A Generalized Apprenticeship Learning Framework for Capturing Evolving Student Pedagogical Strategies
作者: Md Mirajul Islam, Xi Yang, Adittya Soukarjya Saha, Rajesh Debnath, Min Chi
分类: cs.LG, cs.AI
发布日期: 2026-02-24
备注: 16 pages
期刊: AIED 2025, LNCS 15879, Springer, pp. 393-408
DOI: 10.1007/978-3-031-98420-4_28
💡 一句话要点
提出THEMES框架,利用广义学徒学习捕获学生动态演化的教学策略
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 学徒学习 逆强化学习 智能辅导系统 教学策略 动态奖励函数
📋 核心要点
- DRL在教育技术应用中面临样本效率和奖励函数设计的挑战。
- THEMES框架利用学徒学习,通过少量专家演示学习教学策略。
- 实验表明,THEMES性能优于现有方法,AUC达0.899,Jaccard系数达0.653。
📝 摘要(中文)
近年来,强化学习(RL)和深度强化学习(DRL)发展迅速,并已成功应用于智能辅导系统(ITS)等电子学习环境。尽管取得了巨大成功,但由于样本效率低下和奖励函数难以设计等主要挑战,DRL在教育技术中的更广泛应用受到限制。相比之下,学徒学习(AL)使用少量专家演示来推断专家的潜在奖励函数,并导出能够推广和复制最佳行为的决策策略。在这项工作中,我们利用广义AL框架THEMES,通过捕获专家学生学习过程的复杂性来诱导有效的教学策略,其中多个奖励函数可能会随着时间的推移而动态演变。我们针对六个最先进的基线评估了THEMES的有效性,证明了其卓越的性能,并突出了其作为诱导有效教学策略的强大替代方案的潜力,并表明它仅使用前一个学期的18条轨迹来预测后一个学期的学生教学决策,即可实现高性能,AUC为0.899,Jaccard系数为0.653。
🔬 方法详解
问题定义:论文旨在解决智能辅导系统中,如何高效地学习并应用有效的教学策略的问题。现有基于强化学习的方法通常需要大量的样本数据进行训练,且奖励函数的设计非常困难,直接影响策略的优劣。这些痛点限制了DRL在教育领域的广泛应用。
核心思路:论文的核心思路是利用学徒学习(Apprenticeship Learning)框架,通过模仿专家(例如优秀的教师)的教学行为,来学习有效的教学策略。与直接设计奖励函数不同,学徒学习通过观察专家的行为轨迹,反推出专家潜在的奖励函数,从而学习到更符合实际需求的策略。此外,论文还考虑了学生学习过程的动态性,即学生的学习状态和需求会随着时间变化,因此教学策略也应该随之演变。
技术框架:论文提出的THEMES框架基于广义学徒学习,其整体流程如下:1) 收集专家(教师)的教学轨迹数据,包括学生的学习状态、教师的教学决策等;2) 利用逆强化学习(Inverse Reinforcement Learning)算法,从专家轨迹中推断出潜在的奖励函数;3) 使用推断出的奖励函数,训练一个强化学习模型,学习最优的教学策略;4) 考虑到学生学习过程的动态性,THEMES框架允许奖励函数随着时间演变,从而能够适应不同阶段学生的学习需求。
关键创新:论文的关键创新在于将广义学徒学习框架应用于智能辅导系统,并考虑了学生学习过程的动态性。与传统的学徒学习方法相比,THEMES框架能够学习到更灵活、更适应学生需求的教学策略。此外,THEMES框架避免了手动设计奖励函数的难题,降低了应用门槛。
关键设计:THEMES框架的关键设计包括:1) 使用最大熵逆强化学习(Maximum Entropy Inverse Reinforcement Learning)算法来推断奖励函数,该算法能够更好地处理专家行为中的不确定性;2) 使用循环神经网络(Recurrent Neural Network)来建模学生的学习状态,从而能够捕捉学生学习过程中的时序依赖关系;3) 使用动态奖励函数来适应学生学习过程的动态性,奖励函数的演变可以通过一个时间序列模型来建模。
🖼️ 关键图片

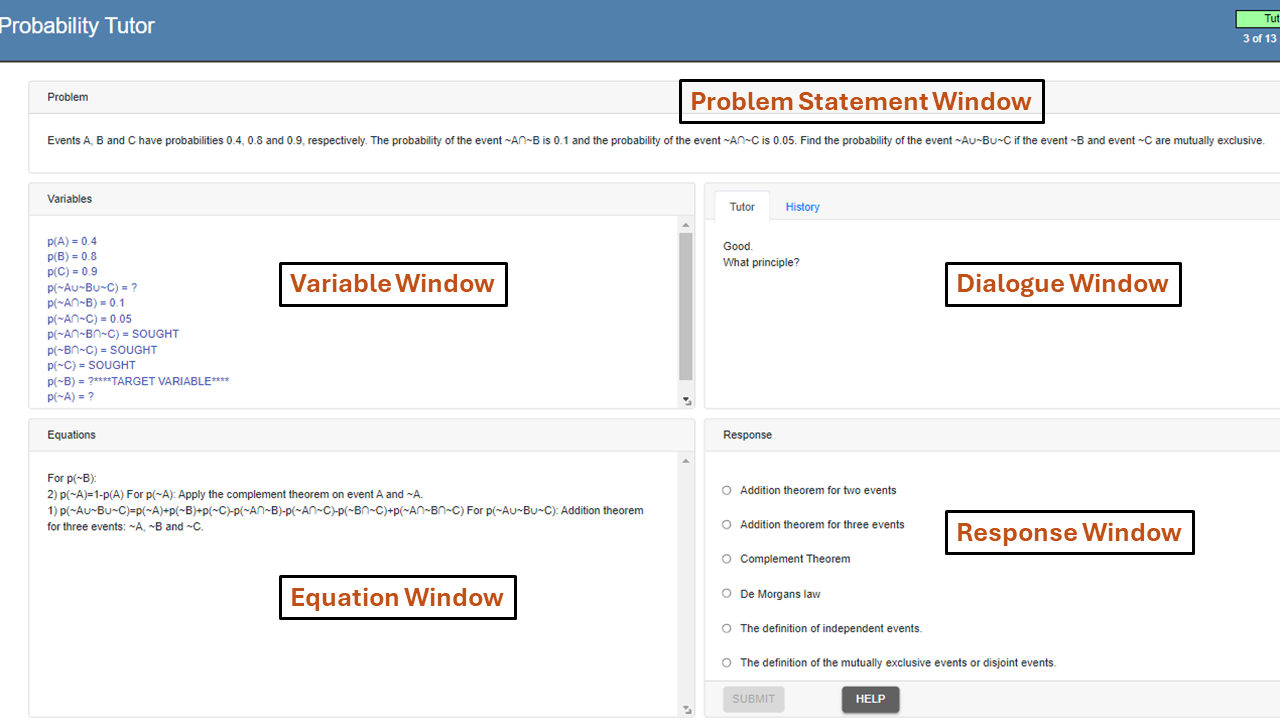

📊 实验亮点
实验结果表明,THEMES框架在预测学生教学决策方面表现出色,AUC达到0.899,Jaccard系数达到0.653,显著优于六个最先进的基线方法。该结果验证了THEMES框架在学习有效教学策略方面的潜力,并表明其能够仅使用少量专家数据即可实现高性能。
🎯 应用场景
该研究成果可应用于智能辅导系统、在线教育平台等领域,帮助教师或系统更有效地制定教学策略,提升学生的学习效果。通过模仿优秀教师的教学行为,可以降低教学成本,提高教学质量,实现个性化教学。未来,该技术还可以扩展到其他教育领域,例如职业技能培训等。
📄 摘要(原文)
Reinforcement Learning (RL) and Deep Reinforcement Learning (DRL) have advanced rapidly in recent years and have been successfully applied to e-learning environments like intelligent tutoring systems (ITSs). Despite great success, the broader application of DRL to educational technologies has been limited due to major challenges such as sample inefficiency and difficulty designing the reward function. In contrast, Apprenticeship Learning (AL) uses a few expert demonstrations to infer the expert's underlying reward functions and derive decision-making policies that generalize and replicate optimal behavior. In this work, we leverage a generalized AL framework, THEMES, to induce effective pedagogical policies by capturing the complexities of the expert student learning process, where multiple reward functions may dynamically evolve over time. We evaluate the effectiveness of THEMES against six state-of-the-art baselines, demonstrating its superior performance and highlighting its potential as a powerful alternative for inducing effective pedagogical policies and show that it can achieve high performance, with an AUC of 0.899 and a Jaccard of 0.653, using only 18 trajectories of a previous semester to predict student pedagogical decisions in a later semester.