Addressing Instrument-Outcome Confounding in Mendelian Randomization through Representation Learning
作者: Shimeng Huang, Matthew Robinson, Francesco Locatello
分类: cs.LG
发布日期: 2026-02-23
💡 一句话要点
提出基于表征学习的孟德尔随机化方法,解决工具变量-结果混淆问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 孟德尔随机化 因果推断 表征学习 工具变量 混淆因素
📋 核心要点
- 孟德尔随机化在因果推断中受混淆因素影响,现有方法难以保证工具变量与混淆因素的独立性。
- 利用多环境数据,通过表征学习提取遗传工具变量中跨环境不变的潜在外生成分。
- 通过理论分析保证了潜在工具变量的可识别性,并在模拟和半合成实验中验证了方法的有效性。
📝 摘要(中文)
孟德尔随机化(MR)是一种重要的观察性流行病学研究方法,旨在估计因果效应时解决未观察到的混淆。然而,由于人口分层或选择性交配,核心假设——特别是工具变量和未观察到的混淆因素之间的独立性——经常被违反。利用日益增长的多环境数据可用性,我们提出了一个表征学习框架,该框架利用跨环境不变性来恢复遗传工具变量的潜在外生成分。我们为在各种混合机制下识别这些潜在工具变量提供了理论保证,并通过模拟和使用All of Us Research Hub数据的半合成实验证明了我们方法的有效性。
🔬 方法详解
问题定义:论文旨在解决孟德尔随机化(MR)中工具变量(genetic instruments)与结果(outcome)之间存在的混淆问题。传统的MR方法依赖于工具变量与未观察到的混淆因素之间相互独立的假设,但由于人口结构、选择性交配等因素,这一假设往往难以满足,导致因果推断结果产生偏差。
核心思路:论文的核心思路是利用表征学习,从多环境数据中提取遗传工具变量的潜在外生成分。这些外生成分在不同环境中保持不变,因此可以作为更可靠的工具变量,从而减少混淆因素的影响。通过学习跨环境不变的表征,可以更准确地估计因果效应。
技术框架:该方法主要包含以下几个阶段:1) 数据预处理:收集多环境下的基因数据和表型数据。2) 表征学习:使用深度学习模型(具体模型未知,原文未详细说明)学习遗传工具变量的表征,目标是提取跨环境不变的特征。3) 因果推断:使用学习到的潜在外生成分作为工具变量,进行孟德尔随机化分析,估计因果效应。4) 理论分析:提供理论保证,证明在特定条件下,该方法可以识别出潜在的工具变量。
关键创新:该方法最重要的创新点在于利用表征学习来解决MR中的工具变量混淆问题。与传统的MR方法相比,该方法不需要假设工具变量与混淆因素完全独立,而是通过学习跨环境不变的表征来提取更可靠的工具变量。这种方法可以更好地处理实际应用中常见的混淆情况。
关键设计:论文中关于表征学习模型的具体结构、损失函数以及参数设置等技术细节描述不足,属于未知信息。但可以推测,损失函数的设计可能包含鼓励表征跨环境不变性的正则项。具体的网络结构和参数设置需要根据具体的数据集和实验结果进行调整。
🖼️ 关键图片
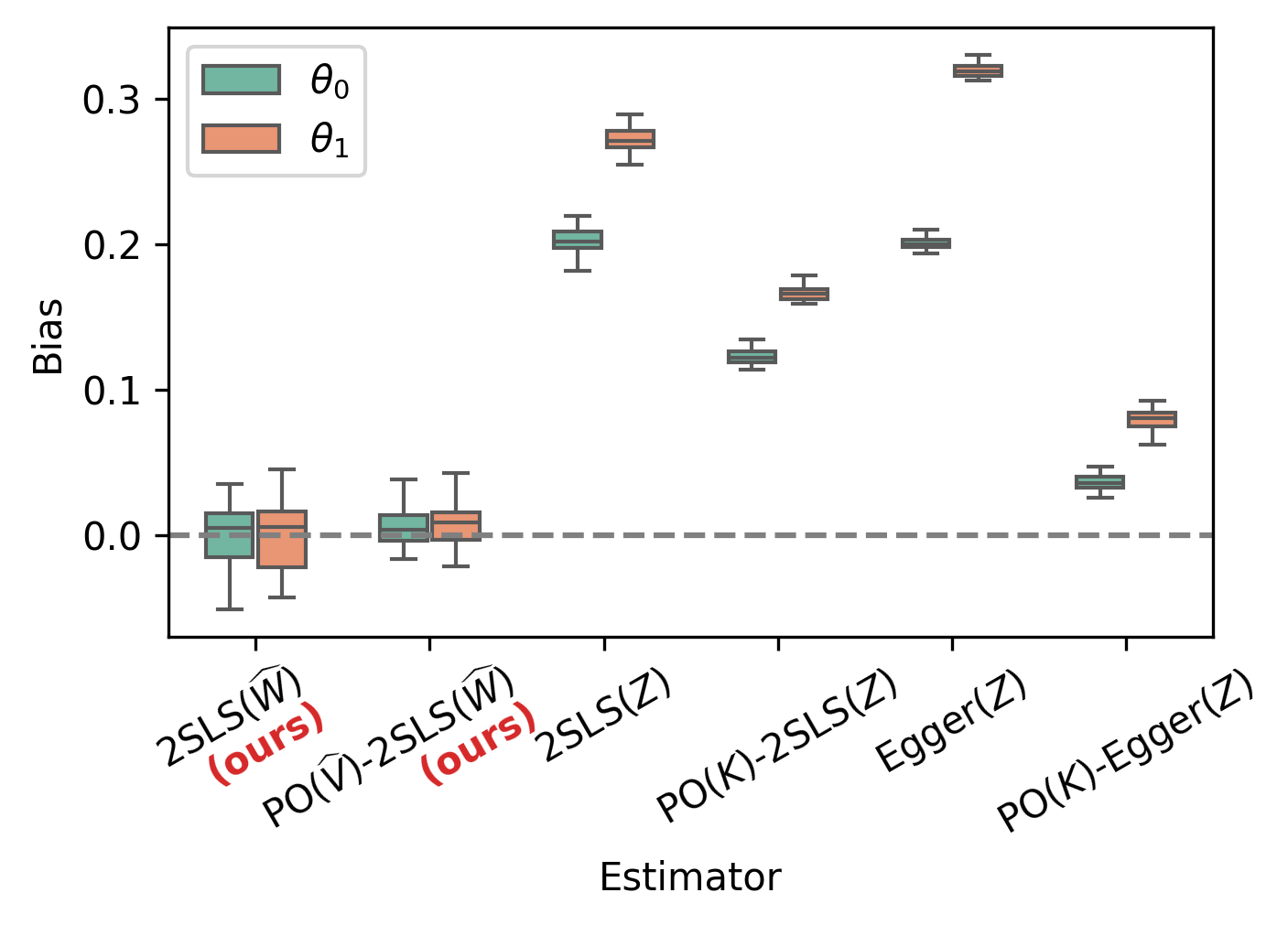
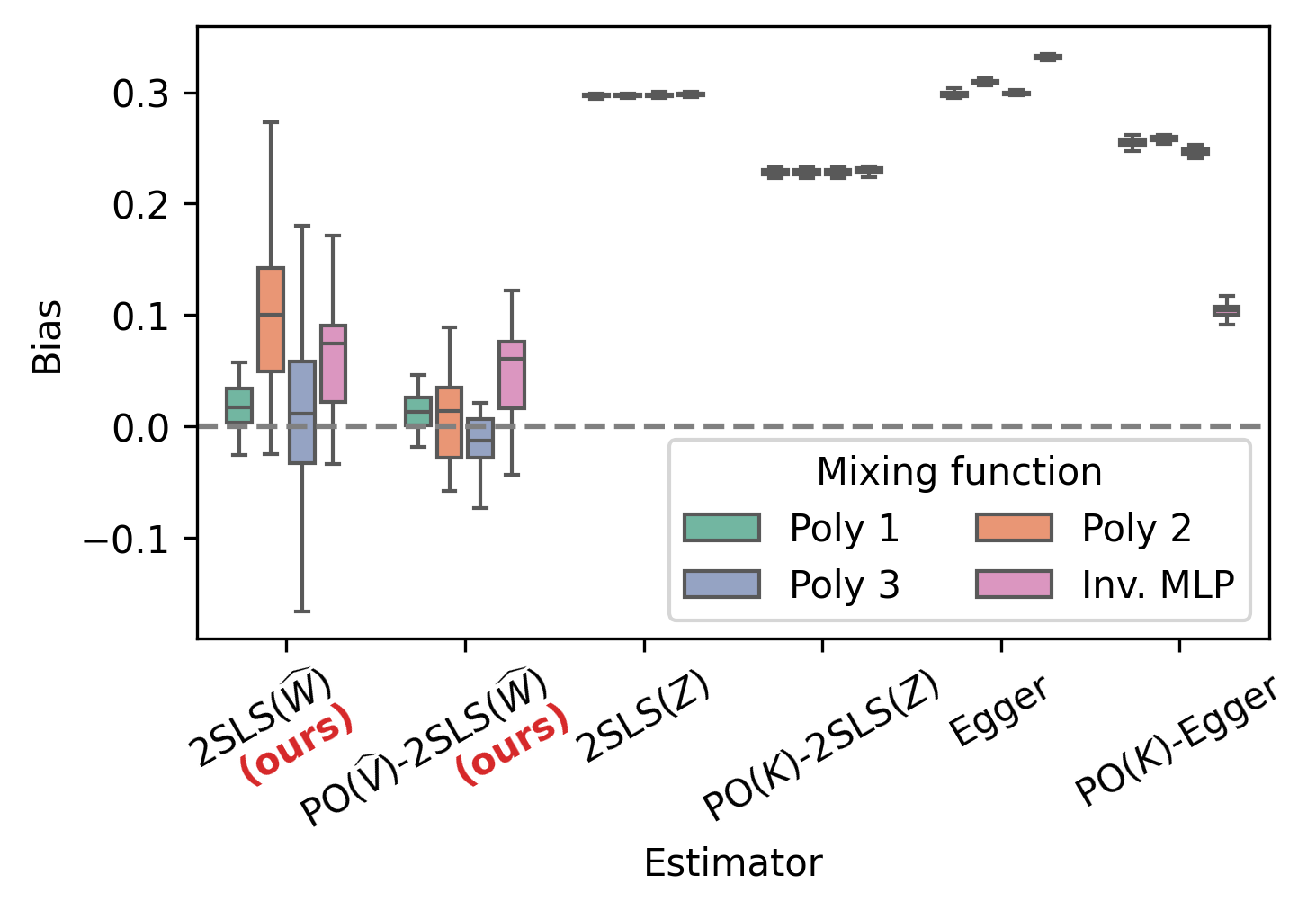
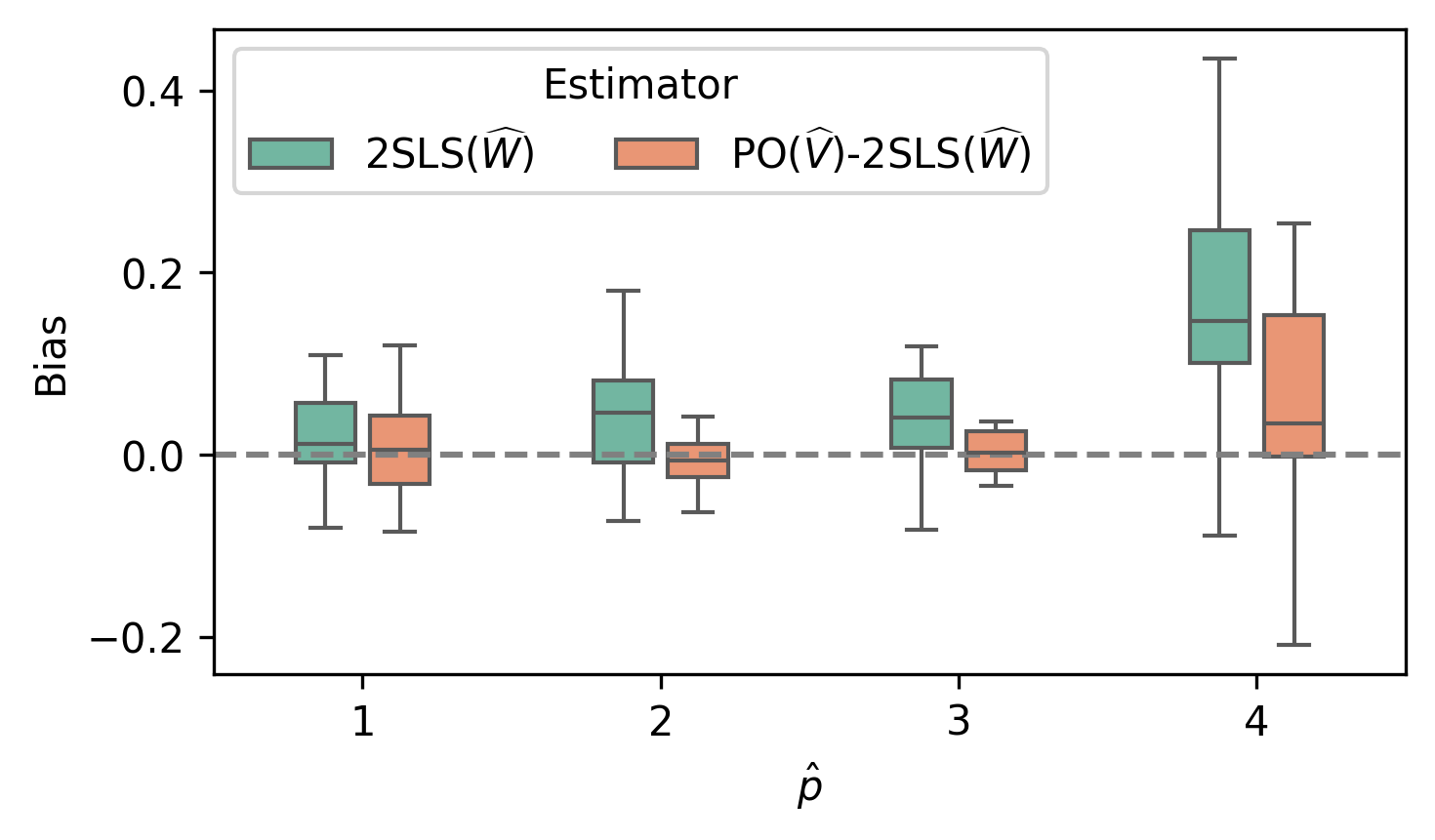
📊 实验亮点
论文通过模拟和半合成实验验证了该方法的有效性。在模拟实验中,该方法能够更准确地估计因果效应,并减少混淆因素的影响。在半合成实验中,使用All of Us Research Hub的数据,该方法也取得了良好的效果,表明其在实际应用中具有潜力。具体的性能数据和提升幅度在摘要中未明确给出,属于未知信息。
🎯 应用场景
该研究成果可广泛应用于流行病学、药物研发和精准医疗等领域。通过更准确地估计基因对疾病的因果效应,可以帮助识别潜在的药物靶点,评估药物的疗效,并为个体化治疗方案的制定提供依据。此外,该方法还可以用于研究环境因素对健康的影响,为公共卫生政策的制定提供科学依据。
📄 摘要(原文)
Mendelian Randomization (MR) is a prominent observational epidemiological research method designed to address unobserved confounding when estimating causal effects. However, core assumptions -- particularly the independence between instruments and unobserved confounders -- are often violated due to population stratification or assortative mating. Leveraging the increasing availability of multi-environment data, we propose a representation learning framework that exploits cross-environment invariance to recover latent exogenous components of genetic instruments. We provide theoretical guarantees for identifying these latent instruments under various mixing mechanisms and demonstrate the effectiveness of our approach through simulations and semi-synthetic experiments using data from the All of Us Research Hub.