Attention Deficits in Language Models: Causal Explanations for Procedural Hallucinations
作者: Ahmed Karim, Fatima Sheaib, Zein Khamis, Maggie Chlon, Jad Awada, Leon Chlon
分类: stat.ML, cs.LG
发布日期: 2026-02-22
💡 一句话要点
揭示语言模型程序性幻觉:注意力缺陷导致推理后结果遗忘
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 程序性幻觉 注意力机制 长上下文 语言模型 信息论 线性探针 绑定任务
📋 核心要点
- 现有大型语言模型在程序执行的最后阶段,即报告计算结果时,经常出现“程序性幻觉”问题,无法正确输出。
- 该研究的核心在于分析模型在长上下文绑定任务中出现的错误,并将其归因于读取阶段的路由失败,特别是Stage 2B(绑定)错误。
- 实验结果表明,即使模型内部编码了正确答案,也可能因为注意力机制的缺陷而无法正确使用,通过干预可以显著改善这一问题。
📝 摘要(中文)
大型语言模型在执行复杂程序时表现出色,但经常在看似简单的最后一步(报告之前计算的值)上失败。本文将此现象研究为“程序性幻觉”,即模型未能执行可验证的、基于提示的规范,即使上下文中存在正确的值。在具有已知单token候选集的长上下文绑定任务中,发现许多错误是读取阶段的路由失败,分解为Stage 2A(门控)错误(模型未进入答案模式)和Stage 2B(绑定)错误(进入答案模式但选择了错误的候选,通常是由于近因偏差)。在困难情况下,Stage 2B错误是模型家族在任务中的主要错误来源。在Stage 2B错误试验中,最终层残差流上的线性探针能够远高于偶然概率地恢复正确值,表明答案已被编码但未使用。通过可用与已用互信息和伪先验干预来形式化“存在但未使用”的概念,从而产生输出可计算的诊断和信息预算证书。最后,一种预言机检查点干预,在查询附近重述真实绑定,几乎可以消除长距离的Stage 2B失败。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在执行程序性任务时出现的“程序性幻觉”问题,即模型在上下文中已经计算出正确答案,但最终无法正确输出。现有方法未能充分解释这种现象背后的原因,以及如何有效缓解。
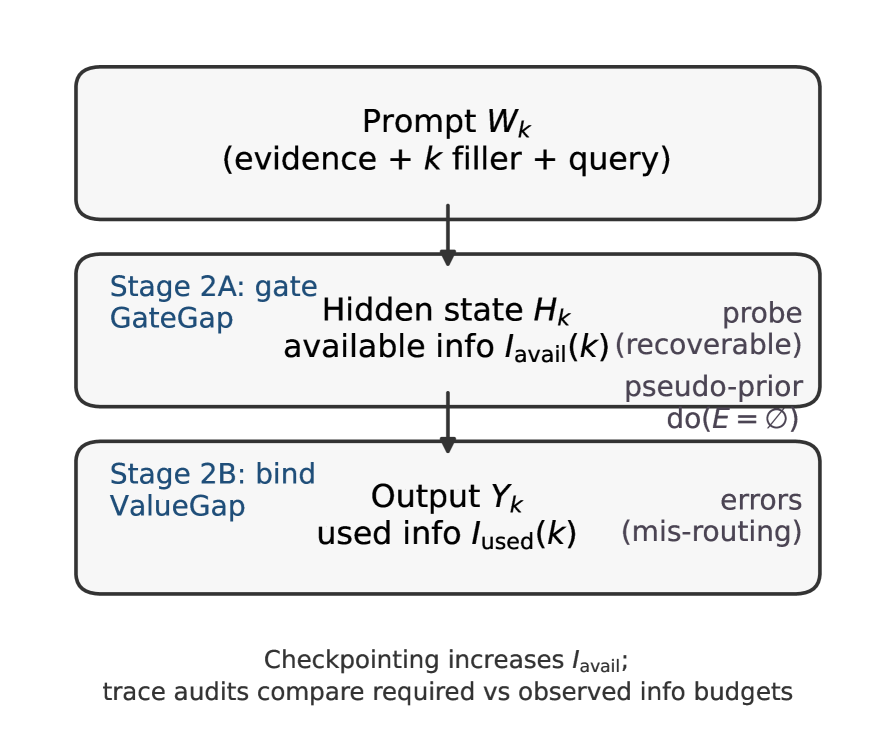
核心思路:论文的核心思路是将程序性幻觉归因于模型在读取阶段的注意力缺陷,特别是Stage 2B(绑定)错误,即模型虽然进入了答案模式,但由于注意力机制的偏差(如近因偏差),选择了错误的候选答案。通过分析模型内部状态,揭示答案“存在但未使用”的现象。
技术框架:论文的技术框架主要包括以下几个阶段: 1. 任务设计:设计长上下文绑定任务,其中模型需要根据上下文执行一系列操作,并最终报告一个特定的值。 2. 错误分解:将错误分解为Stage 2A(门控)错误和Stage 2B(绑定)错误,分别对应模型未进入答案模式和选择了错误答案的情况。 3. 内部状态分析:使用线性探针分析最终层残差流,以确定模型是否编码了正确答案。 4. 信息论分析:使用可用与已用互信息和伪先验干预来量化答案的可用性和使用情况。 5. 干预实验:通过预言机检查点干预,在查询附近重述真实绑定,以验证注意力机制对结果的影响。
关键创新:论文最重要的技术创新点在于: 1. 将程序性幻觉归因于读取阶段的注意力缺陷,特别是Stage 2B(绑定)错误。 2. 提出了“存在但未使用”的概念,并使用信息论方法对其进行量化分析。 3. 通过预言机检查点干预,验证了注意力机制对结果的影响,并提供了一种缓解程序性幻觉的方法。
关键设计:论文的关键设计包括: 1. 长上下文绑定任务的设计,确保模型需要在长距离依赖关系中找到正确答案。 2. 线性探针的设计,用于从模型内部状态中提取信息。 3. 预言机检查点干预的设计,用于验证注意力机制对结果的影响。 4. 使用Qwen2.5-3B等模型进行实验,并分析其在不同任务上的表现。
🖼️ 关键图片
📊 实验亮点
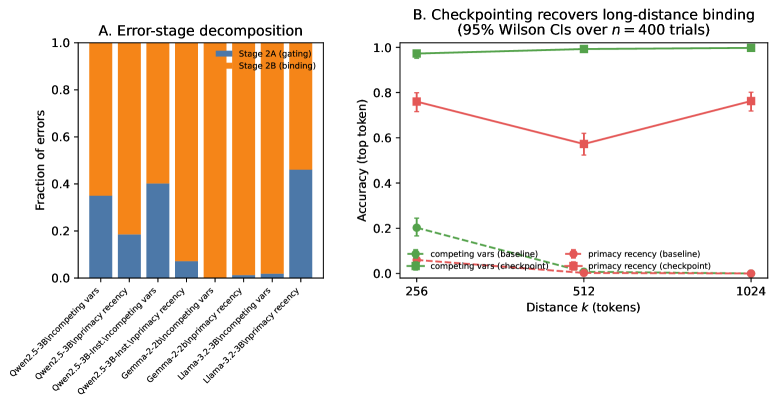
实验结果表明,在Stage 2B错误试验中,最终层残差流上的线性探针能够远高于偶然概率地恢复正确值(例如,在Qwen2.5-3B上为74% vs. 2%),表明答案已被编码但未使用。通过预言机检查点干预,可以在长距离上显著减少Stage 2B失败(例如,Qwen2.5-3B在k=1024时从0/400提升到399/400)。
🎯 应用场景
该研究成果可应用于提升大型语言模型在需要精确推理和记忆的任务中的性能,例如问答系统、代码生成、知识库查询等。通过改善模型的注意力机制,可以减少程序性幻觉,提高模型输出的可靠性和准确性,从而增强用户信任。
📄 摘要(原文)
Large language models can follow complex procedures yet fail at a seemingly trivial final step: reporting a value they themselves computed moments earlier. We study this phenomenon as \emph{procedural hallucination}: failure to execute a verifiable, prompt-grounded specification even when the correct value is present in context. In long-context binding tasks with a known single-token candidate set, we find that many errors are readout-stage routing failures. Specifically, failures decompose into Stage~2A (gating) errors, where the model does not enter answer mode, and Stage~2B (binding) errors, where it enters answer mode but selects the wrong candidate (often due to recency bias). In the hard regime, Stage~2B accounts for most errors across model families in our tasks (Table~1). On Stage~2B error trials, a linear probe on the final-layer residual stream recovers the correct value far above chance (e.g., 74\% vs.\ 2\% on Qwen2.5-3B; Table~2), indicating that the answer is encoded but not used. We formalize ``present but not used'' via available vs.\ used mutual information and pseudo-prior interventions, yielding output-computable diagnostics and information-budget certificates. Finally, an oracle checkpointing intervention that restates the true binding near the query can nearly eliminate Stage~2B failures at long distance (e.g., Qwen2.5-3B $0/400 \rightarrow 399/400$ at $k = 1024$; Table~8).