A Replicate-and-Quantize Strategy for Plug-and-Play Load Balancing of Sparse Mixture-of-Experts LLMs
作者: Zijie Liu, Jie Peng, Jinhao Duan, Zirui Liu, Kaixiong Zhou, Mingfu Liang, Luke Simon, Xi Liu, Zhaozhuo Xu, Tianlong Chen
分类: cs.LG
发布日期: 2026-02-23
💡 一句话要点
提出Replicate-and-Quantize框架,解决SMoE模型推理时负载不均衡问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 稀疏混合专家模型 负载均衡 推理优化 模型量化 动态调整
📋 核心要点
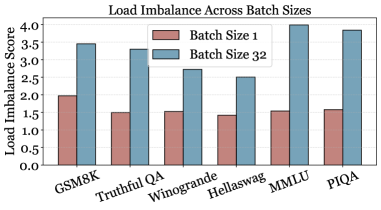
- SMoE模型推理时存在严重的负载不均衡问题,导致计算资源利用率低,现有方法主要集中在训练阶段,忽略了推理阶段的优化。
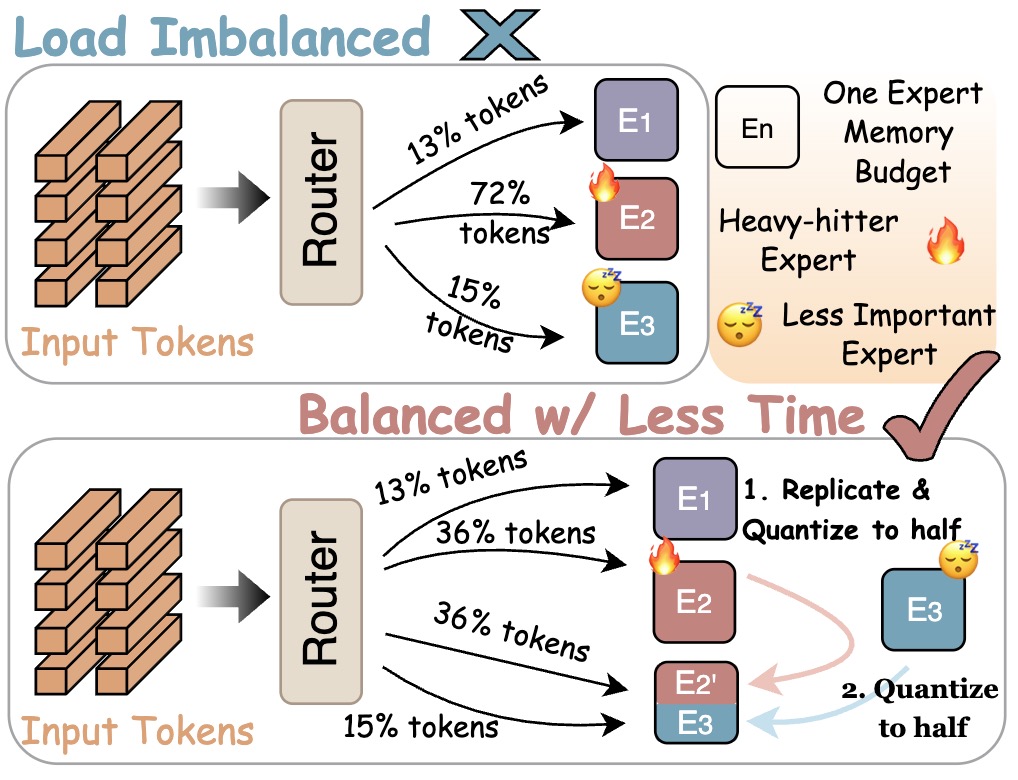
- 论文提出Replicate-and-Quantize (R&Q) 框架,通过复制重负载专家并量化不重要专家,动态平衡推理时的负载。
- 实验表明,R&Q框架能有效降低负载不均衡,最高可达1.4倍,同时保持精度在+/-0.6%以内,提升推理效率。
📝 摘要(中文)
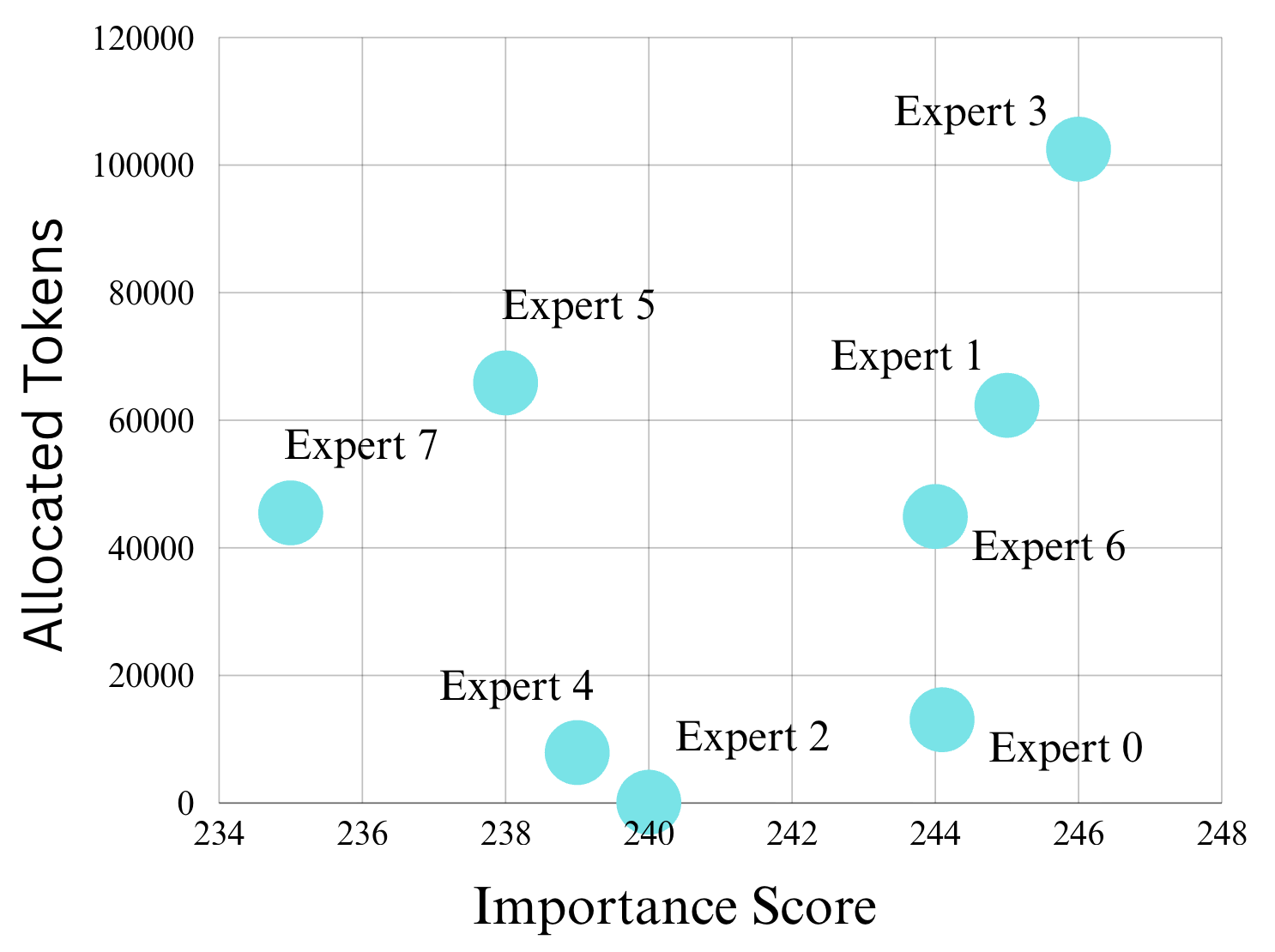
稀疏混合专家模型(SMoE)越来越多地被用于高效扩展大型语言模型,在固定的计算预算下提供强大的准确性。然而,SMoE模型通常存在严重的专家负载不均衡问题,即一小部分专家接收了大部分token,而其他专家则未被充分利用。以往的工作主要集中在训练时的解决方案,如路由正则化或辅助损失,而对推理时的行为(对部署至关重要)的探索较少。我们对推理期间的专家路由进行了系统分析,并发现了三个结论:(i)负载不均衡持续存在,并且随着批量大小的增加而恶化;(ii)选择频率不能可靠地反映专家的重要性;(iii)可以使用小的校准集来估计整体专家工作负载和重要性。这些见解促使我们设计了推理时机制,可以在不重新训练或修改路由器的情况下重新平衡工作负载。我们提出了Replicate-and-Quantize(R&Q),这是一个无需训练且近乎无损的动态工作负载重新平衡框架。在每一层中,重负载专家被复制以增加并行容量,而不太重要的专家和副本被量化以保持在原始内存预算内。我们还引入了负载不均衡分数(LIS),通过比较重负载与平均分配基线来衡量路由偏差。在代表性的SMoE模型和基准测试上的实验表明,不平衡减少高达1.4倍,精度保持在+/-0.6%以内,从而实现更可预测和高效的推理。
🔬 方法详解
问题定义:论文旨在解决稀疏混合专家模型(SMoE)在推理阶段存在的负载不均衡问题。现有方法主要集中在训练阶段通过正则化或辅助损失来缓解负载不均衡,但这些方法无法完全消除推理时的不均衡现象,并且缺乏对推理阶段专家行为的细致分析。推理时的负载不均衡会导致部分专家过载,而其他专家利用率不足,降低整体推理效率和资源利用率。
核心思路:论文的核心思路是在推理阶段动态地重新平衡专家负载,而无需重新训练模型或修改路由机制。通过分析专家路由行为,发现可以通过复制负载重的专家来增加并行处理能力,同时量化不重要的专家以控制内存开销。这种方法能够在不显著影响模型精度的前提下,更均匀地分配计算资源。
技术框架:Replicate-and-Quantize (R&Q) 框架包含以下主要阶段:1) 专家负载分析:使用小的校准集估计每个专家的工作负载和重要性。2) 负载不均衡评分 (LIS) 计算:通过比较重负载专家的负载与平均分配基线来衡量路由偏差。3) 专家复制:复制负载重的专家,增加并行处理能力。4) 专家量化:量化不重要的专家和复制的专家,以保持整体内存预算不变。
关键创新:R&Q框架的关键创新在于其在推理阶段动态调整专家负载的能力,而无需重新训练模型。通过复制和量化操作,实现了在内存限制下对专家负载的重新分配。此外,提出的负载不均衡评分 (LIS) 提供了一种量化负载不均衡程度的指标,为动态调整提供了依据。
关键设计:R&Q框架的关键设计包括:1) 复制策略:根据专家的负载和重要性,确定需要复制的专家数量。2) 量化策略:选择合适的量化方法(如INT8量化)和量化对象(不重要的专家和复制的专家),以在精度和内存之间取得平衡。3) 负载不均衡评分 (LIS):LIS的计算公式需要仔细设计,以准确反映负载不均衡的程度。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Replicate-and-Quantize (R&Q) 框架能够有效降低SMoE模型的负载不均衡程度,最高可达1.4倍。同时,该方法对模型精度的影响很小,精度损失控制在+/-0.6%以内。这些结果表明,R&Q框架是一种有效的推理时优化方法,可以在不显著降低模型精度的前提下,显著提高推理效率。
🎯 应用场景
该研究成果可应用于各种基于SMoE的大型语言模型部署场景,尤其是在资源受限的环境中,例如边缘设备或移动设备。通过动态平衡专家负载,可以提高推理效率,降低延迟,并提升用户体验。此外,该方法还可以用于优化模型压缩和加速,从而进一步降低部署成本。
📄 摘要(原文)
Sparse Mixture-of-Experts (SMoE) architectures are increasingly used to scale large language models efficiently, delivering strong accuracy under fixed compute budgets. However, SMoE models often suffer from severe load imbalance across experts, where a small subset of experts receives most tokens while others are underutilized. Prior work has focused mainly on training-time solutions such as routing regularization or auxiliary losses, leaving inference-time behavior, which is critical for deployment, less explored. We present a systematic analysis of expert routing during inference and identify three findings: (i) load imbalance persists and worsens with larger batch sizes, (ii) selection frequency does not reliably reflect expert importance, and (iii) overall expert workload and importance can be estimated using a small calibration set. These insights motivate inference-time mechanisms that rebalance workloads without retraining or router modification. We propose Replicate-and-Quantize (R&Q), a training-free and near-lossless framework for dynamic workload rebalancing. In each layer, heavy-hitter experts are replicated to increase parallel capacity, while less critical experts and replicas are quantized to remain within the original memory budget. We also introduce a Load-Imbalance Score (LIS) to measure routing skew by comparing heavy-hitter load to an equal allocation baseline. Experiments across representative SMoE models and benchmarks show up to 1.4x reduction in imbalance with accuracy maintained within +/-0.6%, enabling more predictable and efficient inference.