Actor-Curator: Co-adaptive Curriculum Learning via Policy-Improvement Bandits for RL Post-Training
作者: Zhengyao Gu, Jonathan Light, Raul Astudillo, Ziyu Ye, Langzhou He, Henry Peng Zou, Wei Cheng, Santiago Paternain, Philip S. Yu, Yisong Yue
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-02-24
备注: 37 pages, 8 figures, 1 table. Preprint under review. Equal contribution by first two authors
💡 一句话要点
提出Actor-Curator,通过策略提升Bandit算法实现LLM后训练的协同自适应课程学习。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 课程学习 强化学习 大型语言模型 后训练 Bandit算法 策略优化 自适应学习
📋 核心要点
- 大规模异构数据集上的强化学习后训练对LLM至关重要,但缺乏有效的课程学习方法。
- Actor-Curator通过学习神经Curator动态选择训练问题,直接优化策略性能提升。
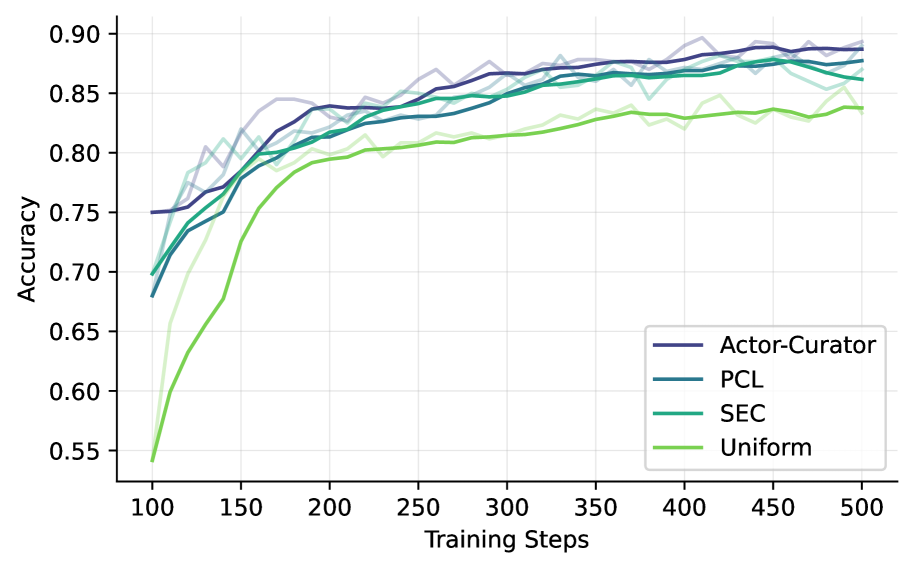
- 实验表明,Actor-Curator在推理任务上显著优于现有基线,并提升了训练效率。
📝 摘要(中文)
本文提出Actor-Curator,一个可扩展且全自动的课程学习框架,用于大型语言模型(LLM)的强化学习后训练。Actor-Curator学习一个神经Curator,通过直接优化预期策略性能提升,从大型问题库中动态选择训练问题。我们将问题选择建模为一个非平稳随机Bandit问题,推导出一个基于在线随机镜像下降的原则性损失函数,并在部分反馈下建立遗憾保证。实验结果表明,Actor-Curator在各种具有挑战性的推理基准测试中始终优于均匀采样和强大的课程基线,证明了其改进的训练稳定性和效率。值得注意的是,相对于最强的基线,它在AIME2024上实现了28.6%的相对收益,在ARC-1D上实现了30.5%的相对收益,并实现了高达80%的加速。这些结果表明,Actor-Curator是一种强大而实用的LLM可扩展后训练方法。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)通过强化学习进行后训练时,如何有效地进行课程学习的问题。现有的方法,如均匀采样,无法充分利用大规模异构数据集中的信息,导致训练效率低下和性能提升受限。此外,手动设计的课程学习策略难以适应不同任务和模型的特点,泛化能力较差。
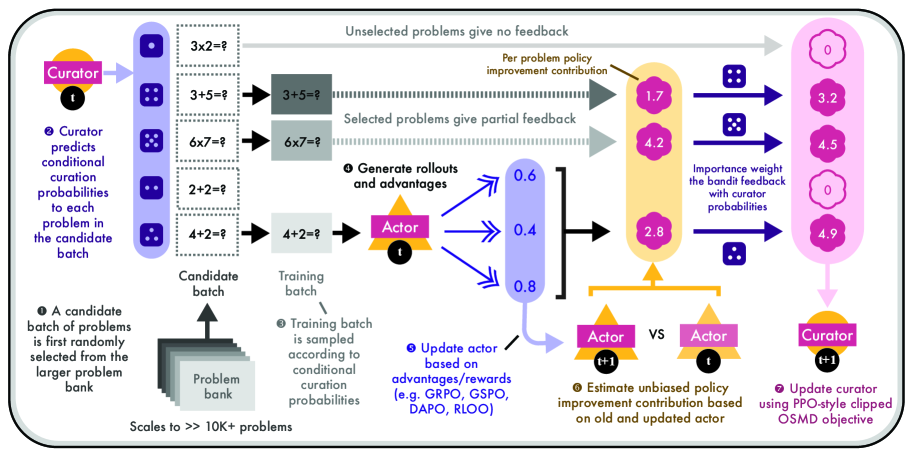
核心思路:论文的核心思路是将课程学习问题建模为一个非平稳随机Bandit问题,并设计一个神经Curator来动态选择训练问题。Curator的目标是最大化策略的预期性能提升,即选择那些能够使模型学习到最多知识的问题。通过在线学习的方式,Curator能够不断适应策略的变化,从而实现协同自适应的课程学习。
技术框架:Actor-Curator框架包含两个主要组成部分:Actor和Curator。Actor是待训练的LLM,Curator是一个神经问题选择器。训练过程如下:1) Curator从问题库中选择一批问题;2) Actor在这些问题上进行训练,并更新策略;3) Actor将训练结果(例如,奖励、损失)反馈给Curator;4) Curator根据反馈更新问题选择策略,以便在下一轮选择更有利于策略提升的问题。这个过程迭代进行,直到Actor达到预定的性能目标。
关键创新:论文的关键创新在于将课程学习问题建模为一个非平稳随机Bandit问题,并设计了一个能够直接优化策略性能提升的神经Curator。与传统的课程学习方法相比,Actor-Curator能够自动地学习问题选择策略,无需人工干预。此外,通过在线学习的方式,Curator能够不断适应策略的变化,从而实现协同自适应的课程学习。
关键设计:Curator采用神经网络结构,输入是问题的特征向量和Actor的当前策略,输出是每个问题的选择概率。论文使用基于在线随机镜像下降的损失函数来训练Curator,该损失函数能够保证Curator的遗憾值是有界的。此外,论文还设计了一种部分反馈机制,即Curator只能观察到部分问题的训练结果,从而提高了算法的效率。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Actor-Curator在AIME2024和ARC-1D等具有挑战性的推理基准测试中,相对于最强的基线分别实现了28.6%和30.5%的相对收益。此外,Actor-Curator还实现了高达80%的训练加速,证明了其在提高训练效率方面的优势。这些结果表明,Actor-Curator是一种强大而实用的LLM可扩展后训练方法。
🎯 应用场景
Actor-Curator框架可广泛应用于大型语言模型的强化学习后训练,尤其是在需要处理大规模异构数据集的场景下。例如,可以用于提升LLM在问答、推理、代码生成等任务上的性能。该方法还可以应用于机器人控制、游戏AI等领域,通过自动化的课程学习,提高智能体的学习效率和泛化能力。
📄 摘要(原文)
Post-training large foundation models with reinforcement learning typically relies on massive and heterogeneous datasets, making effective curriculum learning both critical and challenging. In this work, we propose ACTOR-CURATOR, a scalable and fully automated curriculum learning framework for reinforcement learning post-training of large language models (LLMs). ACTOR-CURATOR learns a neural curator that dynamically selects training problems from large problem banks by directly optimizing for expected policy performance improvement. We formulate problem selection as a non-stationary stochastic bandit problem, derive a principled loss function based on online stochastic mirror descent, and establish regret guarantees under partial feedback. Empirically, ACTOR-CURATOR consistently outperforms uniform sampling and strong curriculum baselines across a wide range of challenging reasoning benchmarks, demonstrating improved training stability and efficiency. Notably, it achieves relative gains of 28.6% on AIME2024 and 30.5% on ARC-1D over the strongest baseline and up to 80% speedup. These results suggest that ACTOR-CURATOR is a powerful and practical approach for scalable LLM post-training.