LAD: Learning Advantage Distribution for Reasoning
作者: Wendi Li, Sharon Li
分类: cs.LG
发布日期: 2026-02-23
💡 一句话要点
提出LAD:通过学习优势分布提升大模型推理能力,增强多样性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大模型推理 优势分布 分布匹配 生成多样性
📋 核心要点
- 现有强化学习方法在训练大模型推理时,易过拟合主要奖励信号,忽略其他有效推理路径。
- LAD通过学习优势分布,而非直接最大化优势,鼓励探索更多样化的推理轨迹。
- 实验表明,LAD在数学和代码推理任务中,能有效提升大模型的准确性和生成多样性。
📝 摘要(中文)
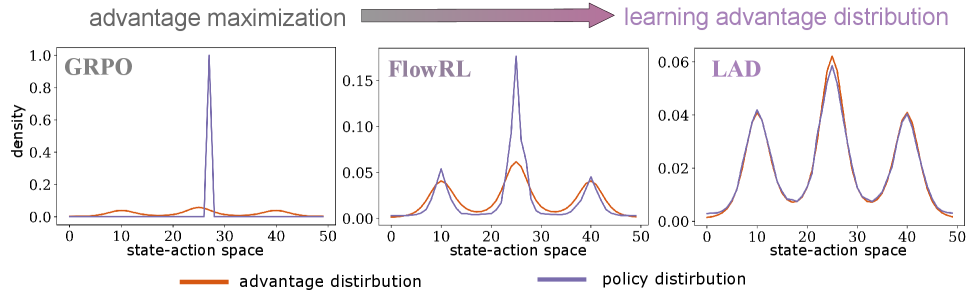
当前用于大模型推理的强化学习目标主要集中在最大化期望奖励。这种范式可能导致对主要奖励信号的过拟合,而忽略了其他有效的推理轨迹,从而限制了多样性和探索。为了解决这个问题,我们引入了学习优势分布(LAD),这是一个分布匹配框架,它用学习优势诱导的分布来代替优势最大化。通过建立最优策略更新和基于优势的目标分布之间的等价性,我们推导出一个实用的LAD目标,该目标被表述为最小化策略诱导分布和优势诱导分布之间的$f$-散度。这产生了一个梯度更新,增加了高优势响应的可能性,同时抑制了过度自信的概率增长,从而防止了崩溃,而不需要辅助熵正则化。与GRPO相比,LAD没有额外的训练成本,并且可以自然地扩展到LLM的后训练。在一个受控的bandit设置中,LAD忠实地恢复了多模态优势分布,验证了理论公式。在多个LLM骨干网络上的数学和代码推理任务的实验表明,LAD可靠地提高了准确性和生成多样性。
🔬 方法详解
问题定义:现有大模型推理的强化学习方法,如直接奖励最大化,容易过拟合主要的奖励信号,导致模型只关注少数几种“正确”的推理路径,而忽略了其他同样有效但奖励较低的推理方式。这限制了模型的探索能力和生成多样性,使得模型在面对复杂问题时容易陷入局部最优。
核心思路:LAD的核心思想是将策略优化问题转化为一个分布匹配问题。具体来说,LAD不再直接最大化优势函数,而是学习一个由优势函数诱导的目标分布。通过最小化策略分布和优势诱导分布之间的差异,LAD能够鼓励模型探索具有较高优势的行动,同时避免过度自信的概率增长,从而提高生成多样性。
技术框架:LAD的整体框架包括以下几个步骤:1. 使用当前策略生成样本;2. 计算每个样本的优势函数;3. 基于优势函数构建优势诱导的目标分布;4. 使用$f$-散度最小化策略分布和目标分布之间的差异,更新策略参数。这个过程可以迭代进行,直到策略收敛。
关键创新:LAD的关键创新在于将优势最大化问题转化为分布匹配问题。与传统的优势最大化方法相比,LAD能够更好地平衡探索和利用,避免过拟合主要奖励信号,从而提高模型的泛化能力和生成多样性。此外,LAD不需要额外的熵正则化,降低了训练的复杂性。
关键设计:LAD的关键设计包括:1. 使用$f$-散度作为策略分布和目标分布之间的距离度量。作者选择了合适的$f$-散度形式,使得目标函数易于优化;2. 优势诱导分布的构建方式。作者基于优势函数设计了一个合适的分布形式,使得该分布能够反映不同行动的相对优势;3. 梯度更新策略。作者推导出了一个实用的梯度更新公式,该公式能够有效地提高高优势响应的可能性,同时抑制过度自信的概率增长。
🖼️ 关键图片
📊 实验亮点
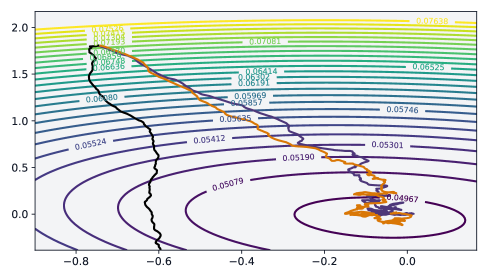
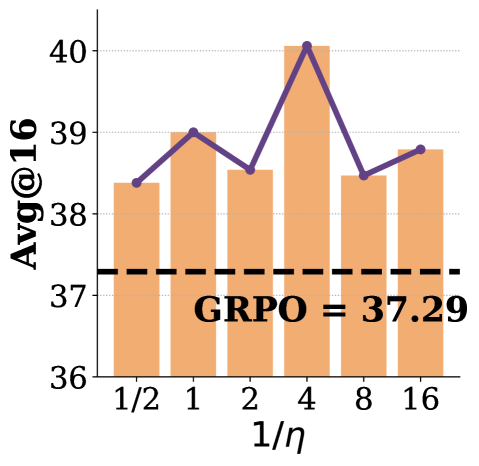
实验结果表明,LAD在数学和代码推理任务中,能够显著提高大模型的准确性和生成多样性。例如,在某些任务上,LAD可以将模型的准确率提高5%以上,同时显著增加生成结果的多样性。此外,LAD在受控的bandit设置中,能够忠实地恢复多模态优势分布,验证了理论公式的有效性。
🎯 应用场景
LAD方法具有广泛的应用前景,可以应用于各种需要大模型进行推理的任务中,例如数学问题求解、代码生成、自然语言推理等。通过提高模型的准确性和生成多样性,LAD可以帮助大模型更好地解决复杂问题,并生成更具创造性的结果。此外,LAD还可以应用于模型的后训练阶段,进一步提升模型的性能。
📄 摘要(原文)
Current reinforcement learning objectives for large-model reasoning primarily focus on maximizing expected rewards. This paradigm can lead to overfitting to dominant reward signals, while neglecting alternative yet valid reasoning trajectories, thereby limiting diversity and exploration. To address this issue, we introduce Learning Advantage Distributions (LAD), a distribution-matching framework that replaces advantage maximization with learning the advantage-induced distribution. By establishing the equivalence between the optimal policy update and an advantage-based target distribution, we derive a practical LAD objective formulated as minimizing an $f$-divergence between the policy-induced and advantage-induced distributions. This yields a gradient update that increases likelihood for high-advantage responses while suppressing over-confident probability growth, preventing collapse without requiring auxiliary entropy regularization. LAD incurs no extra training cost compared to GRPO and scales naturally to LLM post-training. In a controlled bandit setting, LAD faithfully recovers the multimodal advantage distribution, validating the theoretical formulation. Experiments on math and code reasoning tasks across several LLM backbones show that LAD reliably improves both accuracy and generative diversity.