Rethinking LoRA for Privacy-Preserving Federated Learning in Large Models
作者: Jin Liu, Yinbin Miao, Ning Xi, Junkang Liu
分类: cs.LG, cs.AI
发布日期: 2026-02-23
💡 一句话要点
提出LA-LoRA,解决差分隐私联邦学习中LoRA微调大模型的性能下降问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 差分隐私 低秩适应 参数高效微调 大型模型 梯度解耦 模型鲁棒性
📋 核心要点
- 现有方法在差分隐私联邦学习中微调大模型时,直接应用LoRA会导致性能显著下降,尤其是在大型视觉模型上。
- LA-LoRA通过解耦梯度交互和对齐客户端更新方向,增强了模型在严格隐私约束下的鲁棒性,从而提升性能。
- 实验结果表明,LA-LoRA在Swin Transformer和RoBERTa模型上取得了SOTA性能,验证了其在LVM和LLM上的有效性。
📝 摘要(中文)
在差分隐私联邦学习(DPFL)下微调大型视觉模型(LVM)和大型语言模型(LLM)受到隐私-效用权衡的限制。低秩适应(LoRA)是一种参数高效微调(PEFT)方法,通过引入两个可训练的低秩矩阵并冻结预训练权重来降低计算和通信成本。然而,直接在DPFL设置中应用LoRA会导致性能下降,尤其是在LVM中。分析揭示了三个先前未被充分探索的挑战:(1)由两个非对称低秩矩阵的同时更新引起的梯度耦合,(2)差分隐私下的复合噪声放大,以及(3)参数空间中全局聚合模型的锐度。为了解决这些问题,我们提出LA-LoRA( extbf{L}ocal extbf{A}lternating extbf{LoRA}),一种新颖的方法,它解耦梯度交互并对齐客户端之间的更新方向,以增强在严格隐私约束下的鲁棒性。理论上,LA-LoRA加强了噪声联邦环境中的收敛保证。大量实验表明,LA-LoRA在Swin Transformer和RoBERTa模型上实现了最先进(SOTA)的性能,展示了对DP噪声的鲁棒性以及在LVM和LLM中的广泛适用性。例如,在严格的隐私预算($ε= 1$)下,在Tiny-ImageNet数据集上微调Swin-B模型时,LA-LoRA的测试精度比最佳基线RoLoRA高出16.83%。代码已开源。
🔬 方法详解
问题定义:论文旨在解决在差分隐私联邦学习(DPFL)场景下,使用LoRA微调大型模型时出现的性能下降问题。现有方法直接应用LoRA,由于梯度耦合、噪声放大和模型锐度等问题,导致模型精度显著降低,尤其是在大型视觉模型上。
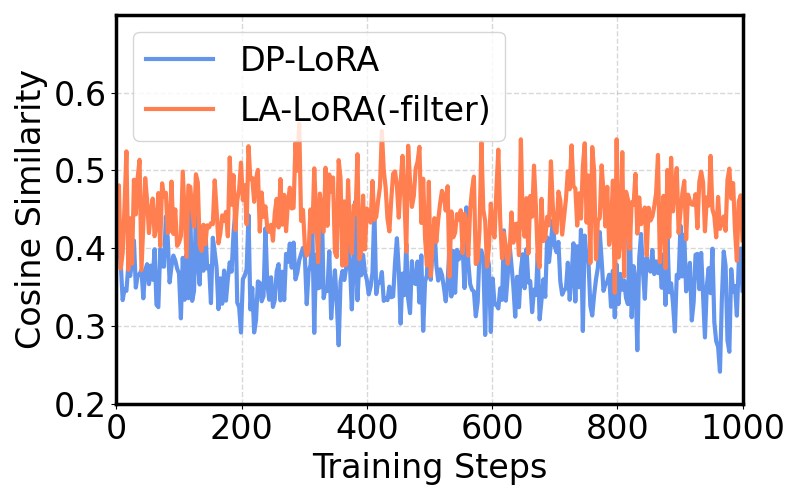
核心思路:LA-LoRA的核心思路是通过解耦梯度交互和对齐客户端更新方向来提高模型在DPFL下的鲁棒性。具体来说,它采用局部交替更新策略,分别更新LoRA的两个低秩矩阵,从而避免梯度耦合。同时,通过某种机制(论文中未明确说明具体机制,但暗示是对齐更新方向),减少客户端之间的差异,降低噪声的影响。
技术框架:LA-LoRA的整体框架仍然是联邦学习的框架,每个客户端在本地进行模型训练,然后将更新上传到服务器进行聚合。与传统LoRA不同的是,LA-LoRA在本地训练阶段采用了交替更新策略,并且可能包含一个对齐更新方向的模块(具体实现未知)。服务器端的聚合方式可能也需要进行调整以适应LA-LoRA的更新方式。
关键创新:LA-LoRA的关键创新在于其局部交替更新策略,以及对齐客户端更新方向的思想。交替更新解耦了梯度交互,降低了噪声的影响。对齐更新方向则减少了客户端之间的差异,使得全局模型更加稳定。
关键设计:论文中没有详细描述关键参数设置、损失函数和网络结构等技术细节。但是,可以推测,交替更新的频率、对齐更新方向的具体算法、以及服务器端的聚合策略都是需要仔细设计的关键因素。损失函数应该仍然是标准的分类或回归损失函数,网络结构则取决于具体的任务和模型。
🖼️ 关键图片
📊 实验亮点
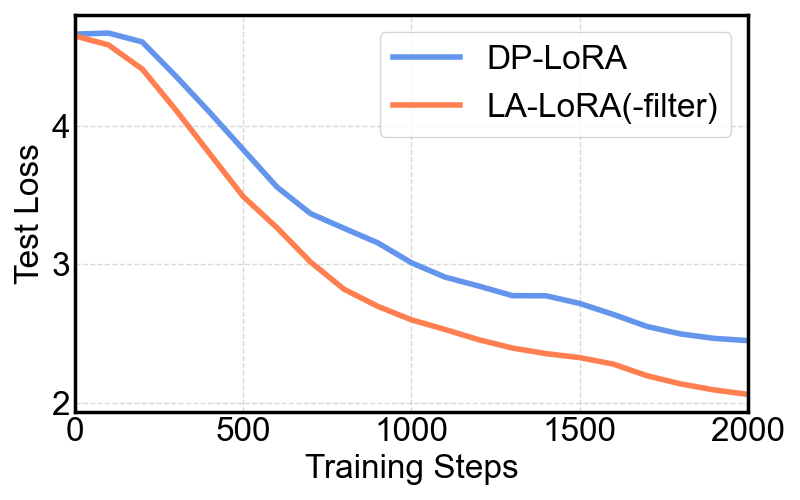
LA-LoRA在Swin Transformer和RoBERTa模型上取得了显著的性能提升。例如,在Tiny-ImageNet数据集上微调Swin-B模型,当隐私预算ε=1时,LA-LoRA的测试精度比最佳基线RoLoRA高出16.83%。这表明LA-LoRA在严格的隐私约束下,能够有效提升模型的性能。
🎯 应用场景
LA-LoRA在保护用户隐私的前提下,能够有效微调大型模型,适用于医疗影像分析、金融风控、自动驾驶等对数据隐私和模型性能有较高要求的领域。该方法有助于推动联邦学习在实际场景中的应用,并促进人工智能技术的发展。
📄 摘要(原文)
Fine-tuning large vision models (LVMs) and large language models (LLMs) under differentially private federated learning (DPFL) is hindered by a fundamental privacy-utility trade-off. Low-Rank Adaptation (LoRA), a promising parameter-efficient fine-tuning (PEFT) method, reduces computational and communication costs by introducing two trainable low-rank matrices while freezing pre-trained weights. However, directly applying LoRA in DPFL settings leads to performance degradation, especially in LVMs. Our analysis reveals three previously underexplored challenges: (1) gradient coupling caused by the simultaneous update of two asymmetric low-rank matrices, (2) compounded noise amplification under differential privacy, and (3) sharpness of the global aggregated model in the parameter space. To address these issues, we propose LA-LoRA (\textbf{L}ocal \textbf{A}lternating \textbf{LoRA}), a novel approach that decouples gradient interactions and aligns update directions across clients to enhance robustness under stringent privacy constraints. Theoretically, LA-LoRA strengthens convergence guarantees in noisy federated environments. Extensive experiments demonstrate that LA-LoRA achieves state-of-the-art (SOTA) performance on Swin Transformer and RoBERTa models, showcasing robustness to DP noise and broad applicability across both LVMs and LLMs. For example, when fine-tuning the Swin-B model on the Tiny-ImageNet dataset under a strict privacy budget ($ε= 1$), LA-LoRA outperforms the best baseline, RoLoRA, by 16.83\% in test accuracy. Code is provided in \repolink.