Wireless Federated Multi-Task LLM Fine-Tuning via Sparse-and-Orthogonal LoRA
作者: Nuocheng Yang, Sihua Wang, Ouwen Huan, Mingzhe Chen, Tony Q. S. Quek, Changchuan Yin
分类: cs.LG, cs.AI
发布日期: 2026-02-24
备注: 13 pages, 5 figures
💡 一句话要点
提出稀疏正交LoRA的无线联邦多任务LLM微调方法,解决异构数据下的知识冲突问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 大型语言模型 低秩适应 稀疏性 正交性 多任务学习 无线通信 混合专家模型
📋 核心要点
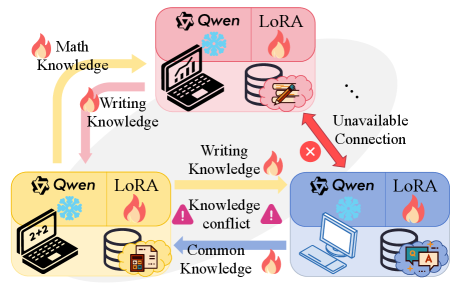
- 传统联邦学习在异构数据下微调LLM时,面临知识遗忘、通信低效和知识干扰等问题。
- 论文提出稀疏正交LoRA,通过正交约束消除更新冲突,并结合拓扑优化和MoE机制。
- 实验表明,该方法显著降低通信开销(73%)并提升平均性能(5%),优于传统LoRA。
📝 摘要(中文)
本文提出了一种基于低秩适应(LoRA)的去中心化联邦学习(DFL)方法,使具有多任务数据集的移动设备能够通过无线连接与邻近设备交换本地更新的参数,从而协同微调大型语言模型(LLM)以进行知识集成。然而,直接聚合在异构数据集上微调的参数会导致三个主要问题:(i)微调过程中的灾难性知识遗忘,源于数据异构性引起的冲突更新方向;(ii)模型聚合过程中的低效通信和收敛,由于带宽密集型冗余模型传输;(iii)推理过程中的多任务知识干扰,源于不兼容的知识表示共存。为了解决这些问题,我们首先提出了一种稀疏正交LoRA,确保模型更新之间的正交性,以消除微调期间的方向冲突。然后,我们分析了设备连接拓扑如何影响多任务性能,从而提出了基于聚类的拓扑设计。最后,我们提出了一种隐式混合专家(MoE)机制,以避免推理过程中不兼容知识的共存。仿真结果表明,与传统的LoRA方法相比,所提出的方法有效地降低了高达73%的通信资源消耗,并提高了5%的平均性能。
🔬 方法详解
问题定义:论文旨在解决无线联邦学习场景下,使用LoRA微调LLM时,由于设备上的数据异构性导致的知识遗忘、通信效率低下以及推理时的多任务知识干扰问题。现有方法直接聚合不同任务的LoRA参数,忽略了任务间的冲突和冗余,导致模型性能下降和通信开销增加。
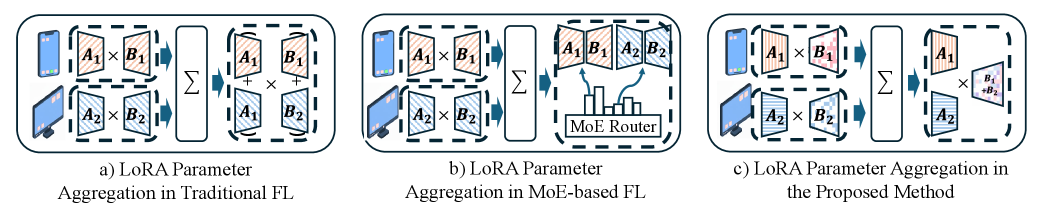
核心思路:论文的核心思路是通过引入稀疏性和正交性约束来优化LoRA的更新过程,并结合拓扑优化和隐式MoE机制来解决上述问题。稀疏正交LoRA旨在消除不同任务更新方向的冲突,提高模型聚合的效率。拓扑优化根据设备间的相似性进行聚类,减少不必要的通信。隐式MoE机制则在推理时动态选择合适的专家,避免知识干扰。
技术框架:整体框架包括三个主要阶段:(1) 稀疏正交LoRA微调:每个设备使用本地数据微调LLM,并应用稀疏性和正交性约束。(2) 基于聚类的拓扑设计:根据设备数据的相似性进行聚类,构建通信拓扑。(3) 隐式MoE推理:在推理时,根据输入动态选择合适的专家进行预测。
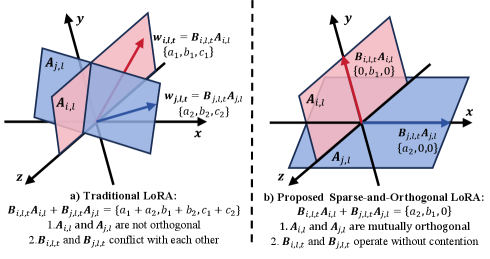
关键创新:最重要的技术创新点在于稀疏正交LoRA的设计。与传统LoRA相比,该方法通过引入稀疏性和正交性约束,使得不同任务的更新方向尽可能正交,从而避免了知识冲突和冗余。此外,基于聚类的拓扑设计和隐式MoE机制也进一步提升了模型的性能和效率。
关键设计:稀疏正交LoRA的关键设计包括:(1) 稀疏性约束:通过L1正则化或其他稀疏化方法,限制LoRA参数的数量,减少通信开销。(2) 正交性约束:通过添加正交损失函数,鼓励不同任务的LoRA参数矩阵之间的正交性。(3) 聚类算法:使用K-means或其他聚类算法,根据设备数据的相似性进行聚类。(4) 隐式MoE:使用注意力机制或其他动态路由方法,根据输入动态选择合适的专家。
🖼️ 关键图片
📊 实验亮点
实验结果表明,与传统的LoRA方法相比,所提出的稀疏正交LoRA方法能够有效地降低通信资源消耗高达73%,并提高平均性能5%。这些结果验证了该方法在解决异构数据下的知识冲突和提高通信效率方面的有效性。
🎯 应用场景
该研究成果可应用于各种无线联邦学习场景,例如移动设备上的个性化推荐、医疗诊断和金融风控等。通过降低通信开销和提高模型性能,该方法能够更好地支持在资源受限的设备上进行LLM的微调和部署,从而实现更广泛的应用。
📄 摘要(原文)
Decentralized federated learning (DFL) based on low-rank adaptation (LoRA) enables mobile devices with multi-task datasets to collaboratively fine-tune a large language model (LLM) by exchanging locally updated parameters with a subset of neighboring devices via wireless connections for knowledge integration.However, directly aggregating parameters fine-tuned on heterogeneous datasets induces three primary issues across the DFL life-cycle: (i) \textit{catastrophic knowledge forgetting during fine-tuning process}, arising from conflicting update directions caused by data heterogeneity; (ii) \textit{inefficient communication and convergence during model aggregation process}, due to bandwidth-intensive redundant model transmissions; and (iii) \textit{multi-task knowledge interference during inference process}, resulting from incompatible knowledge representations coexistence during inference. To address these issues in a fully decentralized scenario, we first propose a sparse-and-orthogonal LoRA that ensures orthogonality between model updates to eliminate direction conflicts during fine-tuning.Then, we analyze how device connection topology affects multi-task performance, prompting a cluster-based topology design during aggregation.Finally, we propose an implicit mixture of experts (MoE) mechanism to avoid the coexistence of incompatible knowledge during inference. Simulation results demonstrate that the proposed approach effectively reduces communication resource consumption by up to $73\%$ and enhances average performance by $5\%$ compared with the traditional LoRA method.