Uncertainty-Aware Rank-One MIMO Q Network Framework for Accelerated Offline Reinforcement Learning
作者: Thanh Nguyen, Tung Luu, Tri Ton, Sungwoong Kim, Chang D. Yoo
分类: cs.LG, cs.RO
发布日期: 2026-02-23
备注: 10 pages, 4 Figures, IEEE Access
期刊: IEEE Access, vol. 12, pp. 100972-100982, 2024
DOI: 10.1109/ACCESS.2024.3404474
💡 一句话要点
提出不确定性感知的Rank-One MIMO Q网络,加速离线强化学习并提升性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 不确定性量化 Q网络 MIMO网络 Rank-One分解 分布外数据 推断误差
📋 核心要点
- 离线强化学习面临分布外数据带来的推断误差,现有方法在利用OOD数据时存在保守、不精确和计算开销大的问题。
- 提出不确定性感知的Rank-One MIMO Q网络框架,通过量化数据不确定性并融入训练损失,最大化Q函数的下置信界。
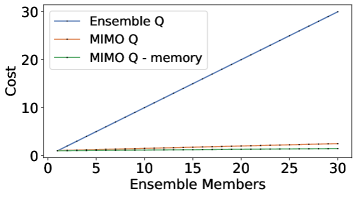
- Rank-One MIMO架构以接近单网络的成本实现与集成网络相当的不确定性量化能力,在D4RL基准测试中达到SOTA性能。
📝 摘要(中文)
离线强化学习因其安全性和易扩展性而备受关注。然而,训练面临着由分布外(OOD)数据引起的推断误差。现有方法试图通过惩罚OOD Q值或对学习策略和行为策略施加相似性约束来解决此问题。但是,这些方法通常过于保守地利用OOD数据,OOD数据特征描述不精确,且计算开销大。为了解决这些挑战,本文提出了一种不确定性感知的Rank-One多输入多输出(MIMO) Q网络框架。该框架旨在通过充分利用OOD数据的潜力来增强离线强化学习,同时确保学习过程的效率。具体来说,该框架量化数据不确定性并将其用于训练损失中,旨在训练一种策略,使其最大化相应Q函数的下置信界。此外,引入Rank-One MIMO架构来建模不确定性感知的Q函数,提供与网络集成相同的不确定性量化能力,但成本几乎与单个网络相当。因此,该框架在精度、速度和内存效率之间取得了和谐的平衡,最终提高了整体性能。在D4RL基准上的大量实验表明,该框架在保持计算效率的同时,达到了最先进的性能。通过结合不确定性量化的概念,我们的框架为缓解推断误差和提高离线RL的效率提供了一条有希望的途径。
🔬 方法详解
问题定义:离线强化学习中,由于训练数据与实际策略执行时遇到的状态分布存在差异,导致Q函数估计出现偏差,即外推误差。现有方法要么过于保守地避免使用分布外数据,要么无法准确量化分布外数据的不确定性,或者计算复杂度过高,难以实际应用。
核心思路:论文的核心思路是利用不确定性量化来指导Q函数的学习,避免过度依赖分布外数据,同时充分利用其包含的信息。通过最大化Q函数的下置信界,可以训练出更加鲁棒和可靠的策略。Rank-One MIMO架构的设计旨在以较低的计算成本实现有效的不确定性估计。
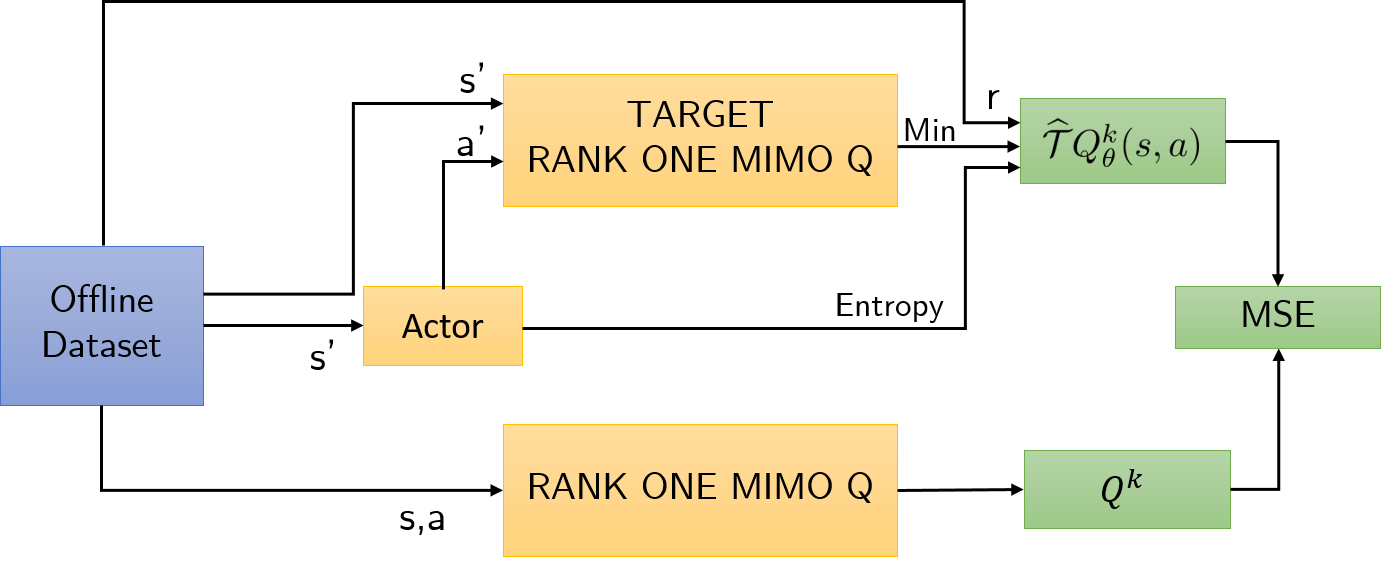
技术框架:该框架主要包含以下几个模块:1) 数据不确定性量化模块:用于估计每个状态-动作对的不确定性。2) Rank-One MIMO Q网络:用于建模不确定性感知的Q函数。3) 损失函数:结合了Q函数预测值和不确定性估计,旨在最大化Q函数的下置信界。训练过程通过最小化损失函数来更新Q网络参数。
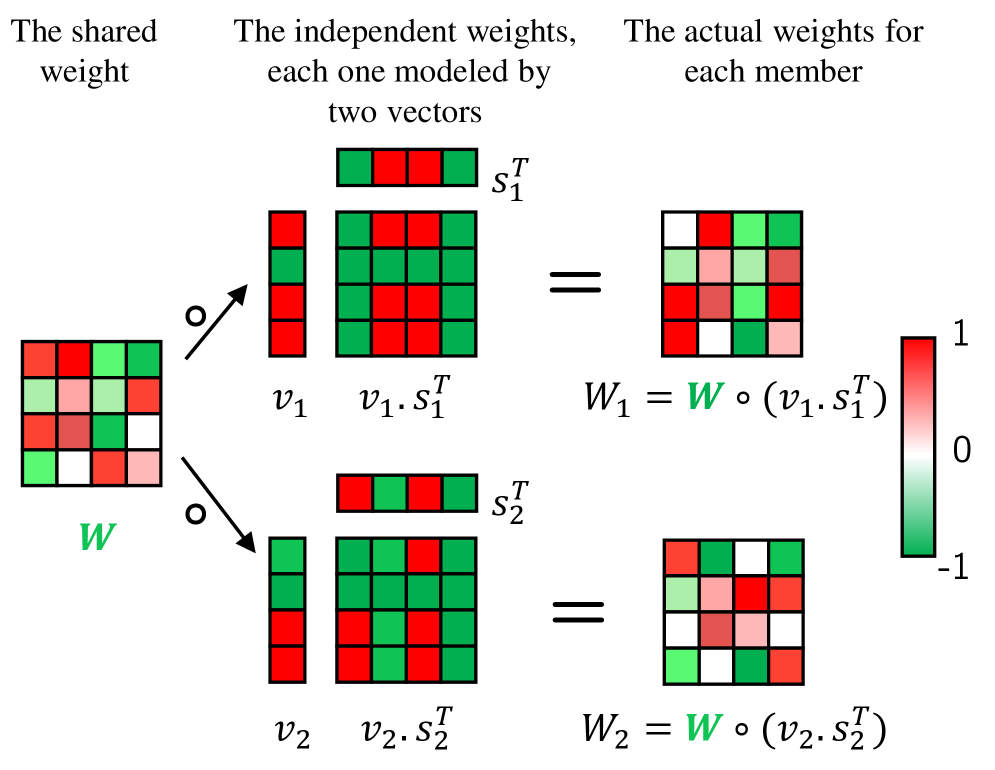
关键创新:最重要的技术创新点在于Rank-One MIMO架构在不确定性量化方面的效率。与传统的集成方法相比,Rank-One MIMO架构可以在几乎不增加计算成本的情况下,实现与集成方法相当的不确定性估计能力。这使得该框架能够在计算资源有限的情况下,有效地利用不确定性信息来提升离线强化学习的性能。
关键设计:Rank-One MIMO Q网络使用一个共享的特征提取器,然后通过多个独立的输出头来预测Q值和不确定性。损失函数设计为最大化Q值的下置信界,具体形式为:L = - (Q(s, a) - β * Uncertainty(s, a)),其中β是一个超参数,用于控制不确定性对Q值的影响。
🖼️ 关键图片
📊 实验亮点
在D4RL基准测试中,该框架在多个任务上取得了state-of-the-art的性能。与现有方法相比,该框架在保证计算效率的同时,显著提升了策略的性能。例如,在某些任务上,该框架的性能提升超过了10%。实验结果表明,该框架能够有效地利用不确定性信息来缓解外推误差,提升离线强化学习的性能。
🎯 应用场景
该研究成果可应用于各种需要离线强化学习的场景,例如机器人控制、自动驾驶、推荐系统和金融交易等。通过利用离线数据进行策略学习,可以避免在线探索带来的风险和成本,加速策略的部署和应用。该方法尤其适用于数据收集成本高昂或安全性要求严格的领域。
📄 摘要(原文)
Offline reinforcement learning (RL) has garnered significant interest due to its safe and easily scalable paradigm. However, training under this paradigm presents its own challenge: the extrapolation error stemming from out-of-distribution (OOD) data. Existing methodologies have endeavored to address this issue through means like penalizing OOD Q-values or imposing similarity constraints on the learned policy and the behavior policy. Nonetheless, these approaches are often beset by limitations such as being overly conservative in utilizing OOD data, imprecise OOD data characterization, and significant computational overhead. To address these challenges, this paper introduces an Uncertainty-Aware Rank-One Multi-Input Multi-Output (MIMO) Q Network framework. The framework aims to enhance Offline Reinforcement Learning by fully leveraging the potential of OOD data while still ensuring efficiency in the learning process. Specifically, the framework quantifies data uncertainty and harnesses it in the training losses, aiming to train a policy that maximizes the lower confidence bound of the corresponding Q-function. Furthermore, a Rank-One MIMO architecture is introduced to model the uncertainty-aware Q-function, \TP{offering the same ability for uncertainty quantification as an ensemble of networks but with a cost nearly equivalent to that of a single network}. Consequently, this framework strikes a harmonious balance between precision, speed, and memory efficiency, culminating in improved overall performance. Extensive experimentation on the D4RL benchmark demonstrates that the framework attains state-of-the-art performance while remaining computationally efficient. By incorporating the concept of uncertainty quantification, our framework offers a promising avenue to alleviate extrapolation errors and enhance the efficiency of offline RL.