Sparse Masked Attention Policies for Reliable Generalization
作者: Caroline Horsch, Laurens Engwegen, Max Weltevrede, Matthijs T. J. Spaan, Wendelin Böhmer
分类: cs.LG
发布日期: 2026-02-23
💡 一句话要点
提出稀疏掩码注意力策略,提升强化学习策略的泛化可靠性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 泛化能力 注意力机制 掩码学习 策略优化
📋 核心要点
- 现有强化学习抽象方法泛化能力不足,因为信息提取函数在新状态下的泛化能力未知。
- 论文提出一种基于学习掩码的注意力策略,通过移除不必要信息来提升泛化能力。
- 实验表明,该方法在Procgen基准测试中,显著提升了策略对未见任务的泛化性能。
📝 摘要(中文)
在强化学习中,抽象方法通过移除观测中不必要的信息来学习能够更好地泛化到未见任务的策略。然而,这些方法通常忽略了一个关键弱点:提取降维信息表示的函数在未见观测中的泛化能力是未知的。本文通过提出一种信息移除方法来解决这个问题,该方法能够更可靠地泛化到新的状态。我们通过使用一个学习到的掩码函数来实现这一点,该函数作用于基于注意力的策略网络中的注意力权重并与之集成。我们证明,与标准PPO和掩码方法相比,我们的方法显著提高了策略在Procgen基准测试中对未见任务的泛化能力。
🔬 方法详解
问题定义:强化学习中的策略泛化问题,尤其是在面对未见过的任务时。现有的抽象方法依赖于信息提取函数,但这些函数在新状态下的泛化能力无法保证,导致策略在新任务上的表现不佳。
核心思路:通过学习一个掩码函数,作用于注意力机制的权重,从而有选择性地移除不必要的信息。这种方法将信息移除过程集成到策略网络中,使得策略能够更好地适应新的状态和任务。核心在于学习到的掩码能够动态地决定哪些信息是重要的,哪些是可以忽略的,从而提高泛化能力。
技术框架:该方法的核心在于一个基于注意力的策略网络,其中注意力权重被一个学习到的掩码函数所修改。整体流程包括:1) 输入观测;2) 通过注意力机制计算注意力权重;3) 使用学习到的掩码函数对注意力权重进行掩码;4) 基于掩码后的注意力权重生成策略。整个网络使用强化学习算法(如PPO)进行端到端训练。
关键创新:将信息移除过程与注意力机制集成,并使用学习到的掩码函数动态地选择需要移除的信息。与传统的静态信息移除方法相比,该方法能够更好地适应不同的状态和任务,从而提高泛化能力。此外,将掩码函数与注意力权重直接结合,使得信息移除过程更加高效和可解释。
关键设计:掩码函数的设计是关键。具体实现细节未知,但可以推测可能使用了神经网络来学习掩码,并可能使用了某种正则化方法来鼓励掩码的稀疏性,从而选择性地移除信息。损失函数除了标准的PPO损失外,可能还包含一个与掩码相关的正则化项,以控制信息移除的程度。
🖼️ 关键图片

📊 实验亮点
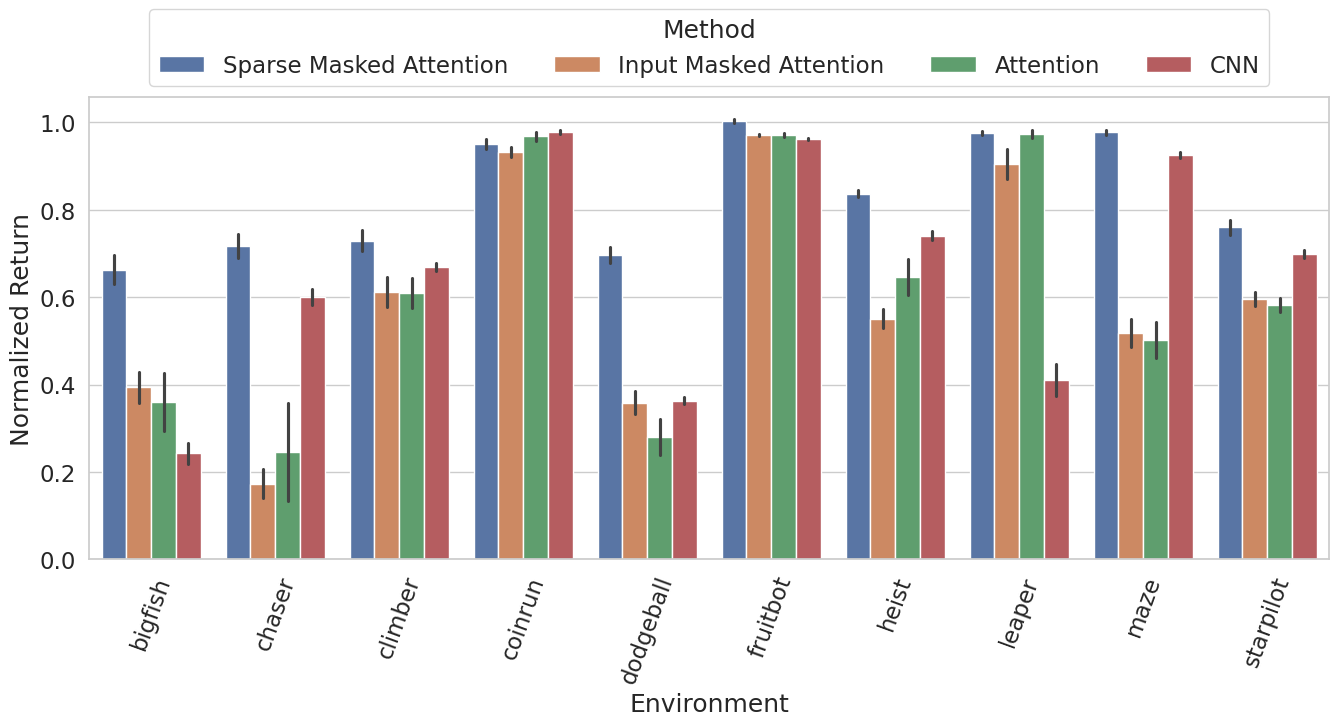
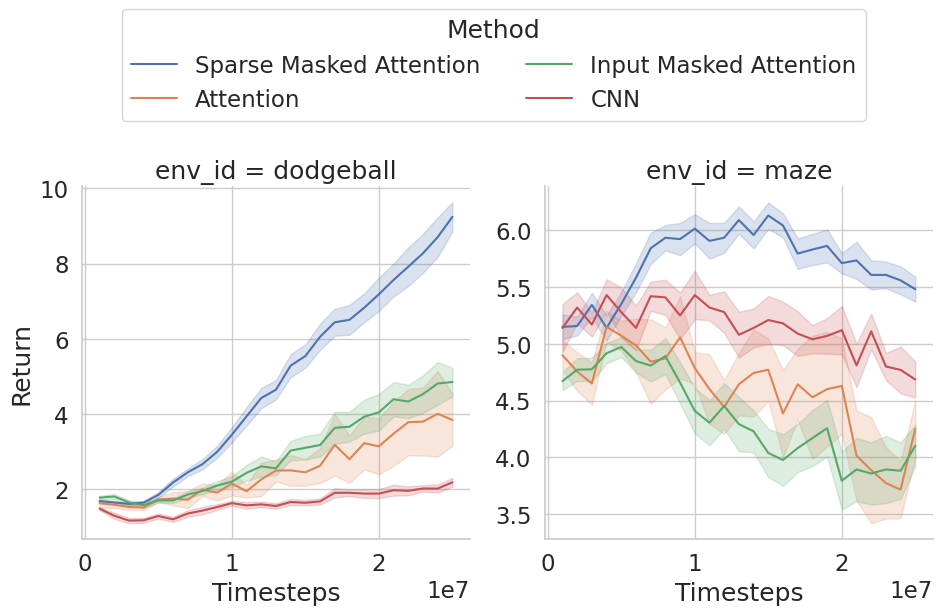
实验结果表明,该方法在Procgen基准测试中显著提高了策略对未见任务的泛化能力。与标准PPO和传统的掩码方法相比,该方法在多个游戏环境中都取得了更好的性能,证明了其有效性和优越性。具体的性能提升数据未知,但摘要中明确指出是“显著提高”。
🎯 应用场景
该研究成果可应用于机器人导航、游戏AI、自动驾驶等领域,尤其是在环境复杂多变、任务需要快速适应的场景下。通过提升策略的泛化能力,可以减少对大量训练数据的依赖,降低部署成本,并提高系统的鲁棒性和可靠性。未来,该方法有望扩展到更复杂的强化学习任务中,例如多智能体协作、元学习等。
📄 摘要(原文)
In reinforcement learning, abstraction methods that remove unnecessary information from the observation are commonly used to learn policies which generalize better to unseen tasks. However, these methods often overlook a crucial weakness: the function which extracts the reduced-information representation has unknown generalization ability in unseen observations. In this paper, we address this problem by presenting an information removal method which more reliably generalizes to new states. We accomplish this by using a learned masking function which operates on, and is integrated with, the attention weights within an attention-based policy network. We demonstrate that our method significantly improves policy generalization to unseen tasks in the Procgen benchmark compared to standard PPO and masking approaches.