On the Equivalence of Random Network Distillation, Deep Ensembles, and Bayesian Inference
作者: Moritz A. Zanger, Yijun Wu, Pascal R. Van der Vaart, Wendelin Böhmer, Matthijs T. J. Spaan
分类: cs.LG, cs.AI, math.PR, stat.ML
发布日期: 2026-02-23
备注: 8 pages, 1 Figure
💡 一句话要点
揭示随机网络蒸馏、深度集成和贝叶斯推断的等价性,用于高效不确定性量化。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 不确定性量化 随机网络蒸馏 深度集成 贝叶斯推断 神经正切核 后验采样 深度学习
📋 核心要点
- 深度学习模型的不确定性量化至关重要,但现有方法缺乏坚实的理论基础,限制了其可靠性和适用性。
- 论文通过神经正切核理论,证明了随机网络蒸馏(RND)与深度集成和贝叶斯推断在特定条件下的等价性。
- 研究结果表明,RND可以作为一种高效且具有理论依据的不确定性量化方法,并提出了基于RND的后验采样算法。
📝 摘要(中文)
不确定性量化是深度学习模型安全高效部署的关键,但许多计算上可行的方法缺乏严格的理论基础。随机网络蒸馏(RND)是一种轻量级技术,通过预测误差与固定的随机目标进行比较来衡量新颖性。尽管RND在经验上有效,但RND衡量什么不确定性以及其估计如何与其他方法(如贝叶斯推断或深度集成)相关仍然不清楚。本文通过在无限网络宽度的神经正切核框架内分析RND,建立了这些缺失的理论联系。我们的分析揭示了两个核心发现:(1)来自RND的不确定性信号——其平方自预测误差——等价于深度集成的预测方差。(2)通过构建特定的RND目标函数,我们表明RND误差分布可以镜像宽神经网络的贝叶斯推断的中心后验预测分布。基于这种等价性,我们还设计了一种后验抽样算法,该算法使用这种修改后的“贝叶斯RND”模型从精确的贝叶斯后验预测分布中生成独立同分布的样本。总的来说,我们的发现提供了一个统一的理论视角,将RND置于深度集成和贝叶斯推断的原则框架内,并为高效且具有理论基础的不确定性量化方法提供了新的途径。
🔬 方法详解
问题定义:现有深度学习模型的不确定性量化方法,如深度集成,计算成本高昂,而随机网络蒸馏(RND)虽然高效,但缺乏明确的理论解释,难以保证其量化结果的可靠性。因此,需要一种既高效又具有理论支撑的不确定性量化方法。
核心思路:论文的核心思路是通过理论分析,揭示RND与深度集成和贝叶斯推断之间的内在联系。具体而言,在无限网络宽度的神经正切核(NTK)框架下,证明RND的自预测误差与深度集成的预测方差等价,并可以通过特定的RND目标函数模拟贝叶斯后验预测分布。
技术框架:论文的技术框架主要包括以下几个部分:1. 在NTK框架下对RND进行理论分析;2. 证明RND的自预测误差与深度集成的预测方差的等价性;3. 构建特定的RND目标函数,使其误差分布逼近贝叶斯后验预测分布;4. 基于上述等价性,设计一种基于RND的后验采样算法。
关键创新:论文最重要的技术创新在于建立了RND与深度集成和贝叶斯推断之间的理论联系。以往的研究主要关注RND的经验性能,而本文首次从理论上解释了RND的工作原理,并将其置于更广泛的贝叶斯框架下。这种理论上的突破为RND的应用提供了更强的理论支撑。
关键设计:论文的关键设计包括:1. 使用神经正切核(NTK)理论进行分析,这使得可以在无限网络宽度的条件下对RND进行精确的数学建模;2. 通过构建特定的RND目标函数,使其能够模拟贝叶斯后验预测分布,从而实现基于RND的贝叶斯推断;3. 设计了一种基于RND的后验采样算法,该算法可以高效地生成来自贝叶斯后验预测分布的样本。
🖼️ 关键图片
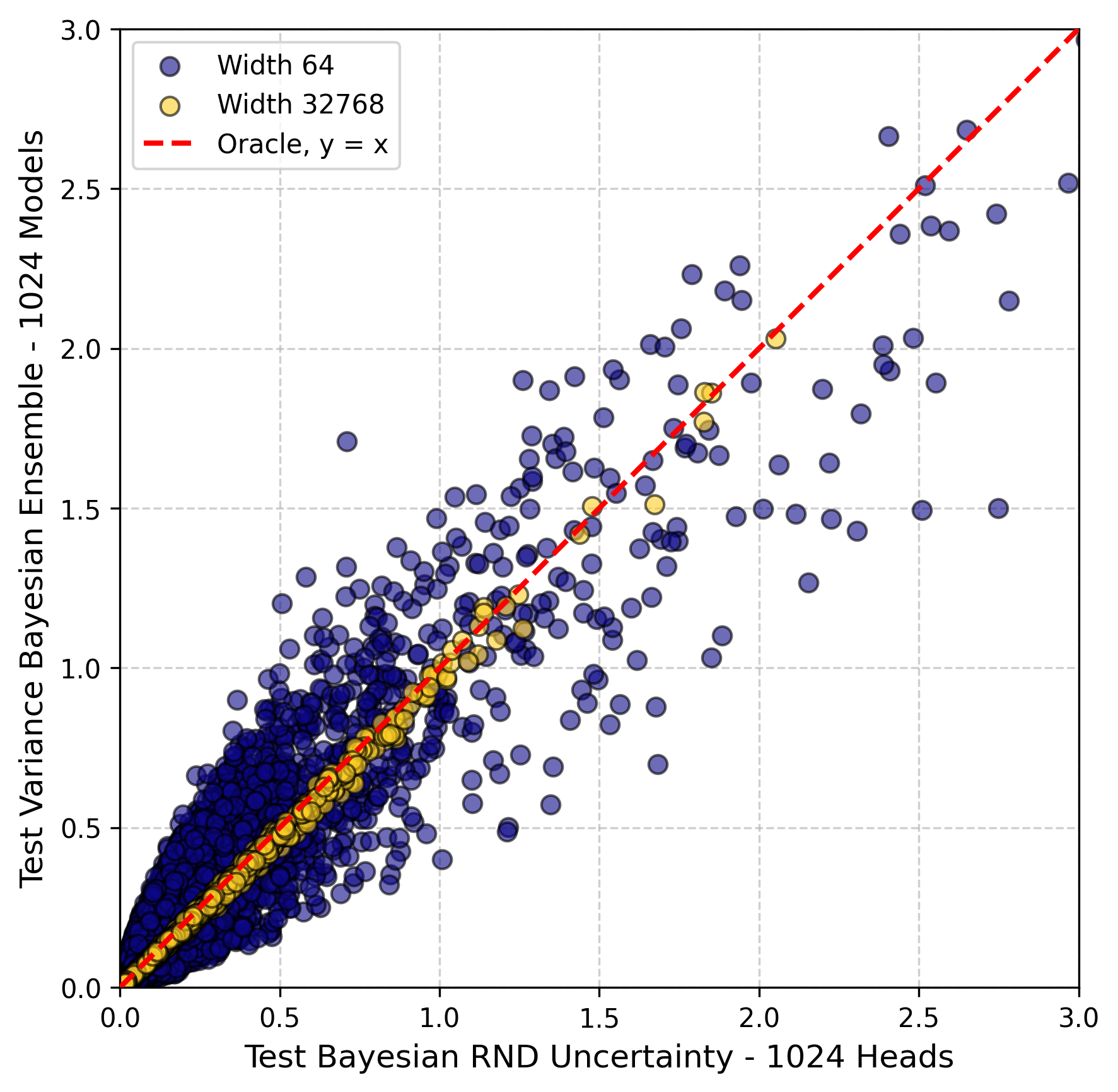
📊 实验亮点
论文通过理论分析证明了RND与深度集成和贝叶斯推断的等价性,并基于此提出了一种新的后验采样算法。该算法在理论上保证了可以生成来自精确贝叶斯后验预测分布的样本,为高效且具有理论基础的不确定性量化提供了新的途径。具体的性能数据和对比基线需要在实验部分进行验证,此处未知。
🎯 应用场景
该研究成果可应用于对安全性要求较高的深度学习应用场景,例如自动驾驶、医疗诊断等。通过使用RND进行不确定性量化,可以更准确地评估模型的预测风险,从而提高系统的可靠性和安全性。此外,该研究也为开发更高效、更具理论基础的不确定性量化方法提供了新的思路。
📄 摘要(原文)
Uncertainty quantification is central to safe and efficient deployments of deep learning models, yet many computationally practical methods lack lacking rigorous theoretical motivation. Random network distillation (RND) is a lightweight technique that measures novelty via prediction errors against a fixed random target. While empirically effective, it has remained unclear what uncertainties RND measures and how its estimates relate to other approaches, e.g. Bayesian inference or deep ensembles. This paper establishes these missing theoretical connections by analyzing RND within the neural tangent kernel framework in the limit of infinite network width. Our analysis reveals two central findings in this limit: (1) The uncertainty signal from RND -- its squared self-predictive error -- is equivalent to the predictive variance of a deep ensemble. (2) By constructing a specific RND target function, we show that the RND error distribution can be made to mirror the centered posterior predictive distribution of Bayesian inference with wide neural networks. Based on this equivalence, we moreover devise a posterior sampling algorithm that generates i.i.d. samples from an exact Bayesian posterior predictive distribution using this modified \textit{Bayesian RND} model. Collectively, our findings provide a unified theoretical perspective that places RND within the principled frameworks of deep ensembles and Bayesian inference, and offer new avenues for efficient yet theoretically grounded uncertainty quantification methods.