LLMs Can Learn to Reason Via Off-Policy RL
作者: Daniel Ritter, Owen Oertell, Bradley Guo, Jonathan Chang, Kianté Brantley, Wen Sun
分类: cs.LG
发布日期: 2026-02-22
💡 一句话要点
提出OAPL算法,解决LLM离策略强化学习中训练与推理策略差异问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 强化学习 离策略学习 策略优化 优势函数
📋 核心要点
- 现有LLM强化学习方法受限于在线算法,难以处理分布式训练和推理策略差异导致的离策略数据。
- 论文提出OAPL算法,直接利用离策略数据进行训练,无需修改推理引擎或进行重要性采样。
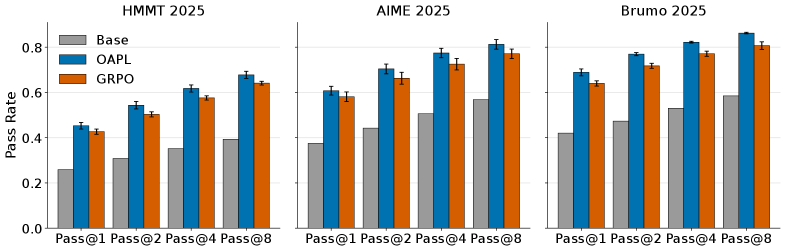
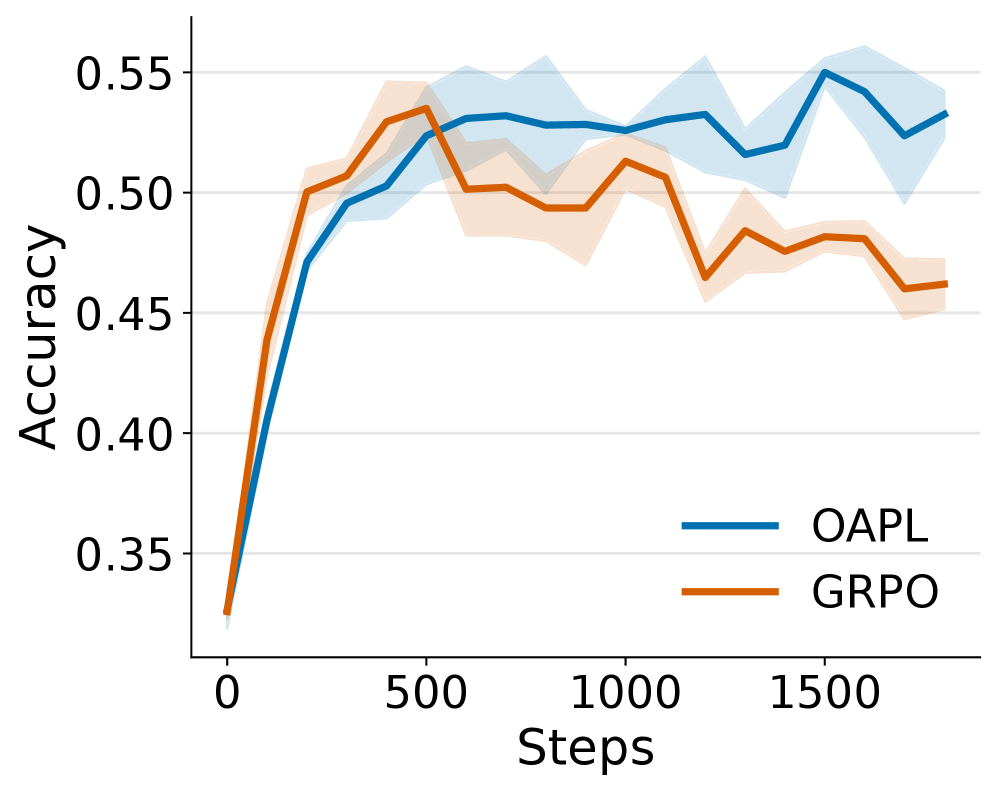
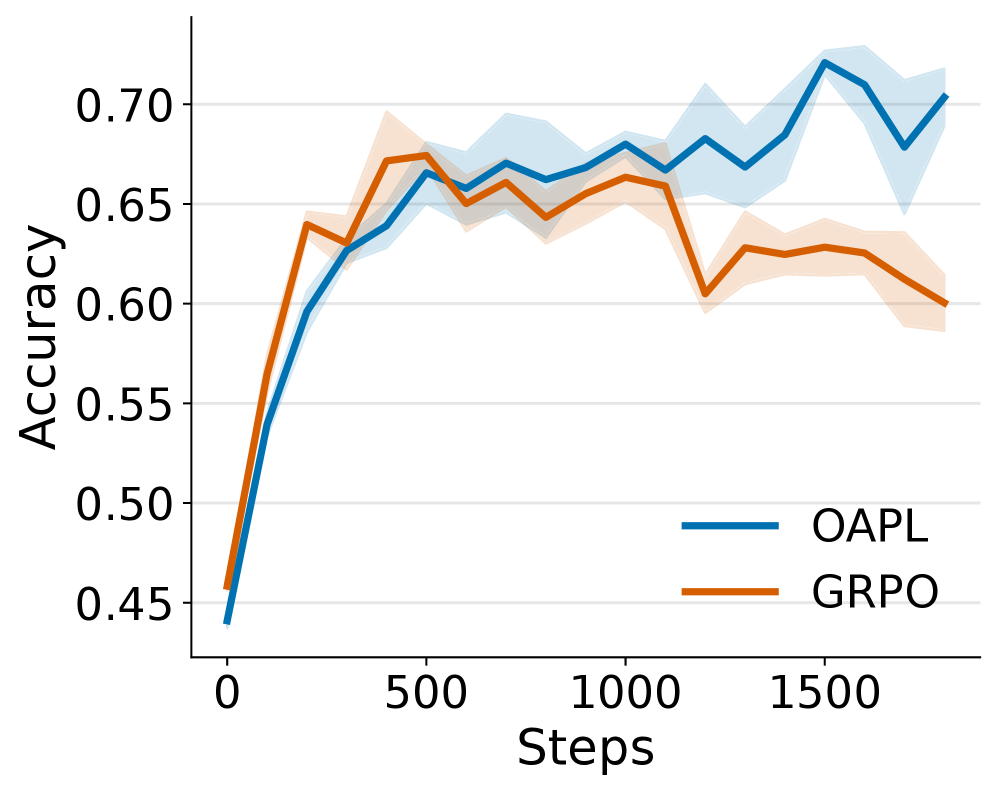
- 实验表明,OAPL在数学和代码生成任务上优于现有方法,且具有更好的测试时扩展性。
📝 摘要(中文)
大型语言模型(LLM)的强化学习(RL)方法通常使用PPO或GRPO等在线算法。然而,分布式训练架构带来的策略滞后以及训练和推理策略之间的差异,使得数据本质上是离策略的。以往工作试图通过重要性采样(IS)或通过显式修改推理引擎来更紧密地对齐训练和推理策略,使离策略数据看起来更像在线数据。本文提出了一种新的离策略RL算法,即具有滞后推理策略的最优优势策略优化(OAPL),无需这些修改。实验表明,在竞赛数学基准测试中,OAPL优于使用重要性采样的GRPO,并且在LiveCodeBench上,使用比训练期间少3倍的生成量,可以与公开可用的编码模型DeepCoder的性能相匹配。此外,经验表明,通过OAPL训练的模型在Pass@k指标下具有改进的测试时缩放性能。即使训练和推理策略之间存在超过400个梯度步长的滞后,OAPL也能实现高效、有效的后训练,比以前的方法离策略程度高100倍。
🔬 方法详解
问题定义:现有LLM强化学习方法,如PPO和GRPO,假设训练数据是on-policy的。然而,由于分布式训练架构中的策略滞后以及训练和推理策略之间的差异,实际数据往往是off-policy的。现有方法试图通过重要性采样或修改推理引擎来缓解这个问题,但这些方法存在局限性,例如重要性采样的方差问题和修改推理引擎的复杂性。
核心思路:论文的核心思路是直接利用off-policy数据进行强化学习,而不是试图使其看起来像on-policy数据。通过设计一种新的off-policy RL算法,OAPL,可以有效地利用这些数据,而无需对推理引擎进行修改或进行重要性采样。
技术框架:OAPL算法基于优势函数,并结合了滞后推理策略。整体流程包括:1)使用滞后的推理策略生成数据;2)使用这些off-policy数据训练策略;3)重复上述步骤。该算法的关键在于如何利用优势函数来优化策略,同时考虑到off-policy数据的特性。
关键创新:OAPL的关键创新在于其off-policy的特性,它允许算法在训练和推理策略存在显著差异的情况下进行有效训练。与现有方法相比,OAPL不需要对推理引擎进行修改,也不需要进行重要性采样,从而简化了训练流程并提高了效率。
关键设计:OAPL的关键设计包括:1)使用最优优势函数来指导策略更新;2)考虑滞后推理策略的影响,从而更好地利用off-policy数据;3)通过实验验证算法的有效性,并与其他方法进行比较。具体的参数设置和损失函数细节在论文中有详细描述,但此处未给出。
🖼️ 关键图片
📊 实验亮点
实验结果表明,OAPL在竞争性数学基准测试中优于使用重要性采样的GRPO。在LiveCodeBench上,OAPL使用比DeepCoder少3倍的生成量,达到了与其相当的性能。此外,OAPL训练的模型在Pass@k指标下表现出更好的测试时扩展性。OAPL能够有效处理训练和推理策略之间超过400个梯度步长的滞后,比以前的方法离策略程度高100倍。
🎯 应用场景
该研究成果可应用于各种需要利用LLM进行决策和生成任务的场景,例如代码生成、数学问题求解、对话系统等。通过OAPL算法,可以更有效地利用现有的数据资源,提高LLM的性能和效率,并降低训练成本。此外,该算法的off-policy特性使其更适用于分布式训练环境,有望推动LLM在更大规模和更复杂任务上的应用。
📄 摘要(原文)
Reinforcement learning (RL) approaches for Large Language Models (LLMs) frequently use on-policy algorithms, such as PPO or GRPO. However, policy lag from distributed training architectures and differences between the training and inference policies break this assumption, making the data off-policy by design. To rectify this, prior work has focused on making this off-policy data appear more on-policy, either via importance sampling (IS), or by more closely aligning the training and inference policies by explicitly modifying the inference engine. In this work, we embrace off-policyness and propose a novel off-policy RL algorithm that does not require these modifications: Optimal Advantage-based Policy Optimization with Lagged Inference policy (OAPL). We show that OAPL outperforms GRPO with importance sampling on competition math benchmarks, and can match the performance of a publicly available coding model, DeepCoder, on LiveCodeBench, while using 3x fewer generations during training. We further empirically demonstrate that models trained via OAPL have improved test time scaling under the Pass@k metric. OAPL allows for efficient, effective post-training even with lags of more than 400 gradient steps between the training and inference policies, 100x more off-policy than prior approaches.