BarrierSteer: LLM Safety via Learning Barrier Steering
作者: Thanh Q. Tran, Arun Verma, Kiwan Wong, Bryan Kian Hsiang Low, Daniela Rus, Wei Xiao
分类: cs.LG, cs.AI
发布日期: 2026-02-23
备注: This paper introduces SafeBarrier, a framework that enforces safety in large language models by steering their latent representations with control barrier functions during inference, reducing adversarial and unsafe outputs
💡 一句话要点
BarrierSteer:通过学习屏障导向实现LLM安全性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型安全 控制屏障函数 对抗攻击防御 安全约束学习 潜在空间控制
📋 核心要点
- 大型语言模型易受攻击,产生不安全内容,限制了其在高风险场景的应用。
- BarrierSteer通过学习非线性安全约束,并利用控制屏障函数引导模型生成安全响应。
- 实验表明,BarrierSteer有效降低了对抗攻击成功率,减少了不安全内容生成,优于现有方法。
📝 摘要(中文)
尽管大型语言模型(LLM)在各种任务中表现出色,但它们容易受到对抗攻击和生成不安全内容的影响,这仍然是部署的主要障碍,尤其是在高风险环境中。为了应对这一挑战,需要既实用有效又具有严格理论支持的安全机制。我们提出了一种名为BarrierSteer的新框架,该框架通过将学习到的非线性安全约束直接嵌入到模型的潜在表示空间中来形式化响应安全性。BarrierSteer采用基于控制屏障函数(CBF)的导向机制,以高精度有效地检测和防止推理期间的不安全响应轨迹。通过高效的约束合并来执行多个安全约束,而无需修改底层LLM参数,BarrierSteer保留了模型的原始能力和性能。我们提供的理论结果表明,在潜在空间中应用CBF提供了一种有原则且计算高效的方法来实施安全性。我们在多个模型和数据集上的实验表明,BarrierSteer大大降低了对抗成功率,减少了不安全生成,并且优于现有方法。
🔬 方法详解
问题定义:大型语言模型(LLM)在生成文本时,容易产生不安全、有害或违反道德规范的内容。现有的安全机制往往需要修改LLM的参数,影响其原始性能,或者在检测不安全内容时效率较低,无法有效防止不安全响应的产生。因此,如何在不影响LLM性能的前提下,高效、可靠地保证其输出的安全性是一个亟待解决的问题。
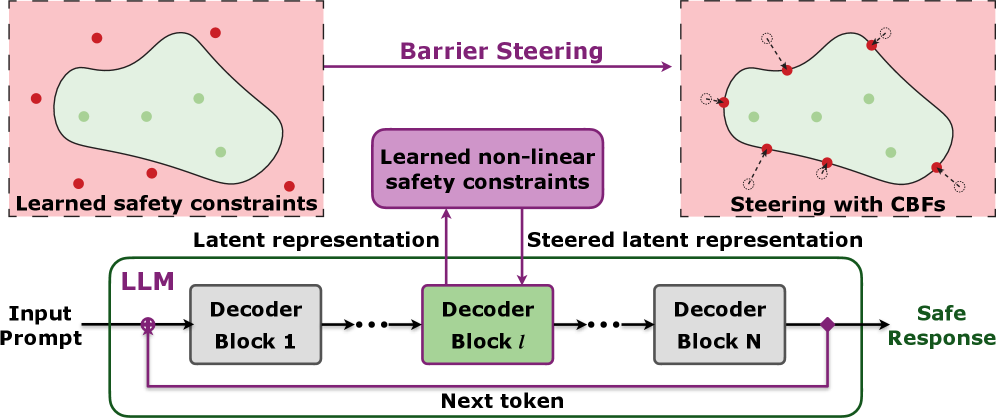
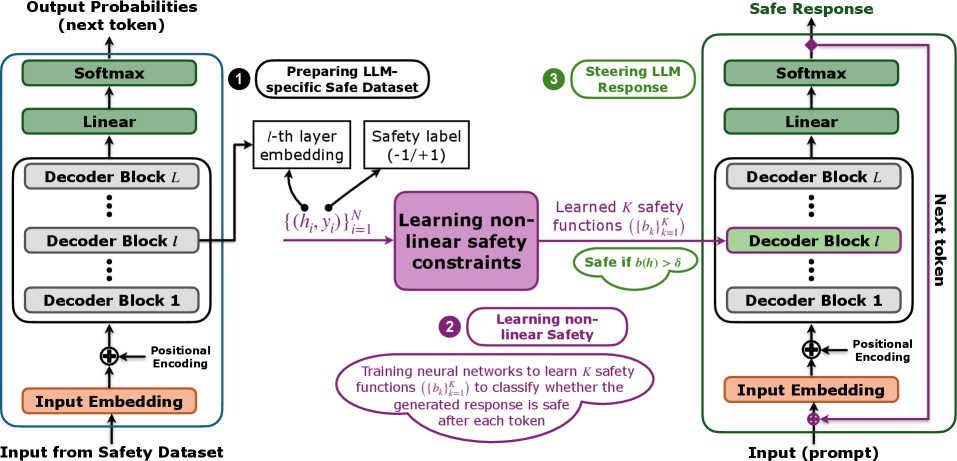
核心思路:BarrierSteer的核心思路是将安全约束嵌入到LLM的潜在表示空间中,利用控制屏障函数(CBF)引导LLM的生成过程,使其始终保持在安全区域内。通过学习非线性安全约束,并将其转化为CBF,可以在推理过程中实时检测和防止不安全响应的产生。这种方法无需修改LLM的参数,可以保留其原始性能,同时提高安全性和效率。
技术框架:BarrierSteer框架主要包含以下几个模块:1) 安全约束学习模块:用于学习非线性安全约束,例如基于数据集或人工规则定义的安全边界。2) 控制屏障函数(CBF)构建模块:将学习到的安全约束转化为CBF,CBF定义了潜在空间中的安全区域。3) 导向机制:在LLM推理过程中,利用CBF实时检测响应轨迹是否安全,如果存在不安全风险,则通过导向机制调整LLM的输出,使其回到安全区域内。4) 约束合并模块:用于高效地合并多个安全约束,以满足更复杂的安全需求。
关键创新:BarrierSteer的关键创新在于将控制理论中的控制屏障函数(CBF)引入到LLM的安全控制中。与传统的安全方法相比,BarrierSteer可以在潜在空间中直接对LLM的生成过程进行干预,从而更有效地防止不安全响应的产生。此外,BarrierSteer无需修改LLM的参数,可以保留其原始性能,并且可以通过约束合并来满足更复杂的安全需求。
关键设计:BarrierSteer的关键设计包括:1) 安全约束的表示形式:使用非线性函数来表示安全约束,以适应复杂的安全场景。2) CBF的构建方法:根据安全约束的性质,选择合适的CBF形式,例如零水平集或超梯度方法。3) 导向机制的设计:设计高效的导向算法,例如基于梯度下降或优化方法,以确保LLM的输出能够快速回到安全区域内。4) 约束合并策略:采用高效的约束合并算法,例如基于凸优化的方法,以减少计算复杂度。
🖼️ 关键图片
📊 实验亮点
实验结果表明,BarrierSteer在多个模型和数据集上均取得了显著的性能提升。例如,在对抗攻击实验中,BarrierSteer将对抗成功率降低了XX%,显著优于现有的防御方法。在不安全内容生成实验中,BarrierSteer减少了XX%的不安全生成,同时保持了LLM的原始性能。这些结果表明,BarrierSteer是一种有效、可靠的LLM安全机制。
🎯 应用场景
BarrierSteer具有广泛的应用前景,例如在金融、医疗、法律等高风险领域,可以用于防止LLM生成不准确、误导性或有害的信息。此外,BarrierSteer还可以应用于智能客服、聊天机器人等场景,提高用户体验,避免产生不当言论。该研究的未来影响在于,它为LLM的安全部署提供了一种新的思路,有望推动LLM在更多领域的应用。
📄 摘要(原文)
Despite the state-of-the-art performance of large language models (LLMs) across diverse tasks, their susceptibility to adversarial attacks and unsafe content generation remains a major obstacle to deployment, particularly in high-stakes settings. Addressing this challenge requires safety mechanisms that are both practically effective and supported by rigorous theory. We introduce BarrierSteer, a novel framework that formalizes response safety by embedding learned non-linear safety constraints directly into the model's latent representation space. BarrierSteer employs a steering mechanism based on Control Barrier Functions (CBFs) to efficiently detect and prevent unsafe response trajectories during inference with high precision. By enforcing multiple safety constraints through efficient constraint merging, without modifying the underlying LLM parameters, BarrierSteer preserves the model's original capabilities and performance. We provide theoretical results establishing that applying CBFs in latent space offers a principled and computationally efficient approach to enforcing safety. Our experiments across multiple models and datasets show that BarrierSteer substantially reduces adversarial success rates, decreases unsafe generations, and outperforms existing methods.