QEDBENCH: Quantifying the Alignment Gap in Automated Evaluation of University-Level Mathematical Proofs
作者: Santiago Gonzalez, Alireza Amiri Bavandpour, Peter Ye, Edward Zhang, Ruslans Aleksejevs, Todor Antić, Polina Baron, Sujeet Bhalerao, Shubhrajit Bhattacharya, Zachary Burton, John Byrne, Hyungjun Choi, Nujhat Ahmed Disha, Koppany István Encz, Yuchen Fang, Robert Joseph George, Ebrahim Ghorbani, Alan Goldfarb, Jing Guo, Meghal Gupta, Stefano Huber, Annika Kanckos, Minjung Kang, Hyun Jong Kim, Dino Lorenzini, Levi Lorenzo, Tianyi Mao, Giovanni Marzenta, Ariane M. Masuda, Lukas Mauth, Ana Mickovic, Andres Miniguano-Trujillo, Antoine Moulin, Wenqi Ni, Tomos Parry, Kevin Ren, Hossein Roodbarani, Mathieu Rundström, Manjil Saikia, Detchat Samart, Rebecca Steiner, Connor Stewart, Dhara Thakkar, Jeffrey Tse, Vasiliki Velona, Yunhai Xiang, Sibel Yalçın, Jun Yan, Ji Zeng, Arman Cohan, Quanquan C. Liu
分类: cs.LG
发布日期: 2026-02-24
🔗 代码/项目: GITHUB
💡 一句话要点
QEDBench:量化大学数学证明自动评估中的对齐差距
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数学证明评估 大型语言模型 对齐差距 AI评判器 QEDBench
📋 核心要点
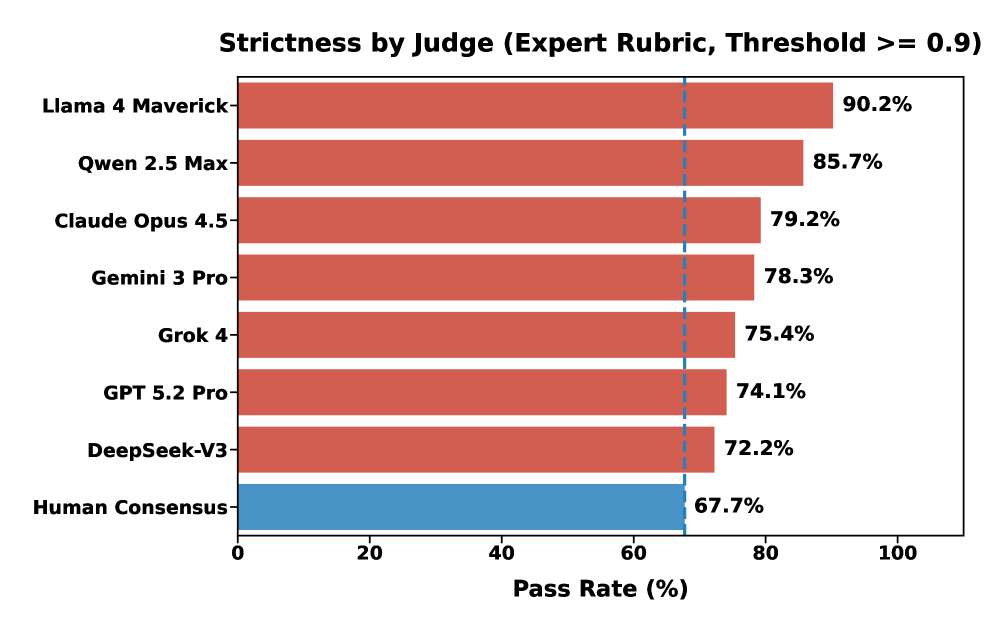
- 现有LLM在基础数学基准上表现良好,但作为评判者评估高等数学证明时,与人类专家存在“对齐差距”,导致评估结果偏差。
- 提出QEDBench,一个大规模双重评分标准对齐基准,通过对比课程评分标准与专家常识,系统性地量化LLM在评估大学数学证明时的对齐程度。
- 实验表明,某些前沿评估器存在显著的积极偏差,且在离散领域,部分模型的评估性能显著下降,揭示了LLM在高等数学评估中的局限性。
📝 摘要(中文)
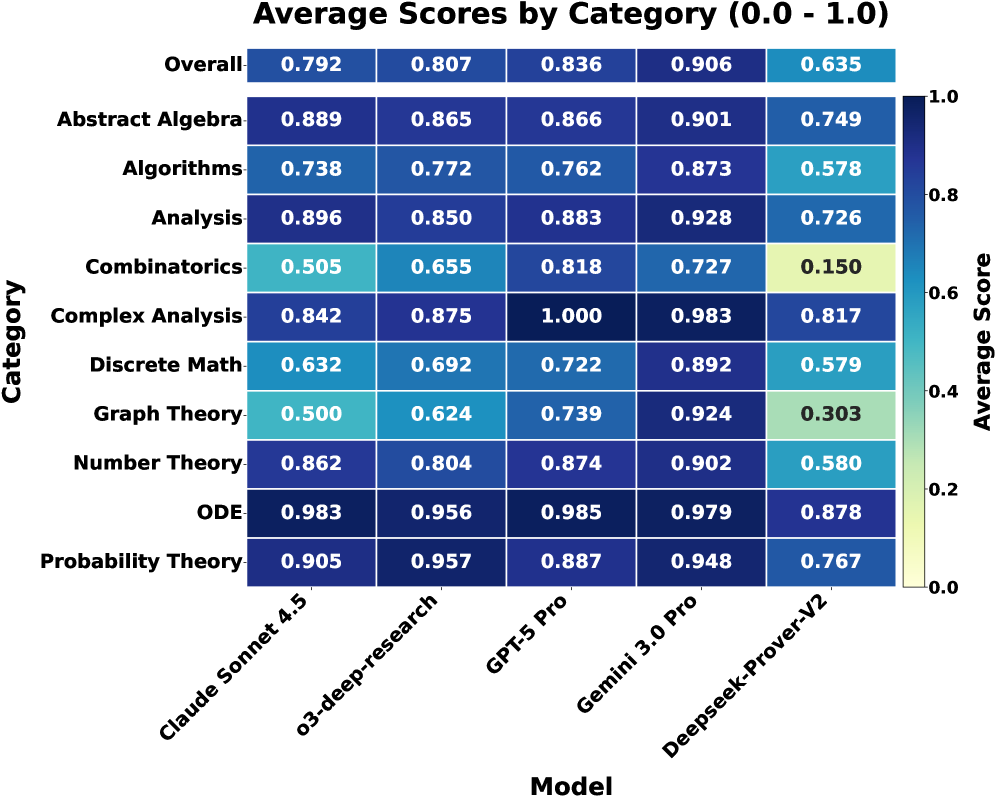
随着大型语言模型(LLMs)在基础基准测试中表现饱和,研究前沿已从生成转向自动评估的可靠性。我们证明,标准的“LLM-as-a-Judge”协议在应用于本科高年级到研究生早期水平的数学时,存在系统性的对齐差距。为了量化这一点,我们引入了QEDBench,这是第一个大规模双重评分标准对齐基准,通过对比课程特定的评分标准与专家常识标准,系统地衡量大学水平数学证明与人类专家的对齐程度。通过部署双重评估矩阵(7名评审员 x 5个求解器)以及1000多个小时的人工评估,我们发现某些前沿评估器,如Claude Opus 4.5、DeepSeek-V3、Qwen 2.5 Max和Llama 4 Maverick,表现出显著的积极偏差(平均得分分别膨胀高达+0.18、+0.20、+0.30和+0.36)。此外,我们还发现离散领域存在关键的推理差距:虽然Gemini 3.0 Pro实现了最先进的性能(0.91的平均人工评估得分),但其他推理模型,如GPT-5 Pro和Claude Sonnet 4.5,在离散领域中的性能显著下降。具体而言,它们在离散数学中的平均人工评估得分分别降至0.72和0.63,在图论中降至0.74和0.50。除了这些研究结果外,我们还发布了QEDBench作为公共基准,用于评估和改进AI评判器。我们的基准已公开发布在https://github.com/qqliu/Yale-QEDBench。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在自动评估大学水平数学证明时存在的“对齐差距”问题。现有方法,即“LLM-as-a-Judge”协议,在评估高等数学证明时,无法准确反映人类专家的判断标准,导致评估结果出现偏差。这种偏差可能源于LLM对课程特定评分标准的过度依赖,而忽略了数学领域的常识性知识。
核心思路:论文的核心思路是通过构建一个大规模的双重评分标准对齐基准QEDBench,来系统地量化LLM在评估数学证明时的对齐程度。QEDBench包含两套评分标准:一套是课程特定的评分标准,另一套是专家常识标准。通过对比LLM在这两套标准下的评估结果,可以揭示LLM的评估偏差,并分析其原因。
技术框架:QEDBench的整体框架包括以下几个主要组成部分:1) 数据集构建:收集大学水平的数学证明题,并由人类专家进行标注,形成包含课程特定评分和专家常识评分的数据集。2) 评估矩阵构建:设计一个双重评估矩阵,包含多个LLM评估器和多个人类评审员,对数据集中的数学证明进行评估。3) 对齐程度量化:通过对比LLM和人类评审员的评估结果,计算LLM的对齐程度,并分析其偏差。4) 基准发布:将QEDBench作为公共基准发布,供研究人员评估和改进AI评判器。
关键创新:QEDBench的关键创新在于其双重评分标准的设计。通过同时考虑课程特定评分标准和专家常识标准,可以更全面地评估LLM在评估数学证明时的能力。此外,QEDBench的大规模数据集和双重评估矩阵,为系统地量化LLM的对齐程度提供了可靠的基础。
关键设计:QEDBench的关键设计包括:1) 数据集的规模:QEDBench包含1000+小时的人工评估数据,保证了评估结果的统计显著性。2) 评估矩阵的设计:QEDBench的评估矩阵包含7名人类评审员和5个LLM评估器,保证了评估结果的客观性和可靠性。3) 对齐程度的量化指标:论文设计了一系列指标来量化LLM的对齐程度,包括平均得分膨胀、离散领域性能下降等。
🖼️ 关键图片

📊 实验亮点
实验结果表明,某些前沿评估器如Claude Opus 4.5、DeepSeek-V3、Qwen 2.5 Max和Llama 4 Maverick,存在显著的积极偏差,平均得分分别膨胀高达+0.18、+0.20、+0.30和+0.36。此外,Gemini 3.0 Pro在离散数学和图论等离散领域表现优异(0.91),但GPT-5 Pro和Claude Sonnet 4.5的性能显著下降,分别降至0.72/0.63和0.74/0.50。
🎯 应用场景
QEDBench的研究成果可应用于提升AI辅助教育系统的质量,尤其是在高等数学领域。通过使用QEDBench评估和改进AI评判器,可以提高自动评估的准确性和可靠性,为学生提供更有效的学习反馈。此外,该研究也有助于开发更可靠的AI评估系统,用于其他需要专业知识的领域。
📄 摘要(原文)
As Large Language Models (LLMs) saturate elementary benchmarks, the research frontier has shifted from generation to the reliability of automated evaluation. We demonstrate that standard "LLM-as-a-Judge" protocols suffer from a systematic Alignment Gap when applied to upper-undergraduate to early graduate level mathematics. To quantify this, we introduce QEDBench, the first large-scale dual-rubric alignment benchmark to systematically measure alignment with human experts on university-level math proofs by contrasting course-specific rubrics against expert common knowledge criteria. By deploying a dual-evaluation matrix (7 judges x 5 solvers) against 1,000+ hours of human evaluation, we reveal that certain frontier evaluators like Claude Opus 4.5, DeepSeek-V3, Qwen 2.5 Max, and Llama 4 Maverick exhibit significant positive bias (up to +0.18, +0.20, +0.30, +0.36 mean score inflation, respectively). Furthermore, we uncover a critical reasoning gap in the discrete domain: while Gemini 3.0 Pro achieves state-of-the-art performance (0.91 average human evaluation score), other reasoning models like GPT-5 Pro and Claude Sonnet 4.5 see their performance significantly degrade in discrete domains. Specifically, their average human evaluation scores drop to 0.72 and 0.63 in Discrete Math, and to 0.74 and 0.50 in Graph Theory. In addition to these research results, we also release QEDBench as a public benchmark for evaluating and improving AI judges. Our benchmark is publicly published at https://github.com/qqliu/Yale-QEDBench.