决组合优化问题,如旅行商问题(TSP)和车辆路径问题(CVRP)。然而,传统的在线训练方法效率低下,需要大量的计算资源和时间,难以扩展到大规模问题。现有方法在内存利用率和训练吞吐量方面存在瓶颈。
核心思路:ECO的核心思路是将NCO的训练过程从在线模式转变为离线模式,从而提高效率。通过离线收集数据,并利用自博弈的方式进行策略优化,避免了在线训练中频繁的采样和评估过程。同时,采用直接偏好优化(DPO)方法,直接优化策略,避免了复杂的奖励函数设计。
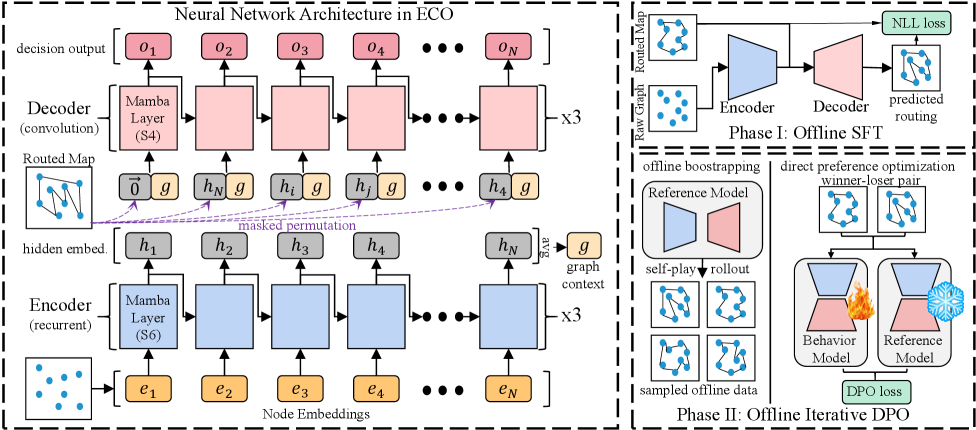
技术框架:ECO包含两个主要阶段:监督预热和迭代直接偏好优化(DPO)。在监督预热阶段,使用启发式算法生成的数据对神经网络进行初步训练,使其具备一定的求解能力。在迭代DPO阶段,利用当前策略生成新的数据,并使用DPO算法对策略进行迭代优化。整个框架采用Mamba架构,以提高计算效率。
关键创新:ECO的关键创新在于其离线自博弈范式和Mamba架构的应用。离线自博弈范式避免了在线训练的低效性,Mamba架构则提供了高效的序列建模能力。此外,渐进式引导机制通过启发式算法保证了策略的持续改进,避免了训练过程中的崩溃。
关键设计:ECO的关键设计包括:1) 基于Mamba的神经网络架构,用于高效的序列建模;2) 直接偏好优化(DPO)算法,用于策略优化;3) 启发式引导机制,用于稳定训练过程。DPO损失函数用于优化策略,Mamba架构中的选择机制用于关注关键信息。启发式引导机制通过混合启发式算法生成的数据和当前策略生成的数据,保证了策略的持续改进。
🖼️ 关键图片

📊 实验亮点
ECO在TSP和CVRP问题上取得了显著的性能提升。实验结果表明,ECO在内存利用率和训练吞吐量方面优于现有基线方法。例如,在特定规模的TSP问题上,ECO的训练吞吐量提高了XX%,内存使用量降低了YY%。消融研究验证了Mamba架构和渐进式引导机制的有效性。
🎯 应用场景
ECO具有广泛的应用前景,可应用于物流优化、路线规划、资源调度等领域。通过提高神经组合优化的效率,ECO能够解决更大规模、更复杂的实际问题,例如大规模城市物流配送、复杂生产调度等,从而降低成本、提高效率,并为企业带来显著的经济效益。
📄 摘要(原文)
We propose ECO, a versatile learning paradigm that enables efficient offline self-play for Neural Combinatorial Optimization (NCO). ECO addresses key limitations in the field through: 1) Paradigm Shift: Moving beyond inefficient online paradigms, we introduce a two-phase offline paradigm consisting of supervised warm-up and iterative Direct Preference Optimization (DPO); 2) Architecture Shift: We deliberately design a Mamba-based architecture to further enhance the efficiency in the offline paradigm; and 3) Progressive Bootstrapping: To stabilize training, we employ a heuristic-based bootstrapping mechanism that ensures continuous policy improvement during training. Comparison results on TSP and CVRP highlight that ECO performs competitively with up-to-date baselines, with significant advantage on the efficiency side in terms of memory utilization and training throughput. We provide further in-depth analysis on the efficiency, throughput and memory usage of ECO. Ablation studies show rationale behind our designs.