Fuz-RL: A Fuzzy-Guided Robust Framework for Safe Reinforcement Learning under Uncertainty
作者: Xu Wan, Chao Yang, Cheng Yang, Jie Song, Mingyang Sun
分类: cs.LG
发布日期: 2026-02-24
💡 一句话要点
提出Fuz-RL,一种模糊逻辑引导的鲁棒强化学习框架,提升不确定性下的安全性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 安全强化学习 鲁棒强化学习 模糊逻辑 不确定性建模 Choquet积分
📋 核心要点
- 现有安全强化学习方法难以应对真实环境中多重不确定性带来的风险评估和决策挑战。
- Fuz-RL利用模糊测度引导,通过Choquet积分估计鲁棒价值函数,提升策略的安全性。
- 实验表明,Fuz-RL能有效集成现有安全RL算法,并在多种不确定性下显著提升安全性和控制性能。
📝 摘要(中文)
安全强化学习(RL)对于在实际应用中实现高性能并确保安全至关重要。然而,真实环境中多种不确定性来源的复杂相互作用给可解释的风险评估和鲁棒决策带来了重大挑战。为了应对这些挑战,我们提出了Fuz-RL,一个模糊测度引导的鲁棒安全强化学习框架。具体来说,我们的框架开发了一种新颖的模糊贝尔曼算子,用于使用Choquet积分估计鲁棒价值函数。理论上,我们证明了求解Fuz-RL问题(以约束马尔可夫决策过程(CMDP)形式)等价于求解分布鲁棒安全强化学习问题(以鲁棒CMDP形式),从而有效地避免了最小-最大优化。在safe-control-gym和safety-gymnasium场景中的经验分析表明,Fuz-RL以无模型的方式有效地与现有的安全RL基线集成,显著提高了在观察、动作和动态中的各种类型不确定性下的安全性和控制性能。
🔬 方法详解
问题定义:论文旨在解决安全强化学习中,由于环境存在多种不确定性(如观测噪声、动作执行误差、动力学模型不确定性)而导致的风险评估不准确和策略鲁棒性不足的问题。现有方法通常难以有效处理这些复杂的不确定性,导致在实际应用中安全性难以保证。
核心思路:论文的核心思路是利用模糊逻辑来建模和处理环境中的不确定性。通过引入模糊测度,可以更灵活地表达不同不确定性来源之间的相互影响,从而更准确地评估风险。同时,利用Choquet积分来聚合不同状态下的价值函数,得到一个鲁棒的价值函数,使得策略在面对不确定性时更加稳健。
技术框架:Fuz-RL框架主要包含以下几个模块:1) 不确定性建模模块:使用模糊测度来描述环境中的不确定性。2) 鲁棒价值函数估计模块:利用模糊贝尔曼算子和Choquet积分来估计鲁棒的价值函数。3) 策略优化模块:基于鲁棒价值函数,优化策略,以最大化期望回报并满足安全约束。整个框架可以与现有的安全强化学习算法无缝集成。
关键创新:该论文的关键创新在于引入了模糊测度和Choquet积分来处理安全强化学习中的不确定性。与传统的基于概率的方法相比,模糊测度可以更灵活地表达不同不确定性来源之间的依赖关系,从而更准确地评估风险。此外,通过理论证明,将Fuz-RL问题转化为求解分布鲁棒安全强化学习问题,避免了复杂的min-max优化。
关键设计:模糊测度的具体形式需要根据具体的应用场景进行设计,可以采用专家知识或数据驱动的方法进行学习。Choquet积分的计算可以使用不同的数值方法,如蒙特卡洛积分等。在策略优化过程中,可以使用现有的安全强化学习算法,如CPO、PPO-Lagrangian等。论文中没有明确指出具体的网络结构,但可以根据具体任务选择合适的网络结构,如MLP、CNN、RNN等。
🖼️ 关键图片


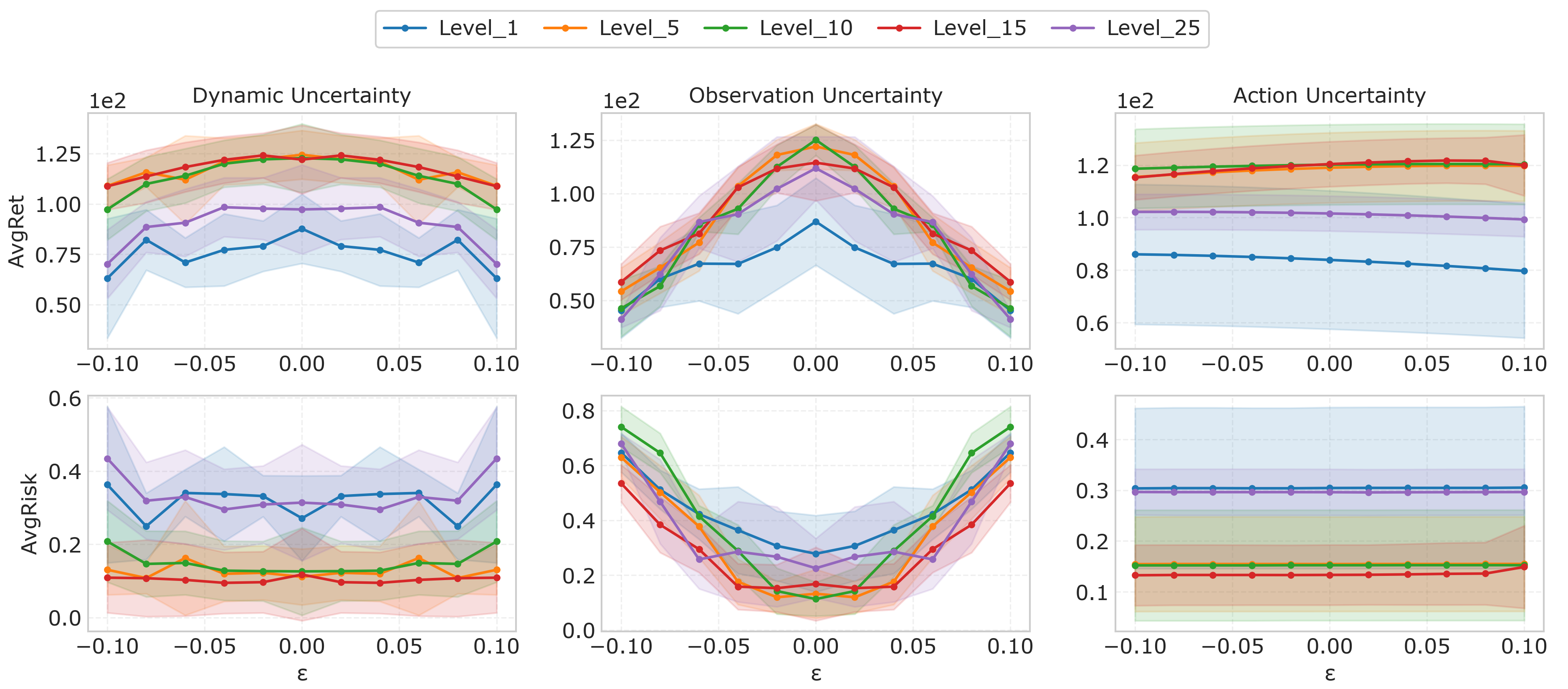
📊 实验亮点
实验结果表明,Fuz-RL能够有效地与现有的安全强化学习基线算法集成,并在safe-control-gym和safety-gymnasium等多个基准测试环境中显著提升安全性和控制性能。具体来说,在存在观测噪声、动作执行误差和动力学模型不确定性的情况下,Fuz-RL能够比基线算法更好地满足安全约束,并获得更高的回报。
🎯 应用场景
Fuz-RL框架可应用于各种需要安全保障的强化学习任务,例如自动驾驶、机器人控制、金融交易等。在这些领域中,环境存在各种不确定性,如果不能有效处理这些不确定性,可能会导致严重的事故或损失。Fuz-RL通过提供一种鲁棒的决策方法,可以显著提高系统的安全性,降低风险,具有重要的实际应用价值。
📄 摘要(原文)
Safe Reinforcement Learning (RL) is crucial for achieving high performance while ensuring safety in real-world applications. However, the complex interplay of multiple uncertainty sources in real environments poses significant challenges for interpretable risk assessment and robust decision-making. To address these challenges, we propose Fuz-RL, a fuzzy measure-guided robust framework for safe RL. Specifically, our framework develops a novel fuzzy Bellman operator for estimating robust value functions using Choquet integrals. Theoretically, we prove that solving the Fuz-RL problem (in Constrained Markov Decision Process (CMDP) form) is equivalent to solving distributionally robust safe RL problems (in robust CMDP form), effectively avoiding min-max optimization. Empirical analyses on safe-control-gym and safety-gymnasium scenarios demonstrate that Fuz-RL effectively integrates with existing safe RL baselines in a model-free manner, significantly improving both safety and control performance under various types of uncertainties in observation, action, and dynamics.