Enhancing Automatic Chord Recognition via Pseudo-Labeling and Knowledge Distillation
作者: Nghia Phan, Rong Jin, Gang Liu, Xiao Dong
分类: cs.SD, cs.IR, cs.LG, cs.MM
发布日期: 2026-02-23
备注: 9 pages, 6 figures, 3 tables
💡 一句话要点
提出基于伪标签和知识蒸馏的自动和弦识别增强方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自动和弦识别 伪标签 知识蒸馏 预训练模型 音乐信息检索
📋 核心要点
- 自动和弦识别面临标注数据稀缺的挑战,高质量标注成本高昂,限制了模型性能。
- 利用预训练模型生成伪标签,并结合知识蒸馏,实现对未标注数据的有效利用和模型性能提升。
- 实验表明,该方法显著提升了自动和弦识别的准确率,尤其是在罕见和弦的识别上。
📝 摘要(中文)
自动和弦识别(ACR)受限于对齐的和弦标签的稀缺性,因为良好对齐的标注获取成本很高。同时,开放权重的预训练模型目前比其专有的训练数据更容易获得。本文提出了一种两阶段训练流程,该流程利用预训练模型和未标记的音频。所提出的方法将训练解耦为两个阶段。在第一阶段,我们使用预训练的BTC模型作为教师,为超过1000小时的各种未标记音频生成伪标签,并仅在这些伪标签上训练学生模型。在第二阶段,当真实标签可用时,学生会持续在真实标签上进行训练,并应用来自教师的选择性知识蒸馏(KD)作为正则化器,以防止第一阶段学习到的表示的灾难性遗忘。在我们的实验中,两个模型(BTC, 2E1D)被用作学生。在第一阶段,仅使用伪标签,BTC学生模型实现了教师模型98%以上的性能,而2E1D模型在七个标准mir_eval指标上实现了约96%的性能。在第二阶段对两个学生模型进行单次训练后,最终的BTC学生模型在所有指标上的平均表现超过了传统的监督学习基线2.5%,超过了原始预训练教师模型1.55%。而最终的2E1D学生模型比传统的监督学习基线平均提高了3.79%,并且几乎达到了与教师相同的性能。两种情况都显示了在罕见和弦质量上的巨大收益。
🔬 方法详解
问题定义:自动和弦识别(ACR)任务旨在从音频信号中自动识别和弦序列。现有的方法主要依赖于有监督学习,但高质量、对齐的和弦标注数据获取成本高昂,限制了模型的泛化能力,尤其是在罕见和弦的识别上。
核心思路:该论文的核心思路是利用预训练模型作为教师模型,从未标注的音频数据中生成伪标签,并使用这些伪标签训练学生模型。然后,在有真实标签的数据上进行微调,并使用知识蒸馏技术,将教师模型的知识迁移到学生模型,防止灾难性遗忘。
技术框架:该方法采用两阶段训练框架。第一阶段,使用预训练的BTC模型作为教师模型,对大量未标注音频数据生成伪标签,并使用这些伪标签训练学生模型。第二阶段,在少量真实标注数据上,对学生模型进行微调,并使用知识蒸馏技术,从教师模型中提取知识,防止学生模型在微调过程中忘记第一阶段学习到的知识。
关键创新:该方法的主要创新在于结合了伪标签和知识蒸馏技术,有效地利用了未标注数据,提升了自动和弦识别的性能。与传统的监督学习方法相比,该方法能够更好地利用大规模未标注数据,提高模型的泛化能力。与直接使用预训练模型相比,该方法通过知识蒸馏,可以将预训练模型的知识迁移到更小的学生模型中,降低计算成本。
关键设计:在第一阶段,使用预训练的BTC模型生成伪标签。在第二阶段,使用选择性知识蒸馏,即只蒸馏教师模型中与当前真实标签相关的知识,避免引入噪声。损失函数包括交叉熵损失和知识蒸馏损失。学生模型可以选择不同的网络结构,例如BTC或2E1D。
🖼️ 关键图片
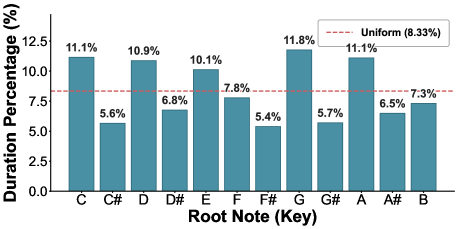
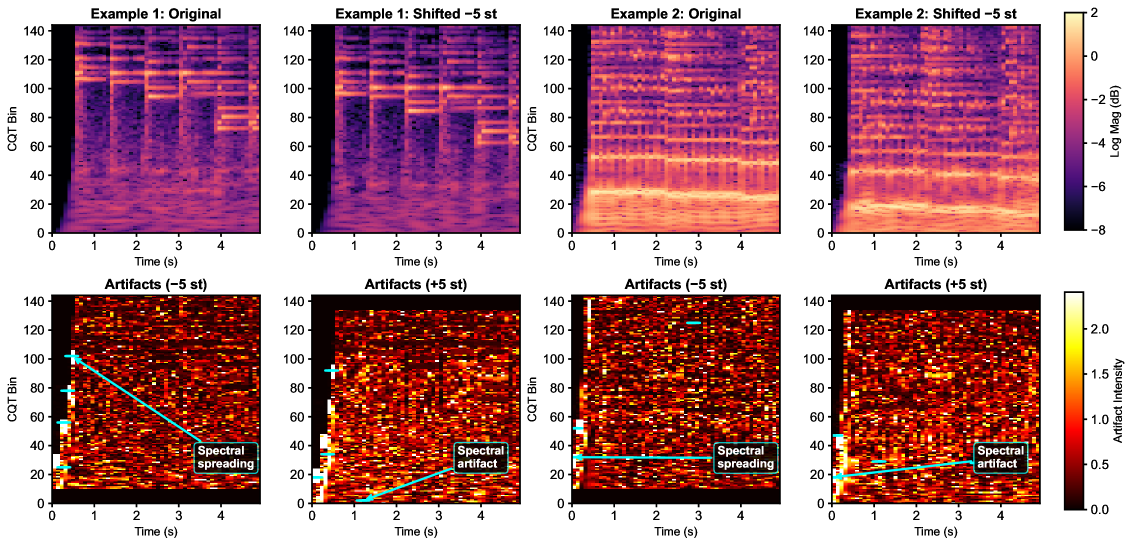
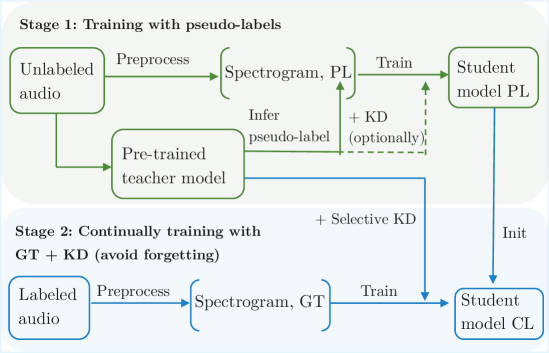
📊 实验亮点
实验结果表明,该方法显著提升了自动和弦识别的准确率。使用BTC作为学生模型时,相比传统的监督学习基线提升了2.5%,相比原始预训练教师模型提升了1.55%。使用2E1D作为学生模型时,相比传统的监督学习基线提升了3.79%,并且几乎达到了与教师模型相同的性能。尤其是在罕见和弦的识别上,提升幅度更为显著。
🎯 应用场景
该研究成果可应用于音乐信息检索、音乐教育、自动伴奏生成等领域。通过提升自动和弦识别的准确率,可以为音乐分析、创作和学习提供更强大的工具。未来,该方法可以扩展到其他音乐相关的任务中,例如自动音乐转录、音乐风格识别等。
📄 摘要(原文)
Automatic Chord Recognition (ACR) is constrained by the scarcity of aligned chord labels, as well-aligned annotations are costly to acquire. At the same time, open-weight pre-trained models are currently more accessible than their proprietary training data. In this work, we present a two-stage training pipeline that leverages pre-trained models together with unlabeled audio. The proposed method decouples training into two stages. In the first stage, we use a pre-trained BTC model as a teacher to generate pseudo-labels for over 1,000 hours of diverse unlabeled audio and train a student model solely on these pseudo-labels. In the second stage, the student is continually trained on ground-truth labels as they become available, with selective knowledge distillation (KD) from the teacher applied as a regularizer to prevent catastrophic forgetting of the representations learned in the first stage. In our experiments, two models (BTC, 2E1D) were used as students. In stage 1, using only pseudo-labels, the BTC student achieves over 98% of the teacher's performance, while the 2E1D model achieves about 96% across seven standard mir_eval metrics. After a single training run for both students in stage 2, the resulting BTC student model surpasses the traditional supervised learning baseline by 2.5% and the original pre-trained teacher model by 1.55% on average across all metrics. And the resulting 2E1D student model improves from the traditional supervised learning baseline by 3.79% on average and achieves almost the same performance as the teacher. Both cases show the large gains on rare chord qualities.