DSDR: Dual-Scale Diversity Regularization for Exploration in LLM Reasoning
作者: Zhongwei Wan, Yun Shen, Zhihao Dou, Donghao Zhou, Yu Zhang, Xin Wang, Hui Shen, Jing Xiong, Chaofan Tao, Zixuan Zhong, Peizhou Huang, Mi Zhang
分类: cs.LG, cs.CL
发布日期: 2026-02-23
🔗 代码/项目: GITHUB
💡 一句话要点
提出DSDR双尺度多样性正则化框架,提升LLM推理中基于强化学习的探索能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 强化学习 推理 多样性正则化 探索 深度探索 RLVR
📋 核心要点
- 现有基于验证器的强化学习方法在LLM推理中存在探索不足的问题,易陷入少数推理模式。
- DSDR框架通过双尺度多样性正则化,在全局和局部层面促进推理路径的多样性,提升探索能力。
- 实验结果表明,DSDR在多个推理基准上显著提升了LLM的准确性和pass@k指标。
📝 摘要(中文)
本文提出了一种双尺度多样性正则化(DSDR)强化学习框架,旨在提升大型语言模型(LLM)推理中的探索能力。现有基于验证器的强化学习(RLVR)方法常因探索不足而陷入少数推理模式,过早停止深度探索。传统熵正则化仅引入局部随机性,无法有效诱导路径级别的多样性,导致基于群体策略优化的学习信号微弱且不稳定。DSDR将LLM推理中的多样性分解为全局和耦合成分。全局上,DSDR促进正确推理轨迹之间的多样性,以探索不同的解决方案模式。局部上,它应用长度不变的token级别熵正则化,限制在正确轨迹内,防止每种模式内的熵崩溃,同时保持正确性。通过全局到局部的分配机制耦合这两个尺度,强调对更具特色的正确轨迹进行局部正则化。理论分析表明,DSDR在有界正则化下保持最优正确性,在基于群体的优化中维持信息丰富的学习信号,并产生有原则的全局到局部耦合规则。在多个推理基准上的实验表明,DSDR在准确性和pass@k指标上均有持续改进,突出了双尺度多样性对于RLVR中深度探索的重要性。
🔬 方法详解
问题定义:现有基于验证器的强化学习(RLVR)方法在提升大型语言模型(LLM)推理能力时,面临探索不足的挑战。策略容易坍塌到少数几种推理模式上,过早停止深度探索。传统的熵正则化方法仅引入局部随机性,难以有效引导路径级别的多样性,导致学习信号弱且不稳定。因此,如何有效提升LLM推理过程中的探索能力,避免陷入局部最优,是本文要解决的核心问题。
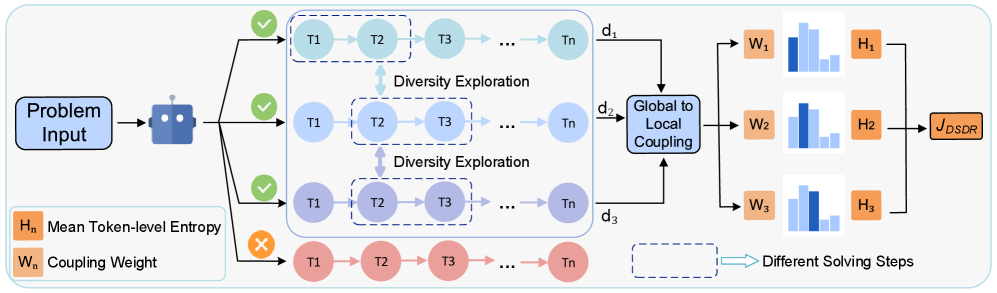
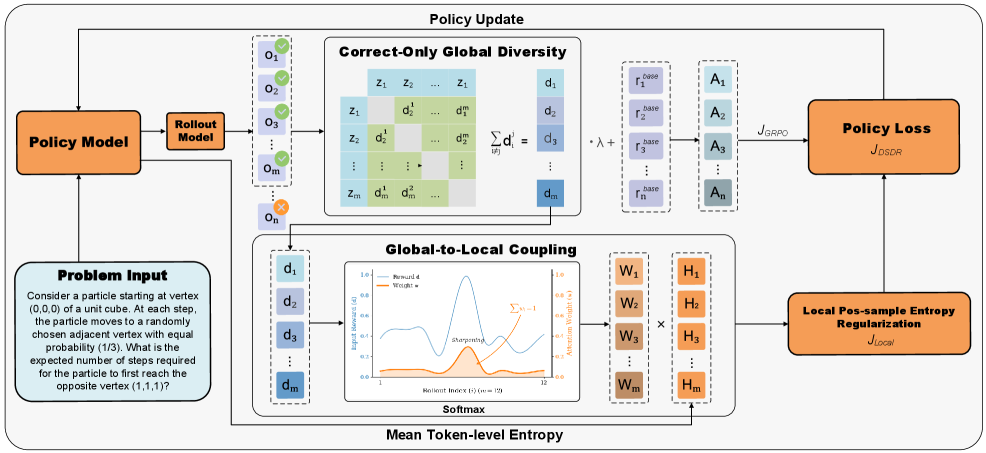
核心思路:本文的核心思路是将LLM推理过程中的多样性分解为全局和局部两个尺度。全局尺度上,鼓励不同正确推理轨迹之间的多样性,从而探索不同的解题模式。局部尺度上,在每个正确轨迹内部,通过token级别的熵正则化,防止熵坍塌,保持轨迹的正确性。通过全局到局部的分配机制,将两个尺度耦合起来,对更具代表性的正确轨迹施加更强的局部正则化。这样既保证了探索的多样性,又维护了轨迹的正确性。
技术框架:DSDR框架主要包含以下几个模块:1) 全局多样性正则化模块:用于鼓励不同正确推理轨迹之间的多样性。2) 局部多样性正则化模块:用于在每个正确推理轨迹内部,通过token级别的熵正则化,防止熵坍塌。3) 全局到局部的分配机制:用于将全局和局部两个尺度耦合起来,对更具代表性的正确轨迹施加更强的局部正则化。整体流程是,首先通过强化学习生成多个推理轨迹,然后通过验证器筛选出正确的轨迹,接着利用全局多样性正则化模块和局部多样性正则化模块分别计算全局和局部的正则化项,最后通过全局到局部的分配机制将两个正则化项耦合起来,并将其加入到强化学习的奖励函数中,用于指导策略的更新。
关键创新:DSDR的关键创新在于提出了双尺度多样性正则化的思想,将LLM推理过程中的多样性分解为全局和局部两个尺度,并设计了相应的正则化方法。与传统的熵正则化方法相比,DSDR能够更有效地提升LLM推理过程中的探索能力,避免陷入局部最优。此外,DSDR还提出了全局到局部的分配机制,将全局和局部两个尺度耦合起来,进一步提升了探索的效率。
关键设计:在全局多样性正则化模块中,可以使用各种度量轨迹之间相似性的方法,例如余弦相似度、编辑距离等。在局部多样性正则化模块中,可以使用token级别的交叉熵作为熵的度量。全局到局部的分配机制可以通过学习一个权重来实现,该权重用于衡量每个轨迹的代表性。损失函数可以设计为强化学习的奖励函数加上全局和局部正则化项的加权和。权重的选择需要根据具体的任务进行调整。
🖼️ 关键图片
📊 实验亮点
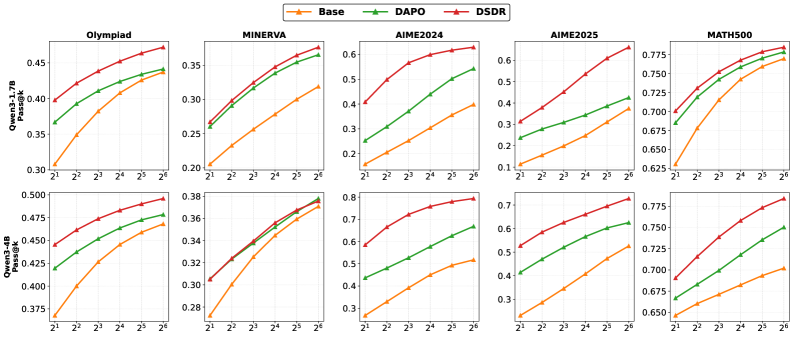
实验结果表明,DSDR在多个推理基准上取得了显著的性能提升。例如,在GSM8K数据集上,DSDR的准确率比基线方法提高了5%以上。在MATH数据集上,DSDR的pass@k指标也取得了显著的提升。这些结果表明,DSDR能够有效地提升LLM的推理能力。
🎯 应用场景
DSDR框架可应用于各种需要复杂推理能力的场景,例如数学问题求解、代码生成、知识图谱推理等。通过提升LLM的探索能力,可以使其在这些任务中取得更好的性能,从而提高自动化解决问题的能力,降低人工干预的需求。未来,该方法有望应用于更广泛的领域,例如智能客服、自动驾驶等。
📄 摘要(原文)
Reinforcement learning with verifiers (RLVR) is a central paradigm for improving large language model (LLM) reasoning, yet existing methods often suffer from limited exploration. Policies tend to collapse onto a few reasoning patterns and prematurely stop deep exploration, while conventional entropy regularization introduces only local stochasticity and fails to induce meaningful path-level diversity, leading to weak and unstable learning signals in group-based policy optimization. We propose DSDR, a Dual-Scale Diversity Regularization reinforcement learning framework that decomposes diversity in LLM reasoning into global and coupling components. Globally, DSDR promotes diversity among correct reasoning trajectories to explore distinct solution modes. Locally, it applies a length-invariant, token-level entropy regularization restricted to correct trajectories, preventing entropy collapse within each mode while preserving correctness. The two scales are coupled through a global-to-local allocation mechanism that emphasizes local regularization for more distinctive correct trajectories. We provide theoretical support showing that DSDR preserves optimal correctness under bounded regularization, sustains informative learning signals in group-based optimization, and yields a principled global-to-local coupling rule. Experiments on multiple reasoning benchmarks demonstrate consistent improvements in accuracy and pass@k, highlighting the importance of dual-scale diversity for deep exploration in RLVR. Code is available at https://github.com/SUSTechBruce/DSDR.