Advantage-based Temporal Attack in Reinforcement Learning
作者: Shenghong He
分类: cs.LG
发布日期: 2026-02-23
💡 一句话要点
提出基于优势函数的时序对抗Transformer,提升强化学习模型的鲁棒性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 对抗攻击 深度强化学习 时序相关性 Transformer 优势函数
📋 核心要点
- 现有基于奖励的对抗攻击方法难以捕捉时间步之间的依赖关系,导致扰动时序相关性弱。
- AAT利用多尺度因果自注意力和加权优势机制,增强扰动的时序相关性,提升攻击性能。
- 实验表明,AAT在Atari、DeepMind Control Suite和Google足球等任务上优于主流基线。
📝 摘要(中文)
深度强化学习(DRL)模型容易受到对抗样本的攻击,这些对抗样本会误导智能体采取次优或不安全的行为。现有方法通过利用未来奖励来指导序列时间步上的对抗扰动生成(即,基于奖励的攻击),从而提高攻击有效性。然而,这些方法无法捕捉扰动生成过程中不同时间步之间的依赖关系,导致当前扰动和先前扰动之间的时序相关性较弱。本文提出了一种名为基于优势函数的对抗Transformer(AAT)的新方法,它可以生成具有更强时序相关性的对抗样本(即,时间相关的对抗样本),从而提高攻击性能。AAT采用多尺度因果自注意力(MSCSA)机制来动态捕捉来自不同时间段的历史信息与当前状态之间的依赖关系,从而增强当前扰动与先前扰动之间的相关性。此外,AAT引入了一种加权优势机制,该机制量化了扰动在给定状态下的有效性,并通过采样高优势区域来指导生成过程,从而生成高性能的对抗样本。大量实验表明,AAT的性能与Atari、DeepMind Control Suite和Google足球任务上的主流对抗攻击基线相匹配或超过它们。
🔬 方法详解
问题定义:论文旨在解决深度强化学习模型在面对对抗样本攻击时鲁棒性不足的问题。现有的基于奖励的对抗攻击方法,虽然利用未来奖励指导扰动生成,但忽略了时间步之间的依赖关系,导致生成的对抗扰动在时间上缺乏连贯性,攻击效果受限。
核心思路:论文的核心思路是通过引入Transformer结构,特别是多尺度因果自注意力机制,来建模对抗扰动在时间上的依赖关系。同时,利用优势函数来指导扰动的生成,使得扰动更有效地影响智能体的决策。这样设计的目的是为了生成更具时序相关性的对抗样本,从而更有效地攻击强化学习模型。
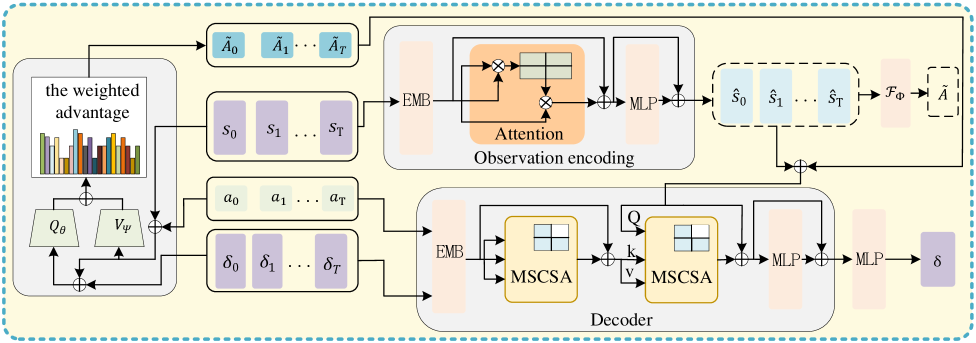
技术框架:AAT的整体框架包含以下几个主要模块:1) 状态编码器:将当前状态编码成向量表示。2) 多尺度因果自注意力(MSCSA)模块:利用历史状态信息和当前状态信息,动态捕捉不同时间段之间的依赖关系,生成具有时序相关性的扰动。3) 加权优势机制:根据优势函数的值,对扰动进行加权,引导扰动生成过程朝着高优势区域进行。4) 扰动生成器:根据MSCSA模块和加权优势机制的输出,生成最终的对抗扰动。
关键创新:AAT的关键创新在于以下两点:1) 提出了多尺度因果自注意力(MSCSA)机制,能够有效地捕捉对抗扰动在时间上的依赖关系,生成具有更强时序相关性的对抗样本。2) 引入了加权优势机制,能够量化扰动在给定状态下的有效性,并引导扰动生成过程朝着高优势区域进行,从而提高攻击性能。与现有方法相比,AAT能够更好地建模对抗扰动在时间上的依赖关系,并更有效地利用优势函数来指导扰动生成。
关键设计:MSCSA模块采用了多头注意力机制,每个头关注不同时间尺度的历史信息。因果性保证了当前时刻的扰动只依赖于过去的信息,避免了信息泄露。加权优势机制使用优势函数的指数形式作为权重,鼓励探索高优势区域。损失函数通常包括对抗损失和正则化项,对抗损失用于最大化攻击效果,正则化项用于约束扰动的大小。
🖼️ 关键图片
📊 实验亮点
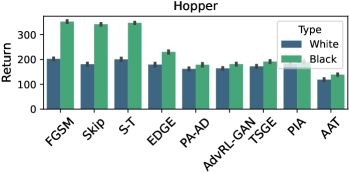
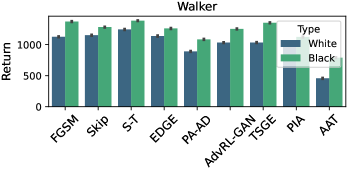
实验结果表明,AAT在Atari游戏中能够显著降低智能体的平均奖励,在DeepMind Control Suite和Google足球任务中也取得了与主流对抗攻击基线相当或更好的性能。例如,在某些Atari游戏中,AAT可以将智能体的平均奖励降低到接近于0的水平,表明其具有很强的攻击能力。
🎯 应用场景
该研究成果可应用于提升强化学习系统的安全性,例如在自动驾驶、机器人控制等安全攸关领域,通过评估和增强模型对对抗攻击的鲁棒性,降低系统发生意外的风险。此外,该方法也可用于评估和改进其他类型的序列决策系统。
📄 摘要(原文)
Extensive research demonstrates that Deep Reinforcement Learning (DRL) models are susceptible to adversarially constructed inputs (i.e., adversarial examples), which can mislead the agent to take suboptimal or unsafe actions. Recent methods improve attack effectiveness by leveraging future rewards to guide adversarial perturbation generation over sequential time steps (i.e., reward-based attacks). However, these methods are unable to capture dependencies between different time steps in the perturbation generation process, resulting in a weak temporal correlation between the current perturbation and previous perturbations.In this paper, we propose a novel method called Advantage-based Adversarial Transformer (AAT), which can generate adversarial examples with stronger temporal correlations (i.e., time-correlated adversarial examples) to improve the attack performance. AAT employs a multi-scale causal self-attention (MSCSA) mechanism to dynamically capture dependencies between historical information from different time periods and the current state, thus enhancing the correlation between the current perturbation and the previous perturbation. Moreover, AAT introduces a weighted advantage mechanism, which quantifies the effectiveness of a perturbation in a given state and guides the generation process toward high-performance adversarial examples by sampling high-advantage regions. Extensive experiments demonstrate that the performance of AAT matches or surpasses mainstream adversarial attack baselines on Atari, DeepMind Control Suite and Google football tasks.