Compositional Planning with Jumpy World Models
作者: Jesse Farebrother, Matteo Pirotta, Andrea Tirinzoni, Marc G. Bellemare, Alessandro Lazaric, Ahmed Touati
分类: cs.LG, cs.AI, stat.ML
发布日期: 2026-02-23
💡 一句话要点
提出基于Jumpy World Models的组合规划方法,提升长时序任务零样本性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 组合规划 世界模型 时间抽象 多步预测 强化学习
📋 核心要点
- 现有方法在长时序预测中存在累积误差,难以准确估计策略序列的状态访问分布,阻碍了组合规划的有效性。
- 提出Jumpy World Models,通过学习多步动态预测模型,捕获预训练策略在多时间尺度上的状态占用,从而解决长时序预测问题。
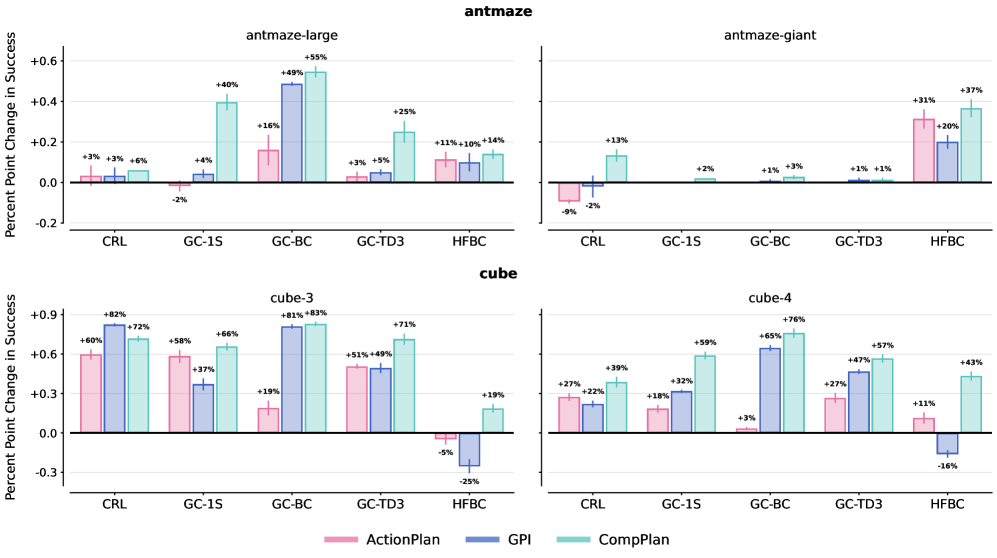
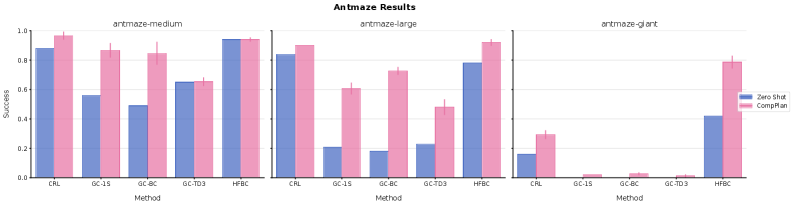
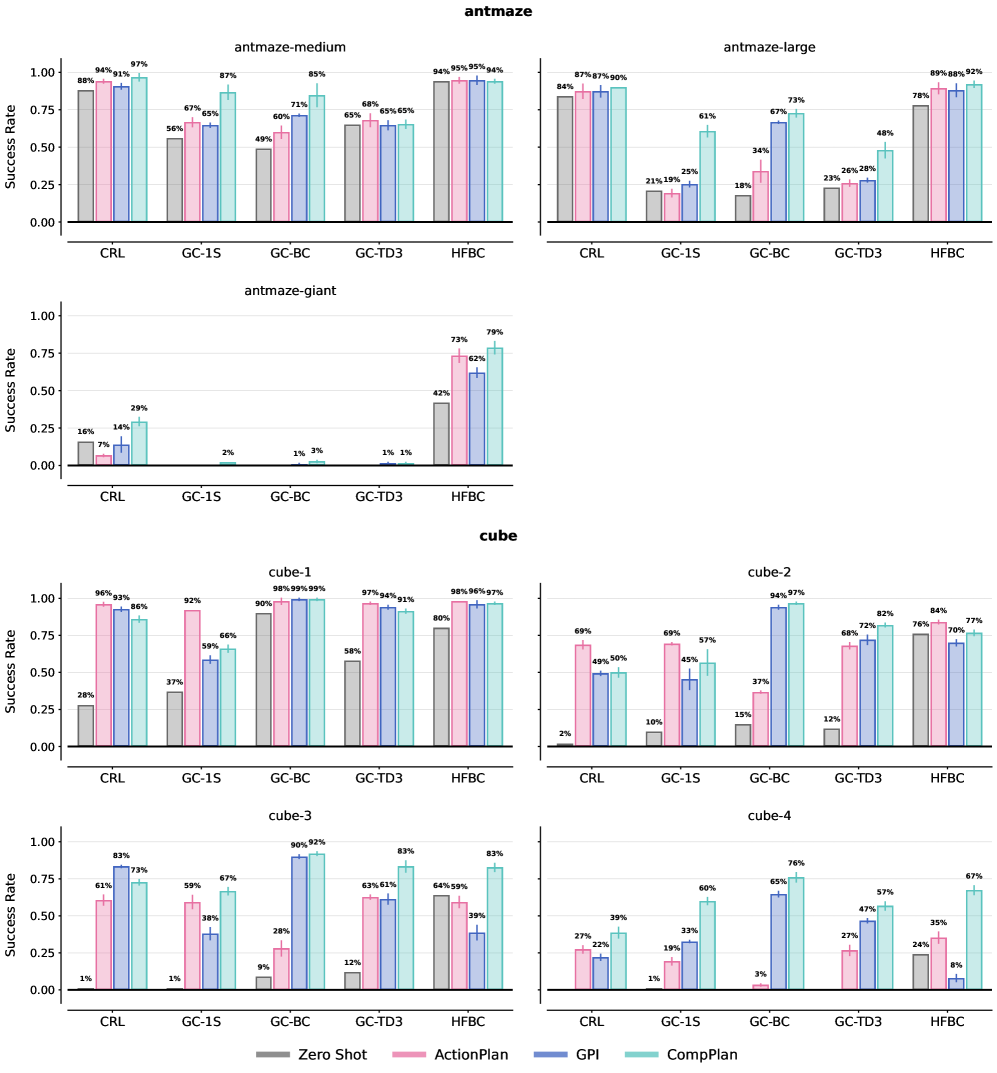
- 实验表明,在操作和导航任务中,使用Jumpy World Models的组合规划显著提升了零样本性能,相比原始动作规划平均提升200%。
📝 摘要(中文)
本文研究了智能决策中利用时间抽象进行规划的能力。不同于基于原始动作的推理,本文研究的智能体将预训练策略组合为时间扩展动作,从而解决单个策略无法完成的复杂任务。组合规划面临的挑战是长时序预测中的累积误差,难以估计策略序列引起的访问分布。受几何策略组合框架的启发,本文通过学习多步动态预测模型(即Jumpy World Models)来解决这些挑战,该模型以离线方式捕获预训练策略在多个时间尺度上引起的状态占用。在Temporal Difference Flows的基础上,本文通过一种新颖的一致性目标来增强这些模型,该目标对齐跨时间尺度的预测,从而提高长时序预测的准确性。进一步展示了如何结合这些生成式预测来估计在不同时间尺度上执行任意策略序列的价值。实验结果表明,在具有挑战性的操作和导航任务中,使用Jumpy World Models进行组合规划显著提高了各种基础策略的零样本性能,在长时序任务上,相对于使用原始动作进行规划,平均提高了200%。
🔬 方法详解
问题定义:论文旨在解决在复杂任务中,智能体如何有效地利用预训练的策略(或技能)进行组合规划的问题。现有方法,特别是基于原始动作的规划,在长时序任务中面临着累积误差的问题,导致难以准确预测状态的访问分布,从而限制了规划的有效性。这种痛点在于无法充分利用已有的知识(预训练策略),需要从头开始学习,效率低下。
核心思路:论文的核心思路是学习一个能够预测在不同时间尺度上,执行预训练策略后状态变化的模型,即Jumpy World Models。通过直接预测多步动态,减少了累积误差,使得智能体能够更好地理解策略组合后的长期影响。这样设计的目的是为了让智能体能够像搭积木一样,利用已有的技能快速构建复杂的行为。
技术框架:整体框架包含以下几个主要模块:1) 预训练策略库:包含一系列预先训练好的策略,作为组合规划的基础。2) Jumpy World Model:学习在不同时间尺度上,执行预训练策略后的状态转移概率。3) 一致性目标:用于对齐不同时间尺度上的预测,提高长时序预测的准确性。4) 规划器:利用Jumpy World Model预测的结果,评估不同策略序列的价值,并选择最优的策略组合。
关键创新:最重要的技术创新点在于Jumpy World Models的学习方式。与传统的World Models不同,Jumpy World Models直接预测多步动态,而不是单步动态。此外,论文还提出了一个新颖的一致性目标,用于对齐不同时间尺度上的预测。这种方法能够有效地减少累积误差,提高长时序预测的准确性。与现有方法的本质区别在于,Jumpy World Models能够更好地利用预训练策略的知识,从而实现更高效的组合规划。
关键设计:论文使用了Temporal Difference Flows作为Jumpy World Models的基础架构,并在此基础上添加了一致性目标。一致性目标通过最小化不同时间尺度预测之间的差异来实现,例如,预测执行策略A一步后的状态,与预测执行策略A两步后,再执行策略B一步后的状态,应该在某种程度上保持一致。具体的损失函数设计和网络结构细节在论文中有详细描述,但此处未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在具有挑战性的操作和导航任务中,使用Jumpy World Models进行组合规划显著提高了各种基础策略的零样本性能。在长时序任务上,相对于使用原始动作进行规划,平均提高了200%。这表明Jumpy World Models能够有效地利用预训练策略的知识,从而实现更高效的组合规划。
🎯 应用场景
该研究成果可应用于机器人操作、自动驾驶、游戏AI等领域。通过组合预训练的技能,机器人可以更快地学会执行复杂的任务,例如装配产品、导航复杂环境等。在自动驾驶领域,可以利用该方法组合不同的驾驶策略,提高车辆在复杂交通环境中的安全性。该研究的实际价值在于降低了学习复杂任务的成本,提高了智能体的适应性和泛化能力。未来,该方法有望推动人工智能在更多领域的应用。
📄 摘要(原文)
The ability to plan with temporal abstractions is central to intelligent decision-making. Rather than reasoning over primitive actions, we study agents that compose pre-trained policies as temporally extended actions, enabling solutions to complex tasks that no constituent alone can solve. Such compositional planning remains elusive as compounding errors in long-horizon predictions make it challenging to estimate the visitation distribution induced by sequencing policies. Motivated by the geometric policy composition framework introduced in arXiv:2206.08736, we address these challenges by learning predictive models of multi-step dynamics -- so-called jumpy world models -- that capture state occupancies induced by pre-trained policies across multiple timescales in an off-policy manner. Building on Temporal Difference Flows (arXiv:2503.09817), we enhance these models with a novel consistency objective that aligns predictions across timescales, improving long-horizon predictive accuracy. We further demonstrate how to combine these generative predictions to estimate the value of executing arbitrary sequences of policies over varying timescales. Empirically, we find that compositional planning with jumpy world models significantly improves zero-shot performance across a wide range of base policies on challenging manipulation and navigation tasks, yielding, on average, a 200% relative improvement over planning with primitive actions on long-horizon tasks.